 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Text Ranking in Deep Research
Feb 25, 2026Deep research has emerged as an important task that aims to address hard queries through extensive open-web exploration. To tackle it, most prior work equips large language model (LLM)-based agents with opaque web search APIs, enabling agents to iteratively issue search queries, retrieve external evidence, and reason over it. Despite search's essential role in deep research, black-box web search APIs hinder systematic analysis of search components, leaving the behaviour of established text ranking methods in deep research largely unclear. To fill this gap, we reproduce a selection of key findings and best practices for IR text ranking methods in the deep research setting. In particular, we examine their effectiveness from three perspectives: (i) retrieval units (documents vs. passages), (ii) pipeline configurations (different retrievers, re-rankers, and re-ranking depths), and (iii) query characteristics (the mismatch between agent-issued queries and the training queries of text rankers). We perform experiments on BrowseComp-Plus, a deep research dataset with a fixed corpus, evaluating 2 open-source agents, 5 retrievers, and 3 re-rankers across diverse setups. We find that agent-issued queries typically follow web-search-style syntax (e.g., quoted exact matches), favouring lexical, learned sparse, and multi-vector retrievers; passage-level units are more efficient under limited context windows, and avoid the difficulties of document length normalisation in lexical retrieval; re-ranking is highly effective; translating agent-issued queries into natural-language questions significantly bridges the query mismatch.
A Picture of Agentic Search
Feb 19, 2026With automated systems increasingly issuing search queries alongside humans, Information Retrieval (IR) faces a major shift. Yet IR remains human-centred, with systems, evaluation metrics, user models, and datasets designed around human queries and behaviours. Consequently, IR operates under assumptions that no longer hold in practice, with changes to workload volumes, predictability, and querying behaviours. This misalignment affects system performance and optimisation: caching may lose effectiveness, query pre-processing may add overhead without improving results, and standard metrics may mismeasure satisfaction. Without adaptation, retrieval models risk satisfying neither humans, nor the emerging user segment of agents. However, datasets capturing agent search behaviour are lacking, which is a critical gap given IR's historical reliance on data-driven evaluation and optimisation. We develop a methodology for collecting all the data produced and consumed by agentic retrieval-augmented systems when answering queries, and we release the Agentic Search Queryset (ASQ) dataset. ASQ contains reasoning-induced queries, retrieved documents, and thoughts for queries in HotpotQA, Researchy Questions, and MS MARCO, for 3 diverse agents and 2 retrieval pipelines. The accompanying toolkit enables ASQ to be extended to new agents, retrievers, and datasets.
Overview of the TREC 2025 RAGTIME Track
Feb 10, 2026The principal goal of the RAG TREC Instrument for Multilingual Evaluation (RAGTIME) track at TREC is to study report generation from multilingual source documents. The track has created a document collection containing Arabic, Chinese, English, and Russian news stories. RAGTIME includes three task types: Multilingual Report Generation, English Report Generation, and Multilingual Information Retrieval (MLIR). A total of 125 runs were submitted by 13 participating teams (and as baselines by the track coordinators) for three tasks. This overview describes these three tasks and presents the available results.
NeuCLIRTech: Chinese Monolingual and Cross-Language Information Retrieval Evaluation in a Challenging Domain
Feb 05, 2026Measuring advances in retrieval requires test collections with relevance judgments that can faithfully distinguish systems. This paper presents NeuCLIRTech, an evaluation collection for cross-language retrieval over technical information. The collection consists of technical documents written natively in Chinese and those same documents machine translated into English. It includes 110 queries with relevance judgments. The collection supports two retrieval scenarios: monolingual retrieval in Chinese, and cross-language retrieval with English as the query language. NeuCLIRTech combines the TREC NeuCLIR track topics of 2023 and 2024. The 110 queries with 35,962 document judgments provide strong statistical discriminatory power when trying to distinguish retrieval approaches. A fusion baseline of strong neural retrieval systems is included so that developers of reranking algorithms are not reliant on BM25 as their first stage retriever. The dataset and artifacts are released on Huggingface Datasets
Pipeline Inspection, Visualization, and Interoperability in PyTerrier
Jan 24, 2026PyTerrier provides a declarative framework for building and experimenting with Information Retrieval (IR) pipelines. In this demonstration, we highlight several recent pipeline operations that improve their ability to be programmatically inspected, visualized, and integrated with other tools (via the Model Context Protocol, MCP). These capabilities aim to make it easier for researchers, students, and AI agents to understand and use a wide array of IR pipelines.
To Case or Not to Case: An Empirical Study in Learned Sparse Retrieval
Jan 24, 2026Learned Sparse Retrieval (LSR) methods construct sparse lexical representations of queries and documents that can be efficiently searched using inverted indexes. Existing LSR approaches have relied almost exclusively on uncased backbone models, whose vocabularies exclude case-sensitive distinctions, thereby reducing vocabulary mismatch. However, the most recent state-of-the-art language models are only available in cased versions. Despite this shift, the impact of backbone model casing on LSR has not been studied, potentially posing a risk to the viability of the method going forward. To fill this gap, we systematically evaluate paired cased and uncased versions of the same backbone models across multiple datasets to assess their suitability for LSR. Our findings show that LSR models with cased backbone models by default perform substantially worse than their uncased counterparts; however, this gap can be eliminated by pre-processing the text to lowercase. Moreover, our token-level analysis reveals that, under lowercasing, cased models almost entirely suppress cased vocabulary items and behave effectively as uncased models, explaining their restored performance. This result broadens the applicability of recent cased models to the LSR setting and facilitates the integration of stronger backbone architectures into sparse retrieval. The complete code and implementation for this project are available at: https://github.com/lionisakis/Uncased-vs-cased-models-in-LSR
NeuCLIRBench: A Modern Evaluation Collection for Monolingual, Cross-Language, and Multilingual Information Retrieval
Nov 18, 2025

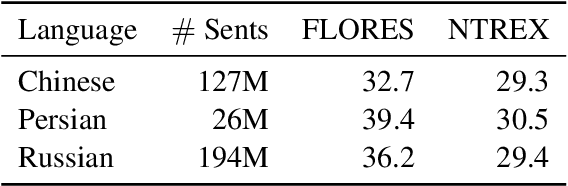
To measure advances in retrieval, test collections with relevance judgments that can faithfully distinguish systems are required. This paper presents NeuCLIRBench, an evaluation collection for cross-language and multilingual retrieval. The collection consists of documents written natively in Chinese, Persian, and Russian, as well as those same documents machine translated into English. The collection supports several retrieval scenarios including: monolingual retrieval in English, Chinese, Persian, or Russian; cross-language retrieval with English as the query language and one of the other three languages as the document language; and multilingual retrieval, again with English as the query language and relevant documents in all three languages. NeuCLIRBench combines the TREC NeuCLIR track topics of 2022, 2023, and 2024. The 250,128 judgments across approximately 150 queries for the monolingual and cross-language tasks and 100 queries for multilingual retrieval provide strong statistical discriminatory power to distinguish retrieval approaches. A fusion baseline of strong neural retrieval systems is included with the collection so that developers of reranking algorithms are no longer reliant on BM25 as their first-stage retriever. NeuCLIRBench is publicly available.
Overview of the TREC 2024 NeuCLIR Track
Sep 17, 2025The principal goal of the TREC Neural Cross-Language Information Retrieval (NeuCLIR) track is to study the effect of neural approaches on cross-language information access. The track has created test collections containing Chinese, Persian, and Russian news stories and Chinese academic abstracts. NeuCLIR includes four task types: Cross-Language Information Retrieval (CLIR) from news, Multilingual Information Retrieval (MLIR) from news, Report Generation from news, and CLIR from technical documents. A total of 274 runs were submitted by five participating teams (and as baselines by the track coordinators) for eight tasks across these four task types. Task descriptions and the available results are presented.
Disentangling Locality and Entropy in Ranking Distillation
May 27, 2025


The training process of ranking models involves two key data selection decisions: a sampling strategy, and a labeling strategy. Modern ranking systems, especially those for performing semantic search, typically use a ``hard negative'' sampling strategy to identify challenging items using heuristics and a distillation labeling strategy to transfer ranking "knowledge" from a more capable model. In practice, these approaches have grown increasingly expensive and complex, for instance, popular pretrained rankers from SentenceTransformers involve 12 models in an ensemble with data provenance hampering reproducibility. Despite their complexity, modern sampling and labeling strategies have not been fully ablated, leaving the underlying source of effectiveness gains unclear. Thus, to better understand why models improve and potentially reduce the expense of training effective models, we conduct a broad ablation of sampling and distillation processes in neural ranking. We frame and theoretically derive the orthogonal nature of model geometry affected by example selection and the effect of teacher ranking entropy on ranking model optimization, establishing conditions in which data augmentation can effectively improve bias in a ranking model. Empirically, our investigation on established benchmarks and common architectures shows that sampling processes that were once highly effective in contrastive objectives may be spurious or harmful under distillation. We further investigate how data augmentation, in terms of inputs and targets, can affect effectiveness and the intrinsic behavior of models in ranking. Through this work, we aim to encourage more computationally efficient approaches that reduce focus on contrastive pairs and instead directly understand training dynamics under rankings, which better represent real-world settings.
An Alternative to FLOPS Regularization to Effectively Productionize SPLADE-Doc
May 21, 2025

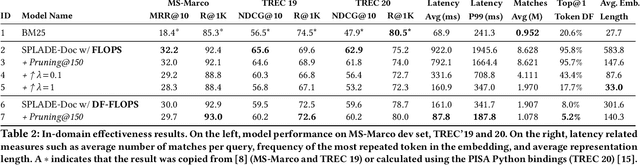

Learned Sparse Retrieval (LSR) models encode text as weighted term vectors, which need to be sparse to leverage inverted index structures during retrieval. SPLADE, the most popular LSR model, uses FLOPS regularization to encourage vector sparsity during training. However, FLOPS regularization does not ensure sparsity among terms - only within a given query or document. Terms with very high Document Frequencies (DFs) substantially increase latency in production retrieval engines, such as Apache Solr, due to their lengthy posting lists. To address the issue of high DFs, we present a new variant of FLOPS regularization: DF-FLOPS. This new regularization technique penalizes the usage of high-DF terms, thereby shortening posting lists and reducing retrieval latency. Unlike other inference-time sparsification methods, such as stopword removal, DF-FLOPS regularization allows for the selective inclusion of high-frequency terms in cases where the terms are truly salient. We find that DF-FLOPS successfully reduces the prevalence of high-DF terms and lowers retrieval latency (around 10x faster) in a production-grade engine while maintaining effectiveness both in-domain (only a 2.2-point drop in MRR@10) and cross-domain (improved performance in 12 out of 13 tasks on which we tested). With retrieval latencies on par with BM25, this work provides an important step towards making LSR practical for deployment in production-grade search engines.