 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOLAR: Learning Multimodal Molecular Representations from Noisy Labels
Jun 16, 2026Motivation: Noisy labels are a common challenge in molecular property prediction because molecular annotations are often obtained from assays, curated databases, or weak annotation pipelines rather than directly observed clean biological states. Treating recorded labels as reliable supervision can cause models to memorize corrupted observations and learn misleading molecular evidence. In multimodal molecular representation learning, this issue can be amplified by graph-text fusion or alignment, which may propagate label-induced errors across modalities. Results: We propose MOLAR, a noise-aware framework for learning multimodal molecular representations from noisy labels. MOLAR separates latent clean-property inference from recorded-label observation: graph and text views contribute residual evidence to a clean-property distribution, and a categorical label-observation channel maps this distribution to recorded labels for training. This formulation derives posterior label reliability and modality-specific molecular evidence from the model. Experiments on naturally noisy molecular benchmarks and controlled label-flipping benchmarks show that MOLAR consistently outperforms representative baselines. Visualization analyses further show that MOLAR provides interpretable reliability and modality-evidence diagnostics.
REFLECT: Intervention-Supported Error Attribution for Silent Failures in LLM Agent Traces
Jun 08, 2026Large language model (LLM) agents now solve complex tasks through long plan-and-execution traces, yet the ability to locate errors in a completed traces still lags far behind, especially in the \emph{silent failure} regime. Existing approaches predict suspect steps via classifiers or LLM judges, or recover correct answers via retry, but none feed the intervention outcome back to \emph{refine the attribution itself}. We propose \methodname, a method that closes this gap by diagnosing a candidate error step, testing it through controlled replay with a diagnosis-specific patch, and using the verified outcome flip as contrastive evidence to refine the final attribution. Across four localization benchmarks spanning multi-hop reasoning across domains, \methodname achieves the highest localization accuracy among same-auditor methods across all four benchmarks, with the largest gains on structured tool-use traces, while providing actionable localization even when ground-truth answers are unavailable.
Safe-Subspace Pseudo-Label Refinement for Source-Free Graph Domain Adaptation
May 30, 2026Source-free graph domain adaptation (SF-GDA) aims to adapt source-trained graph models to unlabeled target graphs when source graphs are no longer accessible. A central obstacle is pseudo-label reliability: under feature and topological shifts, source-induced predictions may become confidently wrong, and indiscriminate self-training can amplify systematic errors through graph message passing. This paper studies SF-GDA from a selective pseudo-labeling perspective. Instead of assuming globally bounded pseudo-label noise over the entire target domain, we identify a confidence-consistent safe subspace on which pseudo-label noise can be controlled under restricted posterior discrepancy, and derive a target-risk decomposition that separates safe-subspace fitting error, selected-label noise, and uncertain-set risk. Guided by this analysis, we propose SafeSubspace Pseudo-Label Refinement (S$^2$PLR), a source-free graph adaptation framework that applies hard pseudo-label supervision only to target graphs supported by both semantic and structural evidence. Specifically, S$^2$PLR estimates semantic reliability using source-committee confidence and disagreement, learns a targetintrinsic structural representation via graph contrastive learning, verifies pseudo-labels through neighborhood consistency, and exploits the remaining uncertain samples with noise-tolerant soft regularization rather than unreliable hard labels. Experiments on image and real-world graph benchmarks under different domain shifts demonstrate that S$^2$PLR achieves robust and competitive performance across diverse source-free transfer settings.
When Brain Networks Travel: Learning Beyond Site
May 07, 2026Graph-based learning on functional magnetic resonance imaging (fMRI) has shown strong potential for brain network analysis. However, existing methods degrade under cross-site out-of-distribution (OOD) settings because site-conditioned confounders induce non-pathological shortcuts, while functional connectivity constructed by temporal averaging obscures transient neurodynamics, limiting generalization to unseen sites. In this paper, we propose Cross-site OOD Robust brain nEtwork (CORE), a unified framework for brain network learning across unseen sites. CORE first performs site-aware confounder decoupling to mitigate site-conditioned bias and extract a cross-site population scaffold of reproducible diagnostic connectivity edges. It then profiles transient pathway dynamics over this scaffold using lightweight temporal descriptors and organizes scaffold edges into a line graph for transferable pathway-level modeling. Finally, CORE introduces a prior-guided subject-adaptive gating mechanism that leverages scaffold-derived population priors while preserving subject-specific connectivity variability. Extensive experiments under leave-one-site-out evaluation on real-world datasets (ABIDE, REST-meta-MDD, SRPBS, and ABCD) show that CORE consistently outperforms state-of-the-art baselines, with up to 6.7% relative gain. Furthermore, CORE remains robust to atlas variations, maintaining performance gains across different brain parcellation schemes.
TRACE: An Experiential Framework for Coherent Multi-hop Knowledge Graph Question Answering
Apr 13, 2026Multi-hop Knowledge Graph Question Answering (KGQA) requires coherent reasoning across relational paths, yet existing methods often treat each reasoning step independently and fail to effectively leverage experience from prior explorations, leading to fragmented reasoning and redundant exploration. To address these challenges, we propose Trajectoryaware Reasoning with Adaptive Context and Exploration priors (TRACE), an experiential framework that unifies LLM-driven contextual reasoning with exploration prior integration to enhance the coherence and robustness of multihop KGQA. Specifically, TRACE dynamically translates evolving reasoning paths into natural language narratives to maintain semantic continuity, while abstracting prior exploration trajectories into reusable experiential priors that capture recurring exploration patterns. A dualfeedback re-ranking mechanism further integrates contextual narratives with exploration priors to guide relation selection during reasoning. Extensive experiments on multiple KGQA benchmarks demonstrate that TRACE consistently outperforms state-of-the-art baselines.
DSBD: Dual-Aligned Structural Basis Distillation for Graph Domain Adaptation
Apr 03, 2026Graph domain adaptation (GDA) aims to transfer knowledge from a labeled source graph to an unlabeled target graph under distribution shifts. However, existing methods are largely feature-centric and overlook structural discrepancies, which become particularly detrimental under significant topology shifts. Such discrepancies alter both geometric relationships and spectral properties, leading to unreliable transfer of graph neural networks (GNNs). To address this limitation, we propose Dual-Aligned Structural Basis Distillation (DSBD) for GDA, a novel framework that explicitly models and adapts cross-domain structural variation. DSBD constructs a differentiable structural basis by synthesizing continuous probabilistic prototype graphs, enabling gradient-based optimization over graph topology. The basis is learned under source-domain supervision to preserve semantic discriminability, while being explicitly aligned to the target domain through a dual-alignment objective. Specifically, geometric consistency is enforced via permutation-invariant topological moment matching, and spectral consistency is achieved through Dirichlet energy calibration, jointly capturing structural characteristics across domains. Furthermore, we introduce a decoupled inference paradigm that mitigates source-specific structural bias by training a new GNN on the distilled structural basis. Extensive experiments on graph and image benchmarks demonstrate that DSBD consistently outperforms state-of-the-art methods.
USBD: Universal Structural Basis Distillation for Source-Free Graph Domain Adaptation
Feb 09, 2026SF-GDA is pivotal for privacy-preserving knowledge transfer across graph datasets. Although recent works incorporate structural information, they implicitly condition adaptation on the smoothness priors of sourcetrained GNNs, thereby limiting their generalization to structurally distinct targets. This dependency becomes a critical bottleneck under significant topological shifts, where the source model misinterprets distinct topological patterns unseen in the source domain as noise, rendering pseudo-label-based adaptation unreliable. To overcome this limitation, we propose the Universal Structural Basis Distillation, a framework that shifts the paradigm from adapting a biased model to learning a universal structural basis for SF-GDA. Instead of adapting a biased source model to a specific target, our core idea is to construct a structure-agnostic basis that proactively covers the full spectrum of potential topological patterns. Specifically, USBD employs a bi-level optimization framework to distill the source dataset into a compact structural basis. By enforcing the prototypes to span the full Dirichlet energy spectrum, the learned basis explicitly captures diverse topological motifs, ranging from low-frequency clusters to high-frequency chains, beyond those present in the source. This ensures that the learned basis creates a comprehensive structural covering capable of handling targets with disparate structures. For inference, we introduce a spectral-aware ensemble mechanism that dynamically activates the optimal prototype combination based on the spectral fingerprint of the target graph. Extensive experiments on benchmarks demonstrate that USBD significantly outperforms state-of-the-art methods, particularly in scenarios with severe structural shifts, while achieving superior computational efficiency by decoupling the adaptation cost from the target data scale.
Riemannian Flow Matching for Disentangled Graph Domain Adaptation
Jan 31, 2026Graph Domain Adaptation (GDA) typically uses adversarial learning to align graph embeddings in Euclidean space. However, this paradigm suffers from two critical challenges: Structural Degeneration, where hierarchical and semantic representations are entangled, and Optimization Instability, which arises from oscillatory dynamics of minimax adversarial training. To tackle these issues, we propose DisRFM, a geometry-aware GDA framework that unifies Riemannian embedding and flow-based transport. First, to overcome structural degeneration, we embed graphs into a Riemannian manifold. By adopting polar coordinates, we explicitly disentangle structure (radius) from semantics (angle). Then, we enforce topology preservation through radial Wasserstein alignment and semantic discrimination via angular clustering, thereby preventing feature entanglement and collapse. Second, we address the instability of adversarial alignment by using Riemannian flow matching. This method learns a smooth vector field to guide source features toward the target along geodesic paths, guaranteeing stable convergence. The geometric constraints further guide the flow to maintain the disentangled structure during transport. Theoretically, we prove the asymptotic stability of the flow matching and derive a tighter bound for the target risk. Extensive experiments demonstrate that DisRFM consistently outperforms state-of-the-art methods.
A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
Aug 10, 2025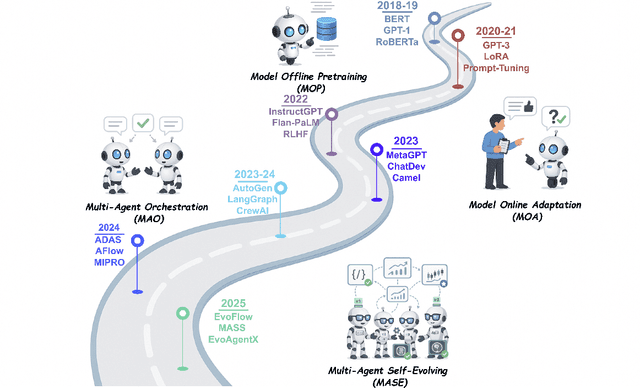
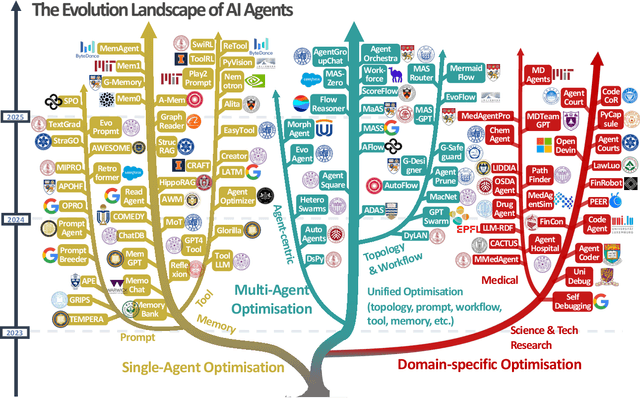
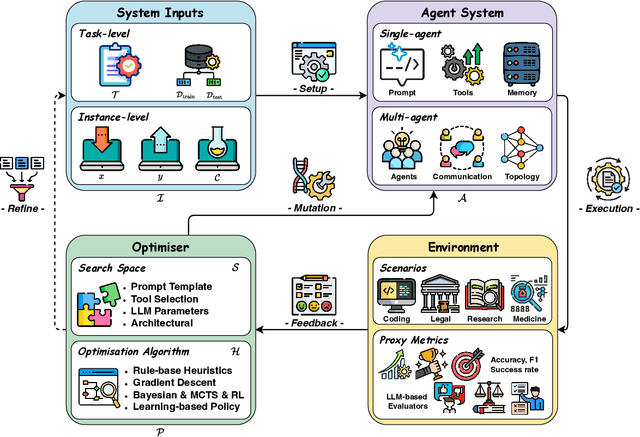
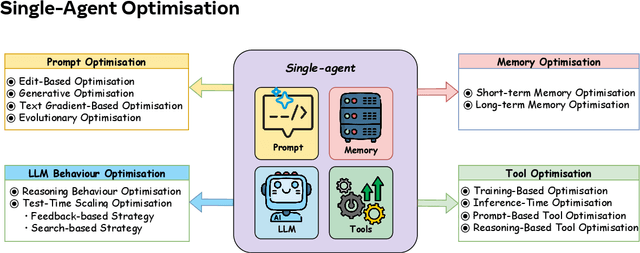
Recent advances in large language models have sparked growing interest in AI agents capable of solving complex, real-world tasks. However, most existing agent systems rely on manually crafted configurations that remain static after deployment, limiting their ability to adapt to dynamic and evolving environments. To this end, recent research has explored agent evolution techniques that aim to automatically enhance agent systems based on interaction data and environmental feedback. This emerging direction lays the foundation for self-evolving AI agents, which bridge the static capabilities of foundation models with the continuous adaptability required by lifelong agentic systems. In this survey, we provide a comprehensive review of existing techniques for self-evolving agentic systems. Specifically, we first introduce a unified conceptual framework that abstracts the feedback loop underlying the design of self-evolving agentic systems. The framework highlights four key components: System Inputs, Agent System, Environment, and Optimisers, serving as a foundation for understanding and comparing different strategies. Based on this framework, we systematically review a wide range of self-evolving techniques that target different components of the agent system. We also investigate domain-specific evolution strategies developed for specialised fields such as biomedicine, programming, and finance, where optimisation objectives are tightly coupled with domain constraints. In addition, we provide a dedicated discussion on the evaluation, safety, and ethical considerations for self-evolving agentic systems, which are critical to ensuring their effectiveness and reliability. This survey aims to provide researchers and practitioners with a systematic understanding of self-evolving AI agents, laying the foundation for the development of more adaptive, autonomous, and lifelong agentic systems.
Dynamically Adaptive Reasoning via LLM-Guided MCTS for Efficient and Context-Aware KGQA
Aug 01, 2025
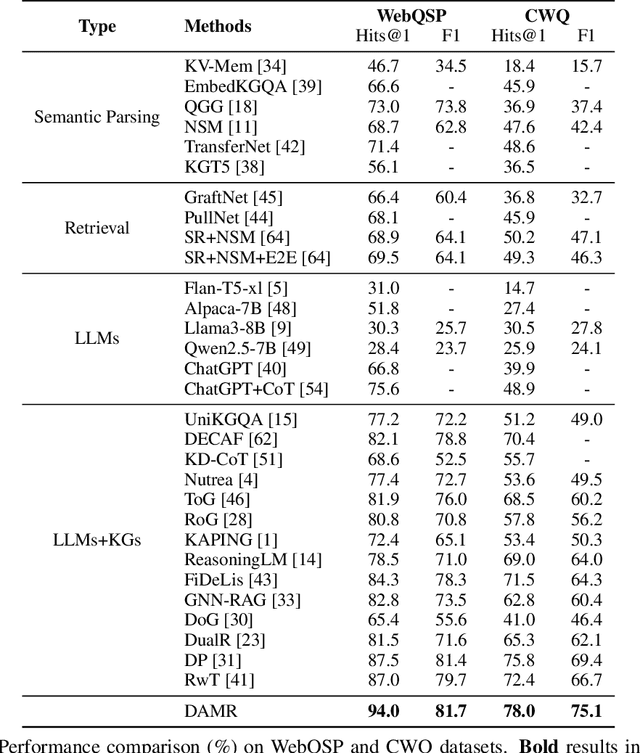


Knowledge Graph Question Answering (KGQA) aims to interpret natural language queries and perform structured reasoning over knowledge graphs by leveraging their relational and semantic structures to retrieve accurate answers. Recent KGQA methods primarily follow either retrieve-then-reason paradigm, relying on GNNs or heuristic rules for static paths extraction, or dynamic path generation strategies that use large language models (LLMs) with prompting to jointly perform retrieval and reasoning. However, the former suffers from limited adaptability due to static path extraction and lack of contextual refinement, while the latter incurs high computational costs and struggles with accurate path evaluation due to reliance on fixed scoring functions and extensive LLM calls. To address these issues, this paper proposes Dynamically Adaptive MCTS-based Reasoning (DAMR), a novel framework that integrates symbolic search with adaptive path evaluation for efficient and context-aware KGQA. DAMR employs a Monte Carlo Tree Search (MCTS) backbone guided by an LLM-based planner, which selects top-$k$ relevant relations at each step to reduce search space. To improve path evaluation accuracy, we introduce a lightweight Transformer-based scorer that performs context-aware plausibility estimation by jointly encoding the question and relation sequence through cross-attention, enabling the model to capture fine-grained semantic shifts during multi-hop reasoning. Furthermore, to alleviate the scarcity of high-quality supervision, DAMR incorporates a dynamic pseudo-path refinement mechanism that periodically generates training signals from partial paths explored during search, allowing the scorer to continuously adapt to the evolving distribution of reasoning trajectories. Extensive experiments on multiple KGQA benchmarks show that DAMR significantly outperforms state-of-the-art methods.