 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect, Label, Evaluate: Active Testing in NLP
Mar 23, 2026Human annotation cost and time remain significant bottlenecks in Natural Language Processing (NLP), with test data annotation being particularly expensive due to the stringent requirement for low-error and high-quality labels necessary for reliable model evaluation. Traditional approaches require annotating entire test sets, leading to substantial resource requirements. Active Testing is a framework that selects the most informative test samples for annotation. Given a labeling budget, it aims to choose the subset that best estimates model performance while minimizing cost and human effort. In this work, we formalize Active Testing in NLP and we conduct an extensive benchmarking of existing approaches across 18 datasets and 4 embedding strategies spanning 4 different NLP tasks. The experiments show annotation reductions of up to 95%, with performance estimation accuracy difference from the full test set within 1%. Our analysis reveals variations in method effectiveness across different data characteristics and task types, with no single approach emerging as universally superior. Lastly, to address the limitation of requiring a predefined annotation budget in existing sample selection strategies, we introduce an adaptive stopping criterion that automatically determines the optimal number of samples.
A Picture of Agentic Search
Feb 19, 2026With automated systems increasingly issuing search queries alongside humans, Information Retrieval (IR) faces a major shift. Yet IR remains human-centred, with systems, evaluation metrics, user models, and datasets designed around human queries and behaviours. Consequently, IR operates under assumptions that no longer hold in practice, with changes to workload volumes, predictability, and querying behaviours. This misalignment affects system performance and optimisation: caching may lose effectiveness, query pre-processing may add overhead without improving results, and standard metrics may mismeasure satisfaction. Without adaptation, retrieval models risk satisfying neither humans, nor the emerging user segment of agents. However, datasets capturing agent search behaviour are lacking, which is a critical gap given IR's historical reliance on data-driven evaluation and optimisation. We develop a methodology for collecting all the data produced and consumed by agentic retrieval-augmented systems when answering queries, and we release the Agentic Search Queryset (ASQ) dataset. ASQ contains reasoning-induced queries, retrieved documents, and thoughts for queries in HotpotQA, Researchy Questions, and MS MARCO, for 3 diverse agents and 2 retrieval pipelines. The accompanying toolkit enables ASQ to be extended to new agents, retrievers, and datasets.
Concept-Enhanced Multimodal RAG: Towards Interpretable and Accurate Radiology Report Generation
Feb 17, 2026Radiology Report Generation (RRG) through Vision-Language Models (VLMs) promises to reduce documentation burden, improve reporting consistency, and accelerate clinical workflows. However, their clinical adoption remains limited by the lack of interpretability and the tendency to hallucinate findings misaligned with imaging evidence. Existing research typically treats interpretability and accuracy as separate objectives, with concept-based explainability techniques focusing primarily on transparency, while Retrieval-Augmented Generation (RAG) methods targeting factual grounding through external retrieval. We present Concept-Enhanced Multimodal RAG (CEMRAG), a unified framework that decomposes visual representations into interpretable clinical concepts and integrates them with multimodal RAG. This approach exploits enriched contextual prompts for RRG, improving both interpretability and factual accuracy. Experiments on MIMIC-CXR and IU X-Ray across multiple VLM architectures, training regimes, and retrieval configurations demonstrate consistent improvements over both conventional RAG and concept-only baselines on clinical accuracy metrics and standard NLP measures. These results challenge the assumed trade-off between interpretability and performance, showing that transparent visual concepts can enhance rather than compromise diagnostic accuracy in medical VLMs. Our modular design decomposes interpretability into visual transparency and structured language model conditioning, providing a principled pathway toward clinically trustworthy AI-assisted radiology.
Same Answer, Different Representations: Hidden instability in VLMs
Feb 06, 2026The robustness of Vision Language Models (VLMs) is commonly assessed through output-level invariance, implicitly assuming that stable predictions reflect stable multimodal processing. In this work, we argue that this assumption is insufficient. We introduce a representation-aware and frequency-aware evaluation framework that measures internal embedding drift, spectral sensitivity, and structural smoothness (spatial consistency of vision tokens), alongside standard label-based metrics. Applying this framework to modern VLMs across the SEEDBench, MMMU, and POPE datasets reveals three distinct failure modes. First, models frequently preserve predicted answers while undergoing substantial internal representation drift; for perturbations such as text overlays, this drift approaches the magnitude of inter-image variability, indicating that representations move to regions typically occupied by unrelated inputs despite unchanged outputs. Second, robustness does not improve with scale; larger models achieve higher accuracy but exhibit equal or greater sensitivity, consistent with sharper yet more fragile decision boundaries. Third, we find that perturbations affect tasks differently: they harm reasoning when they disrupt how models combine coarse and fine visual cues, but on the hallucination benchmarks, they can reduce false positives by making models generate more conservative answers.
Statistical Foundations of DIME: Risk Estimation for Practical Index Selection
Jan 09, 2026High-dimensional dense embeddings have become central to modern Information Retrieval, but many dimensions are noisy or redundant. Recently proposed DIME (Dimension IMportance Estimation), provides query-dependent scores to identify informative components of embeddings. DIME relies on a costly grid search to select a priori a dimensionality for all the query corpus's embeddings. Our work provides a statistically grounded criterion that directly identifies the optimal set of dimensions for each query at inference time. Experiments confirm achieving parity of effectiveness and reduces embedding size by an average of $\sim50\%$ across different models and datasets at inference time.
AutoBench: Automating LLM Evaluation through Reciprocal Peer Assessment
Oct 26, 2025We present AutoBench, a fully automated and self-sustaining framework for evaluating Large Language Models (LLMs) through reciprocal peer assessment. This paper provides a rigorous scientific validation of the AutoBench methodology, originally developed as an open-source project by eZecute S.R.L.. Unlike static benchmarks that suffer from test-set contamination and limited adaptability, AutoBench dynamically generates novel evaluation tasks while models alternately serve as question generators, contestants, and judges across diverse domains. An iterative weighting mechanism amplifies the influence of consistently reliable evaluators, aggregating peer judgments into consensus-based rankings that reflect collective model agreement. Our experiments demonstrate strong correlations with established benchmarks including MMLU-Pro and GPQA (respectively 78\% and 63\%), validating this peer-driven evaluation paradigm. The multi-judge design significantly outperforms single-judge baselines, confirming that distributed evaluation produces more robust and human-consistent assessments. AutoBench offers a scalable, contamination-resistant alternative to static benchmarks for the continuous evaluation of evolving language models.
Redefining Retrieval Evaluation in the Era of LLMs
Oct 24, 2025Traditional Information Retrieval (IR) metrics, such as nDCG, MAP, and MRR, assume that human users sequentially examine documents with diminishing attention to lower ranks. This assumption breaks down in Retrieval Augmented Generation (RAG) systems, where search results are consumed by Large Language Models (LLMs), which, unlike humans, process all retrieved documents as a whole rather than sequentially. Additionally, traditional IR metrics do not account for related but irrelevant documents that actively degrade generation quality, rather than merely being ignored. Due to these two major misalignments, namely human vs. machine position discount and human relevance vs. machine utility, classical IR metrics do not accurately predict RAG performance. We introduce a utility-based annotation schema that quantifies both the positive contribution of relevant passages and the negative impact of distracting ones. Building on this foundation, we propose UDCG (Utility and Distraction-aware Cumulative Gain), a metric using an LLM-oriented positional discount to directly optimize the correlation with the end-to-end answer accuracy. Experiments on five datasets and six LLMs demonstrate that UDCG improves correlation by up to 36% compared to traditional metrics. Our work provides a critical step toward aligning IR evaluation with LLM consumers and enables more reliable assessment of RAG components
Evaluating Latent Knowledge of Public Tabular Datasets in Large Language Models
Oct 23, 2025Large Language Models (LLMs) are increasingly evaluated on their ability to reason over structured data, yet such assessments often overlook a crucial confound: dataset contamination. In this work, we investigate whether LLMs exhibit prior knowledge of widely used tabular benchmarks such as Adult Income, Titanic, and others. Through a series of controlled probing experiments, we reveal that contamination effects emerge exclusively for datasets containing strong semantic cues-for instance, meaningful column names or interpretable value categories. In contrast, when such cues are removed or randomized, performance sharply declines to near-random levels. These findings suggest that LLMs' apparent competence on tabular reasoning tasks may, in part, reflect memorization of publicly available datasets rather than genuine generalization. We discuss implications for evaluation protocols and propose strategies to disentangle semantic leakage from authentic reasoning ability in future LLM assessments.
Titans Revisited: A Lightweight Reimplementation and Critical Analysis of a Test-Time Memory Model
Oct 10, 2025
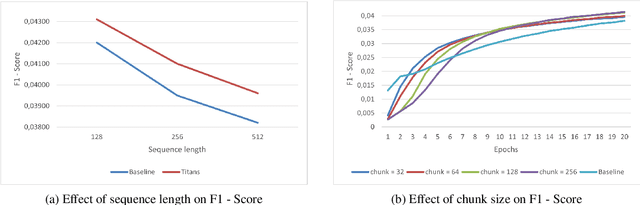
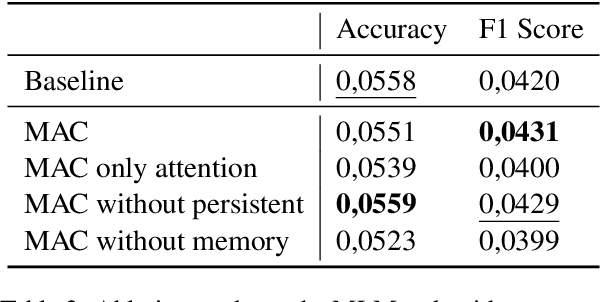
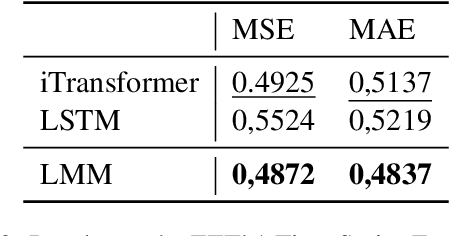
By the end of 2024, Google researchers introduced Titans: Learning at Test Time, a neural memory model achieving strong empirical results across multiple tasks. However, the lack of publicly available code and ambiguities in the original description hinder reproducibility. In this work, we present a lightweight reimplementation of Titans and conduct a comprehensive evaluation on Masked Language Modeling, Time Series Forecasting, and Recommendation tasks. Our results reveal that Titans does not always outperform established baselines due to chunking. However, its Neural Memory component consistently improves performance compared to attention-only models. These findings confirm the model's innovative potential while highlighting its practical limitations and raising questions for future research.
Directional Sheaf Hypergraph Networks: Unifying Learning on Directed and Undirected Hypergraphs
Oct 06, 2025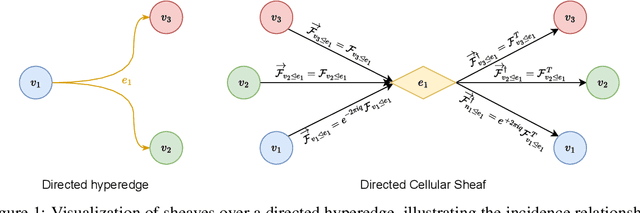
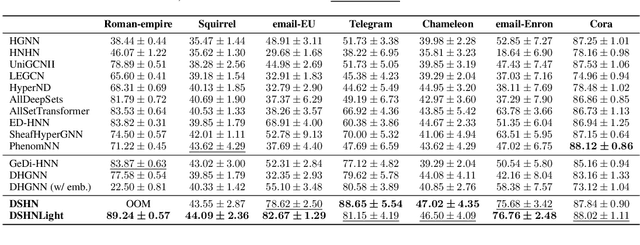
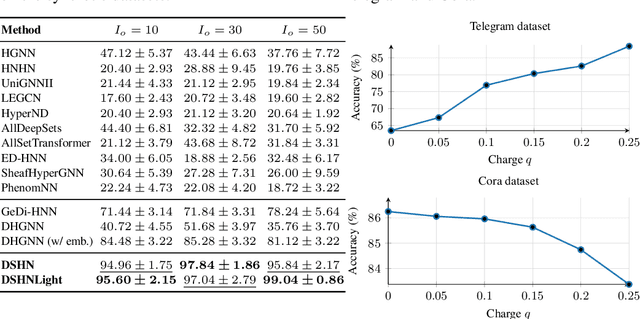
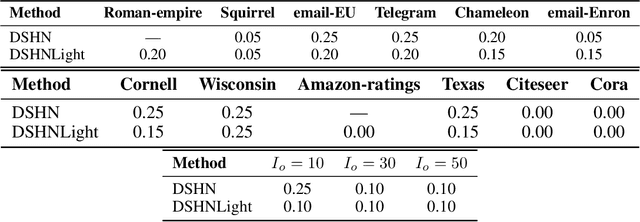
Hypergraphs provide a natural way to represent higher-order interactions among multiple entities. While undirected hypergraphs have been extensively studied, the case of directed hypergraphs, which can model oriented group interactions, remains largely under-explored despite its relevance for many applications. Recent approaches in this direction often exhibit an implicit bias toward homophily, which limits their effectiveness in heterophilic settings. Rooted in the algebraic topology notion of Cellular Sheaves, Sheaf Neural Networks (SNNs) were introduced as an effective solution to circumvent such a drawback. While a generalization to hypergraphs is known, it is only suitable for undirected hypergraphs, failing to tackle the directed case. In this work, we introduce Directional Sheaf Hypergraph Networks (DSHN), a framework integrating sheaf theory with a principled treatment of asymmetric relations within a hypergraph. From it, we construct the Directed Sheaf Hypergraph Laplacian, a complex-valued operator by which we unify and generalize many existing Laplacian matrices proposed in the graph- and hypergraph-learning literature. Across 7 real-world datasets and against 13 baselines, DSHN achieves relative accuracy gains from 2% up to 20%, showing how a principled treatment of directionality in hypergraphs, combined with the expressive power of sheaves, can substantially improve performance.