 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Picture of Agentic Search
Feb 19, 2026With automated systems increasingly issuing search queries alongside humans, Information Retrieval (IR) faces a major shift. Yet IR remains human-centred, with systems, evaluation metrics, user models, and datasets designed around human queries and behaviours. Consequently, IR operates under assumptions that no longer hold in practice, with changes to workload volumes, predictability, and querying behaviours. This misalignment affects system performance and optimisation: caching may lose effectiveness, query pre-processing may add overhead without improving results, and standard metrics may mismeasure satisfaction. Without adaptation, retrieval models risk satisfying neither humans, nor the emerging user segment of agents. However, datasets capturing agent search behaviour are lacking, which is a critical gap given IR's historical reliance on data-driven evaluation and optimisation. We develop a methodology for collecting all the data produced and consumed by agentic retrieval-augmented systems when answering queries, and we release the Agentic Search Queryset (ASQ) dataset. ASQ contains reasoning-induced queries, retrieved documents, and thoughts for queries in HotpotQA, Researchy Questions, and MS MARCO, for 3 diverse agents and 2 retrieval pipelines. The accompanying toolkit enables ASQ to be extended to new agents, retrievers, and datasets.
Document Quality Scoring for Web Crawling
Apr 15, 2025
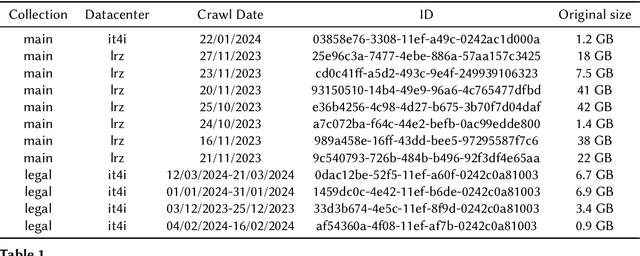


The internet contains large amounts of low-quality content, yet users expect web search engines to deliver high-quality, relevant results. The abundant presence of low-quality pages can negatively impact retrieval and crawling processes by wasting resources on these documents. Therefore, search engines can greatly benefit from techniques that leverage efficient quality estimation methods to mitigate these negative impacts. Quality scoring methods for web pages are useful for many processes typical for web search systems, including static index pruning, index tiering, and crawling. Building on work by Chang et al.~\cite{chang2024neural}, who proposed using neural estimators of semantic quality for static index pruning, we extend their approach and apply their neural quality scorers to assess the semantic quality of web pages in crawling prioritisation tasks. In our experimental analysis, we found that prioritising semantically high-quality pages over low-quality ones can improve downstream search effectiveness. Our software contribution consists of a Docker container that computes an effective quality score for a given web page, allowing the quality scorer to be easily included and used in other components of web search systems.
Exploring the Effectiveness of Multi-stage Fine-tuning for Cross-encoder Re-rankers
Mar 28, 2025State-of-the-art cross-encoders can be fine-tuned to be highly effective in passage re-ranking. The typical fine-tuning process of cross-encoders as re-rankers requires large amounts of manually labelled data, a contrastive learning objective, and a set of heuristically sampled negatives. An alternative recent approach for fine-tuning instead involves teaching the model to mimic the rankings of a highly effective large language model using a distillation objective. These fine-tuning strategies can be applied either individually, or in sequence. In this work, we systematically investigate the effectiveness of point-wise cross-encoders when fine-tuned independently in a single stage, or sequentially in two stages. Our experiments show that the effectiveness of point-wise cross-encoders fine-tuned using contrastive learning is indeed on par with that of models fine-tuned with multi-stage approaches. Code is available for reproduction at https://github.com/fpezzuti/multistage-finetuning.
Static Pruning in Dense Retrieval using Matrix Decomposition
Dec 13, 2024

In the era of dense retrieval, document indexing and retrieval is largely based on encoding models that transform text documents into embeddings. The efficiency of retrieval is directly proportional to the number of documents and the size of the embeddings. Recent studies have shown that it is possible to reduce embedding size without sacrificing - and in some cases improving - the retrieval effectiveness. However, the methods introduced by these studies are query-dependent, so they can't be applied offline and require additional computations during query processing, thus negatively impacting the retrieval efficiency. In this paper, we present a novel static pruning method for reducing the dimensionality of embeddings using Principal Components Analysis. This approach is query-independent and can be executed offline, leading to a significant boost in dense retrieval efficiency with a negligible impact on the system effectiveness. Our experiments show that our proposed method reduces the dimensionality of document representations by over 50% with up to a 5% reduction in NDCG@10, for different dense retrieval models.