 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing and Evaluating Declarative RAG Pipelines in PyTerrier
Jun 12, 2025


Search engines often follow a pipeline architecture, where complex but effective reranking components are used to refine the results of an initial retrieval. Retrieval augmented generation (RAG) is an exciting application of the pipeline architecture, where the final component generates a coherent answer for the users from the retrieved documents. In this demo paper, we describe how such RAG pipelines can be formulated in the declarative PyTerrier architecture, and the advantages of doing so. Our PyTerrier-RAG extension for PyTerrier provides easy access to standard RAG datasets and evaluation measures, state-of-the-art LLM readers, and using PyTerrier's unique operator notation, easy-to-build pipelines. We demonstrate the succinctness of indexing and RAG pipelines on standard datasets (including Natural Questions) and how to build on the larger PyTerrier ecosystem with state-of-the-art sparse, learned-sparse, and dense retrievers, and other neural rankers.
Disentangling Locality and Entropy in Ranking Distillation
May 27, 2025

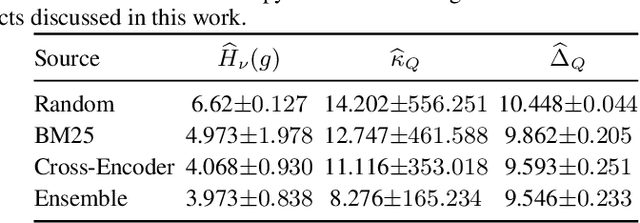

The training process of ranking models involves two key data selection decisions: a sampling strategy, and a labeling strategy. Modern ranking systems, especially those for performing semantic search, typically use a ``hard negative'' sampling strategy to identify challenging items using heuristics and a distillation labeling strategy to transfer ranking "knowledge" from a more capable model. In practice, these approaches have grown increasingly expensive and complex, for instance, popular pretrained rankers from SentenceTransformers involve 12 models in an ensemble with data provenance hampering reproducibility. Despite their complexity, modern sampling and labeling strategies have not been fully ablated, leaving the underlying source of effectiveness gains unclear. Thus, to better understand why models improve and potentially reduce the expense of training effective models, we conduct a broad ablation of sampling and distillation processes in neural ranking. We frame and theoretically derive the orthogonal nature of model geometry affected by example selection and the effect of teacher ranking entropy on ranking model optimization, establishing conditions in which data augmentation can effectively improve bias in a ranking model. Empirically, our investigation on established benchmarks and common architectures shows that sampling processes that were once highly effective in contrastive objectives may be spurious or harmful under distillation. We further investigate how data augmentation, in terms of inputs and targets, can affect effectiveness and the intrinsic behavior of models in ranking. Through this work, we aim to encourage more computationally efficient approaches that reduce focus on contrastive pairs and instead directly understand training dynamics under rankings, which better represent real-world settings.
Modeling Ranking Properties with In-Context Learning
May 23, 2025While standard IR models are mainly designed to optimize relevance, real-world search often needs to balance additional objectives such as diversity and fairness. These objectives depend on inter-document interactions and are commonly addressed using post-hoc heuristics or supervised learning methods, which require task-specific training for each ranking scenario and dataset. In this work, we propose an in-context learning (ICL) approach that eliminates the need for such training. Instead, our method relies on a small number of example rankings that demonstrate the desired trade-offs between objectives for past queries similar to the current input. We evaluate our approach on four IR test collections to investigate multiple auxiliary objectives: group fairness (TREC Fairness), polarity diversity (Touch\'e), and topical diversity (TREC Deep Learning 2019/2020). We empirically validate that our method enables control over ranking behavior through demonstration engineering, allowing nuanced behavioral adjustments without explicit optimization.
Variations in Relevance Judgments and the Shelf Life of Test Collections
Feb 28, 2025The fundamental property of Cranfield-style evaluations, that system rankings are stable even when assessors disagree on individual relevance decisions, was validated on traditional test collections. However, the paradigm shift towards neural retrieval models affected the characteristics of modern test collections, e.g., documents are short, judged with four grades of relevance, and information needs have no descriptions or narratives. Under these changes, it is unclear whether assessor disagreement remains negligible for system comparisons. We investigate this aspect under the additional condition that the few modern test collections are heavily re-used. Given more possible query interpretations due to less formalized information needs, an ''expiration date'' for test collections might be needed if top-effectiveness requires overfitting to a single interpretation of relevance. We run a reproducibility study and re-annotate the relevance judgments of the 2019 TREC Deep Learning track. We can reproduce prior work in the neural retrieval setting, showing that assessor disagreement does not affect system rankings. However, we observe that some models substantially degrade with our new relevance judgments, and some have already reached the effectiveness of humans as rankers, providing evidence that test collections can expire.
MechIR: A Mechanistic Interpretability Framework for Information Retrieval
Jan 17, 2025Mechanistic interpretability is an emerging diagnostic approach for neural models that has gained traction in broader natural language processing domains. This paradigm aims to provide attribution to components of neural systems where causal relationships between hidden layers and output were previously uninterpretable. As the use of neural models in IR for retrieval and evaluation becomes ubiquitous, we need to ensure that we can interpret why a model produces a given output for both transparency and the betterment of systems. This work comprises a flexible framework for diagnostic analysis and intervention within these highly parametric neural systems specifically tailored for IR tasks and architectures. In providing such a framework, we look to facilitate further research in interpretable IR with a broader scope for practical interventions derived from mechanistic interpretability. We provide preliminary analysis and look to demonstrate our framework through an axiomatic lens to show its applications and ease of use for those IR practitioners inexperienced in this emerging paradigm.
Training on the Test Model: Contamination in Ranking Distillation
Nov 04, 2024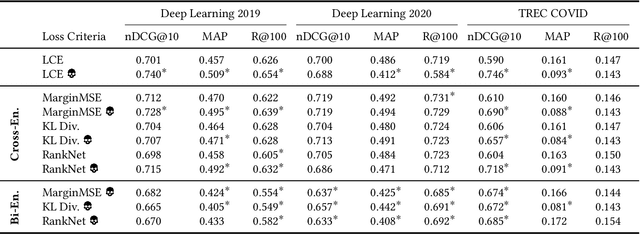
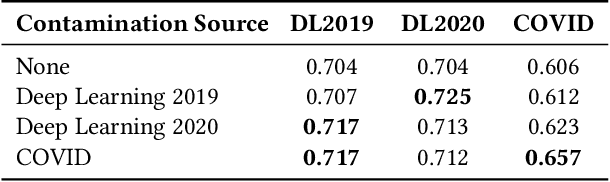
Neural approaches to ranking based on pre-trained language models are highly effective in ad-hoc search. However, the computational expense of these models can limit their application. As such, a process known as knowledge distillation is frequently applied to allow a smaller, efficient model to learn from an effective but expensive model. A key example of this is the distillation of expensive API-based commercial Large Language Models into smaller production-ready models. However, due to the opacity of training data and processes of most commercial models, one cannot ensure that a chosen test collection has not been observed previously, creating the potential for inadvertent data contamination. We, therefore, investigate the effect of a contaminated teacher model in a distillation setting. We evaluate several distillation techniques to assess the degree to which contamination occurs during distillation. By simulating a ``worst-case'' setting where the degree of contamination is known, we find that contamination occurs even when the test data represents a small fraction of the teacher's training samples. We, therefore, encourage caution when training using black-box teacher models where data provenance is ambiguous.
Few-shot Pairwise Rank Prompting: An Effective Non-Parametric Retrieval Model
Sep 27, 2024A supervised ranking model, despite its advantage of being effective, usually involves complex processing - typically multiple stages of task-specific pre-training and fine-tuning. This has motivated researchers to explore simpler pipelines leveraging large language models (LLMs) that are capable of working in a zero-shot manner. However, since zero-shot inference does not make use of a training set of pairs of queries and their relevant documents, its performance is mostly worse than that of supervised models, which are trained on such example pairs. Motivated by the existing findings that training examples generally improve zero-shot performance, in our work, we explore if this also applies to ranking models. More specifically, given a query and a pair of documents, the preference prediction task is improved by augmenting examples of preferences for similar queries from a training set. Our proposed pairwise few-shot ranker demonstrates consistent improvements over the zero-shot baseline on both in-domain (TREC DL) and out-domain (BEIR subset) retrieval benchmarks. Our method also achieves a close performance to that of a supervised model without requiring any complex training pipeline.
Top-Down Partitioning for Efficient List-Wise Ranking
May 23, 2024Large Language Models (LLMs) have significantly impacted many facets of natural language processing and information retrieval. Unlike previous encoder-based approaches, the enlarged context window of these generative models allows for ranking multiple documents at once, commonly called list-wise ranking. However, there are still limits to the number of documents that can be ranked in a single inference of the model, leading to the broad adoption of a sliding window approach to identify the k most relevant items in a ranked list. We argue that the sliding window approach is not well-suited for list-wise re-ranking because it (1) cannot be parallelized in its current form, (2) leads to redundant computational steps repeatedly re-scoring the best set of documents as it works its way up the initial ranking, and (3) prioritizes the lowest-ranked documents for scoring rather than the highest-ranked documents by taking a bottom-up approach. Motivated by these shortcomings and an initial study that shows list-wise rankers are biased towards relevant documents at the start of their context window, we propose a novel algorithm that partitions a ranking to depth k and processes documents top-down. Unlike sliding window approaches, our algorithm is inherently parallelizable due to the use of a pivot element, which can be compared to documents down to an arbitrary depth concurrently. In doing so, we reduce the number of expected inference calls by around 33% when ranking at depth 100 while matching the performance of prior approaches across multiple strong re-rankers.
"In-Context Learning" or: How I learned to stop worrying and love "Applied Information Retrieval"
May 02, 2024With the increasing ability of large language models (LLMs), in-context learning (ICL) has evolved as a new paradigm for natural language processing (NLP), where instead of fine-tuning the parameters of an LLM specific to a downstream task with labeled examples, a small number of such examples is appended to a prompt instruction for controlling the decoder's generation process. ICL, thus, is conceptually similar to a non-parametric approach, such as $k$-NN, where the prediction for each instance essentially depends on the local topology, i.e., on a localised set of similar instances and their labels (called few-shot examples). This suggests that a test instance in ICL is analogous to a query in IR, and similar examples in ICL retrieved from a training set relate to a set of documents retrieved from a collection in IR. While standard unsupervised ranking models can be used to retrieve these few-shot examples from a training set, the effectiveness of the examples can potentially be improved by re-defining the notion of relevance specific to its utility for the downstream task, i.e., considering an example to be relevant if including it in the prompt instruction leads to a correct prediction. With this task-specific notion of relevance, it is possible to train a supervised ranking model (e.g., a bi-encoder or cross-encoder), which potentially learns to optimally select the few-shot examples. We believe that the recent advances in neural rankers can potentially find a use case for this task of optimally choosing examples for more effective downstream ICL predictions.
Generative Relevance Feedback and Convergence of Adaptive Re-Ranking: University of Glasgow Terrier Team at TREC DL 2023
May 02, 2024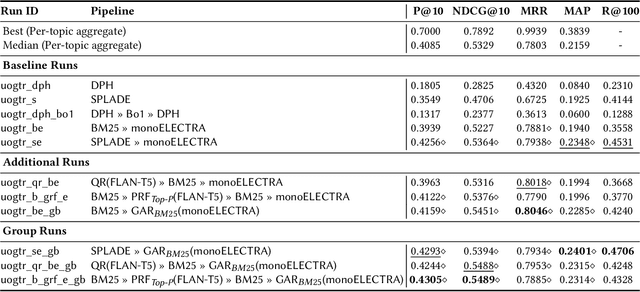
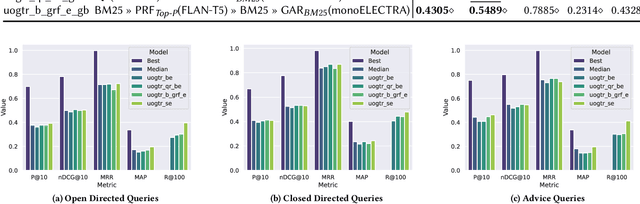
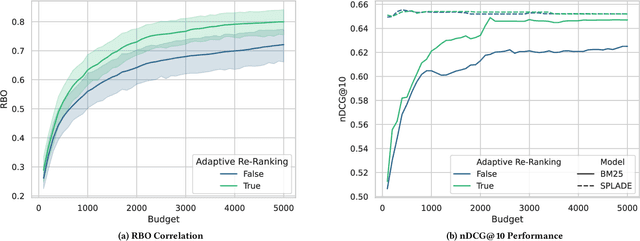
This paper describes our participation in the TREC 2023 Deep Learning Track. We submitted runs that apply generative relevance feedback from a large language model in both a zero-shot and pseudo-relevance feedback setting over two sparse retrieval approaches, namely BM25 and SPLADE. We couple this first stage with adaptive re-ranking over a BM25 corpus graph scored using a monoELECTRA cross-encoder. We investigate the efficacy of these generative approaches for different query types in first-stage retrieval. In re-ranking, we investigate operating points of adaptive re-ranking with different first stages to find the point in graph traversal where the first stage no longer has an effect on the performance of the overall retrieval pipeline. We find some performance gains from the application of generative query reformulation. However, our strongest run in terms of P@10 and nDCG@10 applied both adaptive re-ranking and generative pseudo-relevance feedback, namely uogtr_b_grf_e_gb.