 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Explanations for Hypergraph Neural Networks
Feb 04, 2026Hypergraph neural networks (HGNNs) effectively model higher-order interactions in many real-world systems but remain difficult to interpret, limiting their deployment in high-stakes settings. We introduce CF-HyperGNNExplainer, a counterfactual explanation method for HGNNs that identifies the minimal structural changes required to alter a model's prediction. The method generates counterfactual hypergraphs using actionable edits limited to removing node-hyperedge incidences or deleting hyperedges, producing concise and structurally meaningful explanations. Experiments on three benchmark datasets show that CF-HyperGNNExplainer generates valid and concise counterfactuals, highlighting the higher-order relations most critical to HGNN decisions.
Evaluating Latent Knowledge of Public Tabular Datasets in Large Language Models
Oct 23, 2025Large Language Models (LLMs) are increasingly evaluated on their ability to reason over structured data, yet such assessments often overlook a crucial confound: dataset contamination. In this work, we investigate whether LLMs exhibit prior knowledge of widely used tabular benchmarks such as Adult Income, Titanic, and others. Through a series of controlled probing experiments, we reveal that contamination effects emerge exclusively for datasets containing strong semantic cues-for instance, meaningful column names or interpretable value categories. In contrast, when such cues are removed or randomized, performance sharply declines to near-random levels. These findings suggest that LLMs' apparent competence on tabular reasoning tasks may, in part, reflect memorization of publicly available datasets rather than genuine generalization. We discuss implications for evaluation protocols and propose strategies to disentangle semantic leakage from authentic reasoning ability in future LLM assessments.
Generalizability vs. Counterfactual Explainability Trade-Off
May 29, 2025In this work, we investigate the relationship between model generalization and counterfactual explainability in supervised learning. We introduce the notion of $\varepsilon$-valid counterfactual probability ($\varepsilon$-VCP) -- the probability of finding perturbations of a data point within its $\varepsilon$-neighborhood that result in a label change. We provide a theoretical analysis of $\varepsilon$-VCP in relation to the geometry of the model's decision boundary, showing that $\varepsilon$-VCP tends to increase with model overfitting. Our findings establish a rigorous connection between poor generalization and the ease of counterfactual generation, revealing an inherent trade-off between generalization and counterfactual explainability. Empirical results validate our theory, suggesting $\varepsilon$-VCP as a practical proxy for quantitatively characterizing overfitting.
One Search Fits All: Pareto-Optimal Eco-Friendly Model Selection
May 02, 2025



The environmental impact of Artificial Intelligence (AI) is emerging as a significant global concern, particularly regarding model training. In this paper, we introduce GREEN (Guided Recommendations of Energy-Efficient Networks), a novel, inference-time approach for recommending Pareto-optimal AI model configurations that optimize validation performance and energy consumption across diverse AI domains and tasks. Our approach directly addresses the limitations of current eco-efficient neural architecture search methods, which are often restricted to specific architectures or tasks. Central to this work is EcoTaskSet, a dataset comprising training dynamics from over 1767 experiments across computer vision, natural language processing, and recommendation systems using both widely used and cutting-edge architectures. Leveraging this dataset and a prediction model, our approach demonstrates effectiveness in selecting the best model configuration based on user preferences. Experimental results show that our method successfully identifies energy-efficient configurations while ensuring competitive performance.
Generalizability through Explainability: Countering Overfitting with Counterfactual Examples
Feb 13, 2025



Overfitting is a well-known issue in machine learning that occurs when a model struggles to generalize its predictions to new, unseen data beyond the scope of its training set. Traditional techniques to mitigate overfitting include early stopping, data augmentation, and regularization. In this work, we demonstrate that the degree of overfitting of a trained model is correlated with the ability to generate counterfactual examples. The higher the overfitting, the easier it will be to find a valid counterfactual example for a randomly chosen input data point. Therefore, we introduce CF-Reg, a novel regularization term in the training loss that controls overfitting by ensuring enough margin between each instance and its corresponding counterfactual. Experiments conducted across multiple datasets and models show that our counterfactual regularizer generally outperforms existing regularization techniques.
Beyond Predictions: A Participatory Framework for Multi-Stakeholder Decision-Making
Feb 12, 2025Conventional decision-support systems, primarily based on supervised learning, focus on outcome prediction models to recommend actions. However, they often fail to account for the complexities of multi-actor environments, where diverse and potentially conflicting stakeholder preferences must be balanced. In this paper, we propose a novel participatory framework that redefines decision-making as a multi-stakeholder optimization problem, capturing each actor's preferences through context-dependent reward functions. Our framework leverages $k$-fold cross-validation to fine-tune user-provided outcome prediction models and evaluate decision strategies, including compromise functions mediating stakeholder trade-offs. We introduce a synthetic scoring mechanism that exploits user-defined preferences across multiple metrics to rank decision-making strategies and identify the optimal decision-maker. The selected decision-maker can then be used to generate actionable recommendations for new data. We validate our framework using two real-world use cases, demonstrating its ability to deliver recommendations that effectively balance multiple metrics, achieving results that are often beyond the scope of purely prediction-based methods. Ablation studies demonstrate that our framework, with its modular, model-agnostic, and inherently transparent design, integrates seamlessly with various predictive models, reward structures, evaluation metrics, and sample sizes, making it particularly suited for complex, high-stakes decision-making contexts.
Natural Language Counterfactual Explanations for Graphs Using Large Language Models
Oct 11, 2024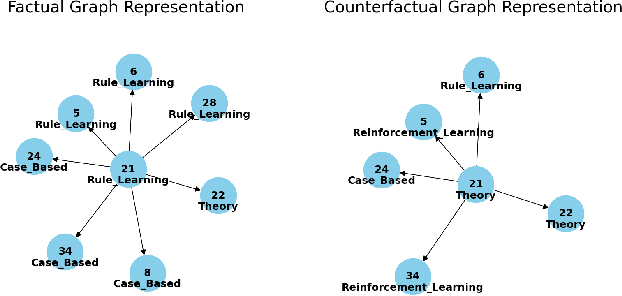


Explainable Artificial Intelligence (XAI) has emerged as a critical area of research to unravel the opaque inner logic of (deep) machine learning models. Among the various XAI techniques proposed in the literature, counterfactual explanations stand out as one of the most promising approaches. However, these ``what-if'' explanations are frequently complex and technical, making them difficult for non-experts to understand and, more broadly, challenging for humans to interpret. To bridge this gap, in this work, we exploit the power of open-source Large Language Models to generate natural language explanations when prompted with valid counterfactual instances produced by state-of-the-art explainers for graph-based models. Experiments across several graph datasets and counterfactual explainers show that our approach effectively produces accurate natural language representations of counterfactual instances, as demonstrated by key performance metrics.
Debiasing Machine Unlearning with Counterfactual Examples
Apr 24, 2024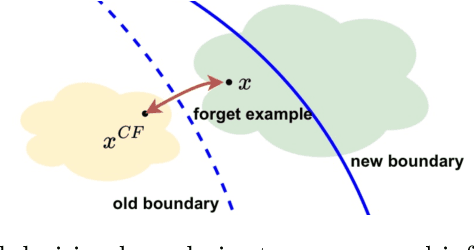

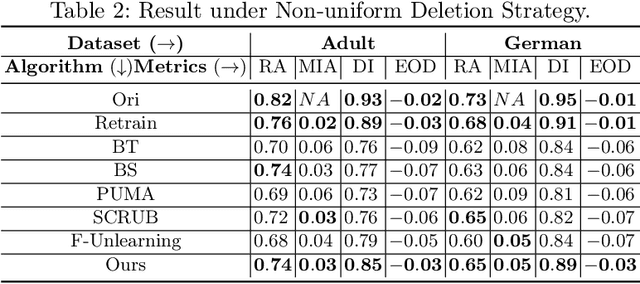
The right to be forgotten (RTBF) seeks to safeguard individuals from the enduring effects of their historical actions by implementing machine-learning techniques. These techniques facilitate the deletion of previously acquired knowledge without requiring extensive model retraining. However, they often overlook a critical issue: unlearning processes bias. This bias emerges from two main sources: (1) data-level bias, characterized by uneven data removal, and (2) algorithm-level bias, which leads to the contamination of the remaining dataset, thereby degrading model accuracy. In this work, we analyze the causal factors behind the unlearning process and mitigate biases at both data and algorithmic levels. Typically, we introduce an intervention-based approach, where knowledge to forget is erased with a debiased dataset. Besides, we guide the forgetting procedure by leveraging counterfactual examples, as they maintain semantic data consistency without hurting performance on the remaining dataset. Experimental results demonstrate that our method outperforms existing machine unlearning baselines on evaluation metrics.
$ abla τ$: Gradient-based and Task-Agnostic machine Unlearning
Mar 21, 2024
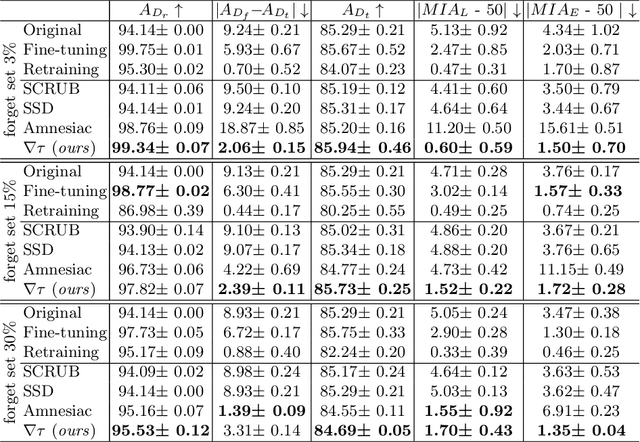
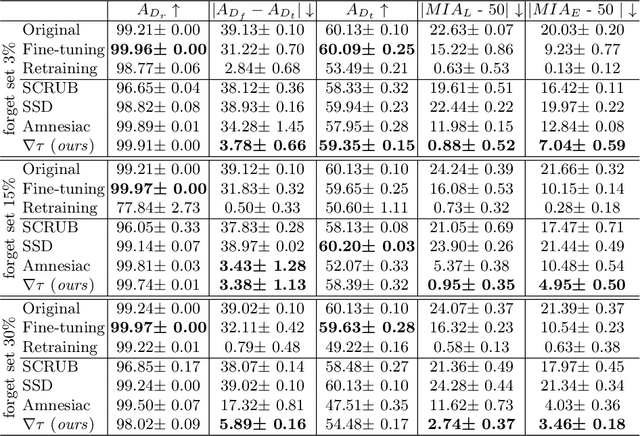
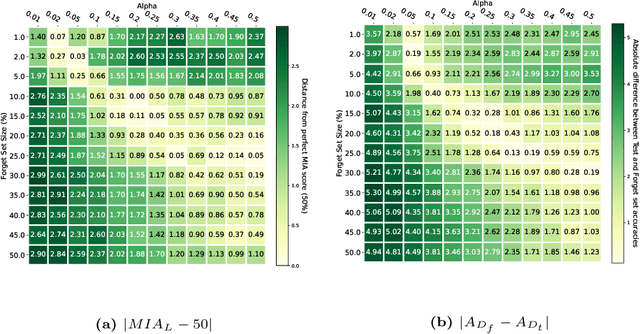
Machine Unlearning, the process of selectively eliminating the influence of certain data examples used during a model's training, has gained significant attention as a means for practitioners to comply with recent data protection regulations. However, existing unlearning methods face critical drawbacks, including their prohibitively high cost, often associated with a large number of hyperparameters, and the limitation of forgetting only relatively small data portions. This often makes retraining the model from scratch a quicker and more effective solution. In this study, we introduce Gradient-based and Task-Agnostic machine Unlearning ($\nabla \tau$), an optimization framework designed to remove the influence of a subset of training data efficiently. It applies adaptive gradient ascent to the data to be forgotten while using standard gradient descent for the remaining data. $\nabla \tau$ offers multiple benefits over existing approaches. It enables the unlearning of large sections of the training dataset (up to 30%). It is versatile, supporting various unlearning tasks (such as subset forgetting or class removal) and applicable across different domains (images, text, etc.). Importantly, $\nabla \tau$ requires no hyperparameter adjustments, making it a more appealing option than retraining the model from scratch. We evaluate our framework's effectiveness using a set of well-established Membership Inference Attack metrics, demonstrating up to 10% enhancements in performance compared to state-of-the-art methods without compromising the original model's accuracy.
Community Membership Hiding as Counterfactual Graph Search via Deep Reinforcement Learning
Oct 13, 2023



Community detection techniques are useful tools for social media platforms to discover tightly connected groups of users who share common interests. However, this functionality often comes at the expense of potentially exposing individuals to privacy breaches by inadvertently revealing their tastes or preferences. Therefore, some users may wish to safeguard their anonymity and opt out of community detection for various reasons, such as affiliation with political or religious organizations. In this study, we address the challenge of community membership hiding, which involves strategically altering the structural properties of a network graph to prevent one or more nodes from being identified by a given community detection algorithm. We tackle this problem by formulating it as a constrained counterfactual graph objective, and we solve it via deep reinforcement learning. We validate the effectiveness of our method through two distinct tasks: node and community deception. Extensive experiments show that our approach overall outperforms existing baselines in both tasks.