 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
Aug 10, 2025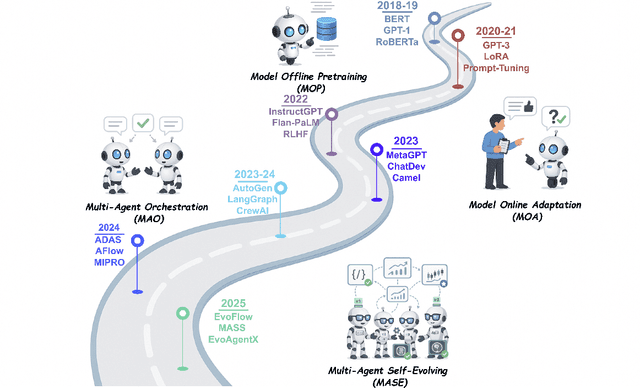
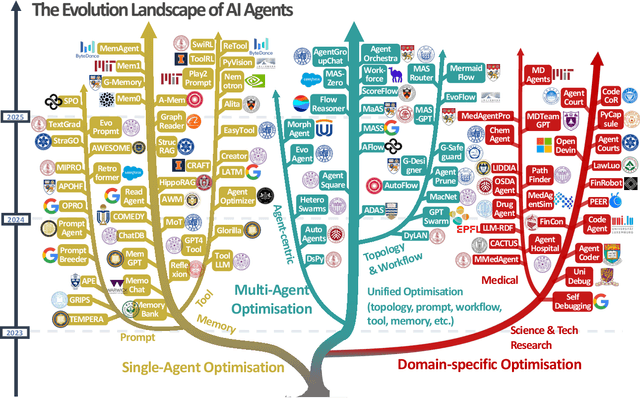
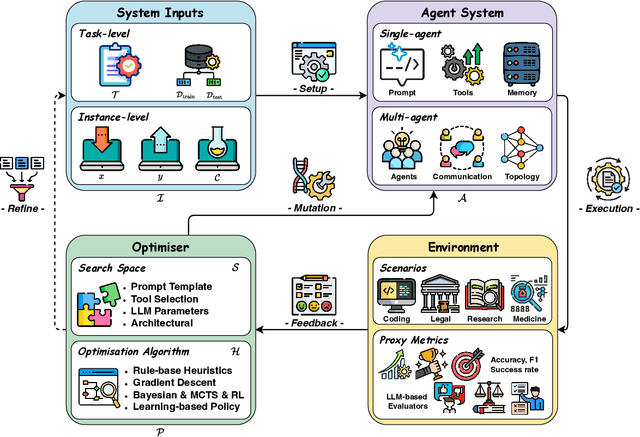
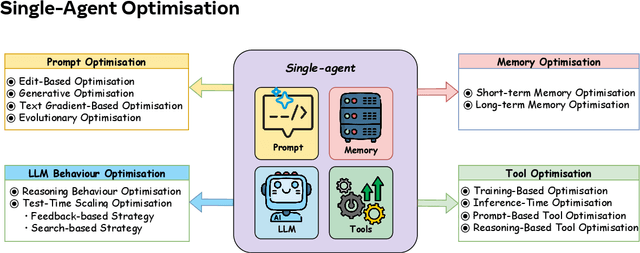
Recent advances in large language models have sparked growing interest in AI agents capable of solving complex, real-world tasks. However, most existing agent systems rely on manually crafted configurations that remain static after deployment, limiting their ability to adapt to dynamic and evolving environments. To this end, recent research has explored agent evolution techniques that aim to automatically enhance agent systems based on interaction data and environmental feedback. This emerging direction lays the foundation for self-evolving AI agents, which bridge the static capabilities of foundation models with the continuous adaptability required by lifelong agentic systems. In this survey, we provide a comprehensive review of existing techniques for self-evolving agentic systems. Specifically, we first introduce a unified conceptual framework that abstracts the feedback loop underlying the design of self-evolving agentic systems. The framework highlights four key components: System Inputs, Agent System, Environment, and Optimisers, serving as a foundation for understanding and comparing different strategies. Based on this framework, we systematically review a wide range of self-evolving techniques that target different components of the agent system. We also investigate domain-specific evolution strategies developed for specialised fields such as biomedicine, programming, and finance, where optimisation objectives are tightly coupled with domain constraints. In addition, we provide a dedicated discussion on the evaluation, safety, and ethical considerations for self-evolving agentic systems, which are critical to ensuring their effectiveness and reliability. This survey aims to provide researchers and practitioners with a systematic understanding of self-evolving AI agents, laying the foundation for the development of more adaptive, autonomous, and lifelong agentic systems.
Constructing and Evaluating Declarative RAG Pipelines in PyTerrier
Jun 12, 2025


Search engines often follow a pipeline architecture, where complex but effective reranking components are used to refine the results of an initial retrieval. Retrieval augmented generation (RAG) is an exciting application of the pipeline architecture, where the final component generates a coherent answer for the users from the retrieved documents. In this demo paper, we describe how such RAG pipelines can be formulated in the declarative PyTerrier architecture, and the advantages of doing so. Our PyTerrier-RAG extension for PyTerrier provides easy access to standard RAG datasets and evaluation measures, state-of-the-art LLM readers, and using PyTerrier's unique operator notation, easy-to-build pipelines. We demonstrate the succinctness of indexing and RAG pipelines on standard datasets (including Natural Questions) and how to build on the larger PyTerrier ecosystem with state-of-the-art sparse, learned-sparse, and dense retrievers, and other neural rankers.
SEW: Self-Evolving Agentic Workflows for Automated Code Generation
May 24, 2025Large Language Models (LLMs) have demonstrated effectiveness in code generation tasks. To enable LLMs to address more complex coding challenges, existing research has focused on crafting multi-agent systems with agentic workflows, where complex coding tasks are decomposed into sub-tasks, assigned to specialized agents. Despite their effectiveness, current approaches heavily rely on hand-crafted agentic workflows, with both agent topologies and prompts manually designed, which limits their ability to automatically adapt to different types of coding problems. To address these limitations and enable automated workflow design, we propose \textbf{S}elf-\textbf{E}volving \textbf{W}orkflow (\textbf{SEW}), a novel self-evolving framework that automatically generates and optimises multi-agent workflows. Extensive experiments on three coding benchmark datasets, including the challenging LiveCodeBench, demonstrate that our SEW can automatically design agentic workflows and optimise them through self-evolution, bringing up to 33\% improvement on LiveCodeBench compared to using the backbone LLM only. Furthermore, by investigating different representation schemes of workflow, we provide insights into the optimal way to encode workflow information with text.
KiRAG: Knowledge-Driven Iterative Retriever for Enhancing Retrieval-Augmented Generation
Feb 25, 2025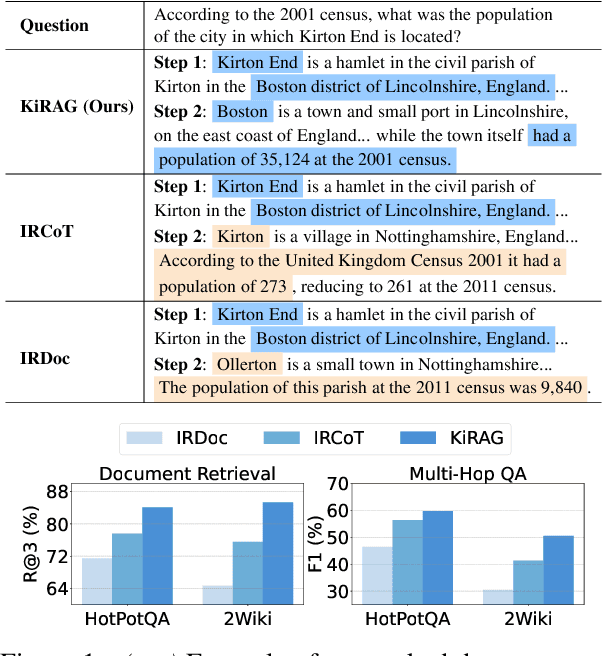
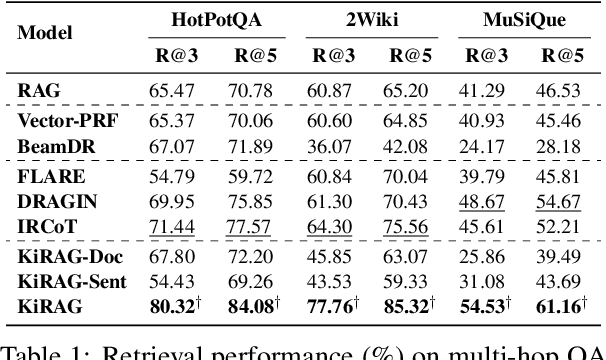
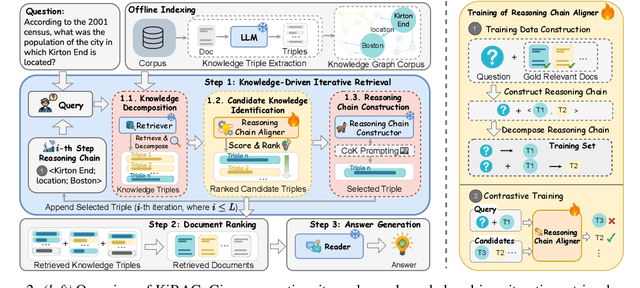
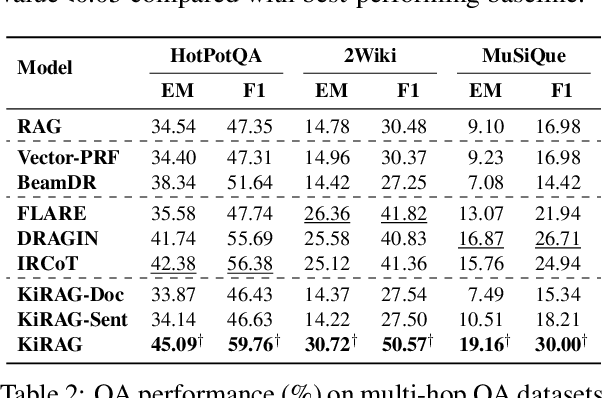
Iterative retrieval-augmented generation (iRAG) models offer an effective approach for multi-hop question answering (QA). However, their retrieval process faces two key challenges: (1) it can be disrupted by irrelevant documents or factually inaccurate chain-of-thoughts; (2) their retrievers are not designed to dynamically adapt to the evolving information needs in multi-step reasoning, making it difficult to identify and retrieve the missing information required at each iterative step. Therefore, we propose KiRAG, which uses a knowledge-driven iterative retriever model to enhance the retrieval process of iRAG. Specifically, KiRAG decomposes documents into knowledge triples and performs iterative retrieval with these triples to enable a factually reliable retrieval process. Moreover, KiRAG integrates reasoning into the retrieval process to dynamically identify and retrieve knowledge that bridges information gaps, effectively adapting to the evolving information needs. Empirical results show that KiRAG significantly outperforms existing iRAG models, with an average improvement of 9.40% in R@3 and 5.14% in F1 on multi-hop QA.
KEIR @ ECIR 2025: The Second Workshop on Knowledge-Enhanced Information Retrieval
Jan 20, 2025Pretrained language models (PLMs) like BERT and GPT-4 have become the foundation for modern information retrieval (IR) systems. However, existing PLM-based IR models primarily rely on the knowledge learned during training for prediction, limiting their ability to access and incorporate external, up-to-date, or domain-specific information. Therefore, current information retrieval systems struggle with semantic nuances, context relevance, and domain-specific issues. To address these challenges, we propose the second Knowledge-Enhanced Information Retrieval workshop (KEIR @ ECIR 2025) as a platform to discuss innovative approaches that integrate external knowledge, aiming to enhance the effectiveness of information retrieval in a rapidly evolving technological landscape. The goal of this workshop is to bring together researchers from academia and industry to discuss various aspects of knowledge-enhanced information retrieval.
On the Structural Memory of LLM Agents
Dec 17, 2024
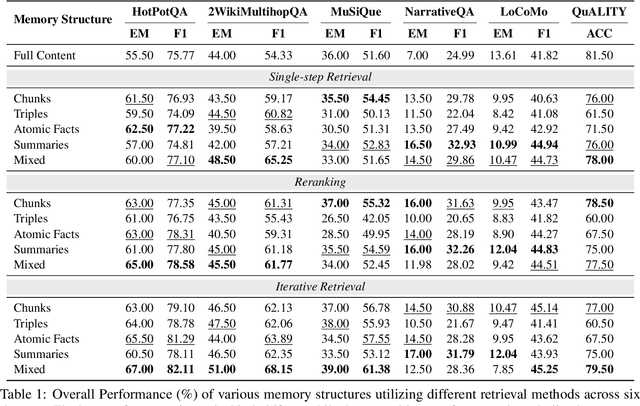


Memory plays a pivotal role in enabling large language model~(LLM)-based agents to engage in complex and long-term interactions, such as question answering (QA) and dialogue systems. While various memory modules have been proposed for these tasks, the impact of different memory structures across tasks remains insufficiently explored. This paper investigates how memory structures and memory retrieval methods affect the performance of LLM-based agents. Specifically, we evaluate four types of memory structures, including chunks, knowledge triples, atomic facts, and summaries, along with mixed memory that combines these components. In addition, we evaluate three widely used memory retrieval methods: single-step retrieval, reranking, and iterative retrieval. Extensive experiments conducted across four tasks and six datasets yield the following key insights: (1) Different memory structures offer distinct advantages, enabling them to be tailored to specific tasks; (2) Mixed memory structures demonstrate remarkable resilience in noisy environments; (3) Iterative retrieval consistently outperforms other methods across various scenarios. Our investigation aims to inspire further research into the design of memory systems for LLM-based agents.
TRACE the Evidence: Constructing Knowledge-Grounded Reasoning Chains for Retrieval-Augmented Generation
Jun 17, 2024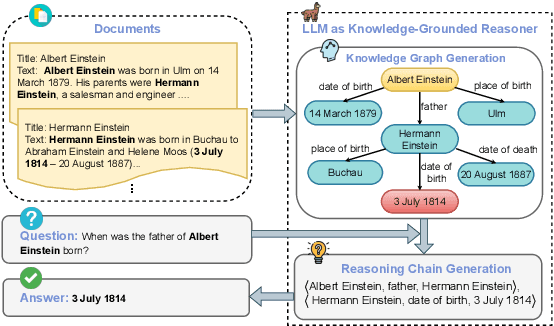
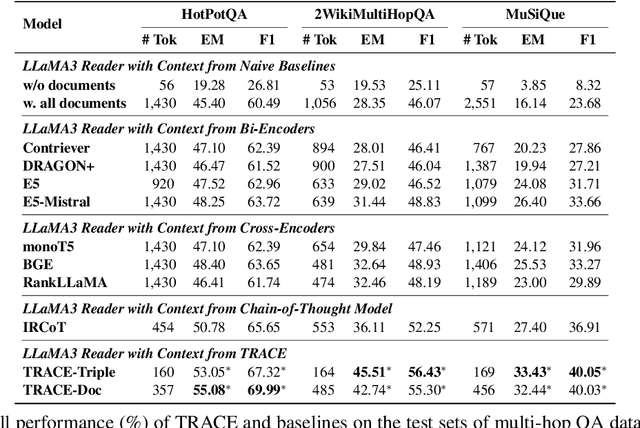


Retrieval-augmented generation (RAG) offers an effective approach for addressing question answering (QA) tasks. However, the imperfections of the retrievers in RAG models often result in the retrieval of irrelevant information, which could introduce noises and degrade the performance, especially when handling multi-hop questions that require multiple steps of reasoning. To enhance the multi-hop reasoning ability of RAG models, we propose TRACE. TRACE constructs knowledge-grounded reasoning chains, which are a series of logically connected knowledge triples, to identify and integrate supporting evidence from the retrieved documents for answering questions. Specifically, TRACE employs a KG Generator to create a knowledge graph (KG) from the retrieved documents, and then uses an Autoregressive Reasoning Chain Constructor to build reasoning chains. Experimental results on three multi-hop QA datasets show that TRACE achieves an average performance improvement of up to 14.03% compared to using all the retrieved documents. Moreover, the results indicate that using reasoning chains as context, rather than the entire documents, is often sufficient to correctly answer questions.
Knowledge Graph Embedding: A Survey from the Perspective of Representation Spaces
Nov 07, 2022



Knowledge graph embedding (KGE) is a increasingly popular technique that aims to represent entities and relations of knowledge graphs into low-dimensional semantic spaces for a wide spectrum of applications such as link prediction, knowledge reasoning and knowledge completion. In this paper, we provide a systematic review of existing KGE techniques based on representation spaces. Particularly, we build a fine-grained classification to categorise the models based on three mathematical perspectives of the representation spaces: (1) Algebraic perspective, (2) Geometric perspective, and (3) Analytical perspective. We introduce the rigorous definitions of fundamental mathematical spaces before diving into KGE models and their mathematical properties. We further discuss different KGE methods over the three categories, as well as summarise how spatial advantages work over different embedding needs. By collating the experimental results from downstream tasks, we also explore the advantages of mathematical space in different scenarios and the reasons behind them. We further state some promising research directions from a representation space perspective, with which we hope to inspire researchers to design their KGE models as well as their related applications with more consideration of their mathematical space properties.
Semi-supervisedly Co-embedding Attributed Networks
Oct 31, 2019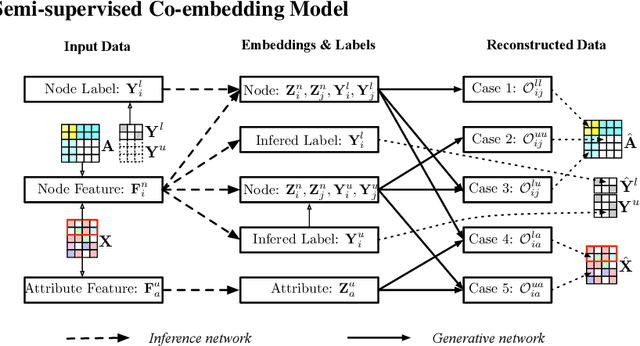
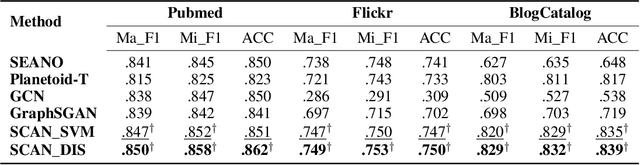
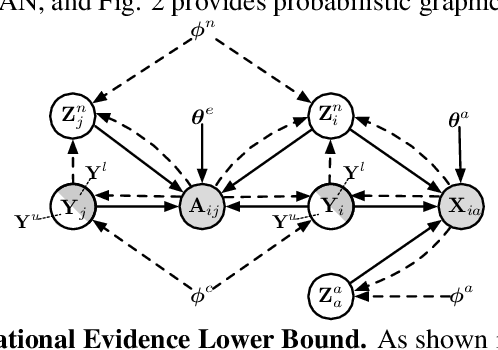
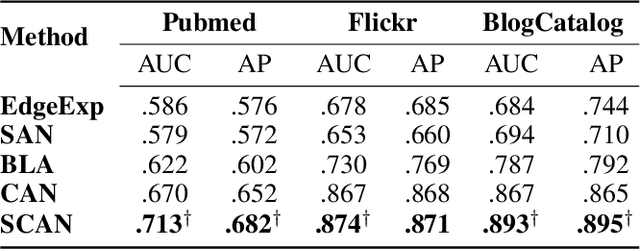
Deep generative models (DGMs) have achieved remarkable advances. Semi-supervised variational auto-encoders (SVAE) as a classical DGM offer a principled framework to effectively generalize from small labelled data to large unlabelled ones, but it is difficult to incorporate rich unstructured relationships within the multiple heterogeneous entities. In this paper, to deal with the problem, we present a semi-supervised co-embedding model for attributed networks (SCAN) based on the generalized SVAE for heterogeneous data, which collaboratively learns low-dimensional vector representations of both nodes and attributes for partially labelled attributed networks semi-supervisedly. The node and attribute embeddings obtained in a unified manner by our SCAN can benefit for capturing not only the proximities between nodes but also the affinities between nodes and attributes. Moreover, our model also trains a discriminative network to learn the label predictive distribution of nodes. Experimental results on real-world networks demonstrate that our model yields excellent performance in a number of applications such as attribute inference, user profiling and node classification compared to the state-of-the-art baselines.