 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoBench: Automating LLM Evaluation through Reciprocal Peer Assessment
Oct 26, 2025We present AutoBench, a fully automated and self-sustaining framework for evaluating Large Language Models (LLMs) through reciprocal peer assessment. This paper provides a rigorous scientific validation of the AutoBench methodology, originally developed as an open-source project by eZecute S.R.L.. Unlike static benchmarks that suffer from test-set contamination and limited adaptability, AutoBench dynamically generates novel evaluation tasks while models alternately serve as question generators, contestants, and judges across diverse domains. An iterative weighting mechanism amplifies the influence of consistently reliable evaluators, aggregating peer judgments into consensus-based rankings that reflect collective model agreement. Our experiments demonstrate strong correlations with established benchmarks including MMLU-Pro and GPQA (respectively 78\% and 63\%), validating this peer-driven evaluation paradigm. The multi-judge design significantly outperforms single-judge baselines, confirming that distributed evaluation produces more robust and human-consistent assessments. AutoBench offers a scalable, contamination-resistant alternative to static benchmarks for the continuous evaluation of evolving language models.
Redefining Retrieval Evaluation in the Era of LLMs
Oct 24, 2025Traditional Information Retrieval (IR) metrics, such as nDCG, MAP, and MRR, assume that human users sequentially examine documents with diminishing attention to lower ranks. This assumption breaks down in Retrieval Augmented Generation (RAG) systems, where search results are consumed by Large Language Models (LLMs), which, unlike humans, process all retrieved documents as a whole rather than sequentially. Additionally, traditional IR metrics do not account for related but irrelevant documents that actively degrade generation quality, rather than merely being ignored. Due to these two major misalignments, namely human vs. machine position discount and human relevance vs. machine utility, classical IR metrics do not accurately predict RAG performance. We introduce a utility-based annotation schema that quantifies both the positive contribution of relevant passages and the negative impact of distracting ones. Building on this foundation, we propose UDCG (Utility and Distraction-aware Cumulative Gain), a metric using an LLM-oriented positional discount to directly optimize the correlation with the end-to-end answer accuracy. Experiments on five datasets and six LLMs demonstrate that UDCG improves correlation by up to 36% compared to traditional metrics. Our work provides a critical step toward aligning IR evaluation with LLM consumers and enables more reliable assessment of RAG components
ECLIPSE: Contrastive Dimension Importance Estimation with Pseudo-Irrelevance Feedback for Dense Retrieval
Dec 19, 2024



Recent advances in Information Retrieval have leveraged high-dimensional embedding spaces to improve the retrieval of relevant documents. Moreover, the Manifold Clustering Hypothesis suggests that despite these high-dimensional representations, documents relevant to a query reside on a lower-dimensional, query-dependent manifold. While this hypothesis has inspired new retrieval methods, existing approaches still face challenges in effectively separating non-relevant information from relevant signals. We propose a novel methodology that addresses these limitations by leveraging information from both relevant and non-relevant documents. Our method, ECLIPSE, computes a centroid based on irrelevant documents as a reference to estimate noisy dimensions present in relevant ones, enhancing retrieval performance. Extensive experiments on three in-domain and one out-of-domain benchmarks demonstrate an average improvement of up to 19.50% (resp. 22.35%) in mAP(AP) and 11.42% (resp. 13.10%) in nDCG@10 w.r.t. the DIME-based baseline (resp. the baseline using all dimensions). Our results pave the way for more robust, pseudo-irrelevance-based retrieval systems in future IR research.
A Reproducible Analysis of Sequential Recommender Systems
Aug 07, 2024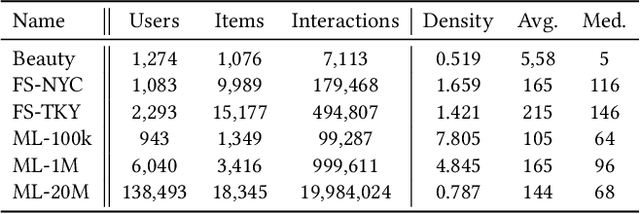
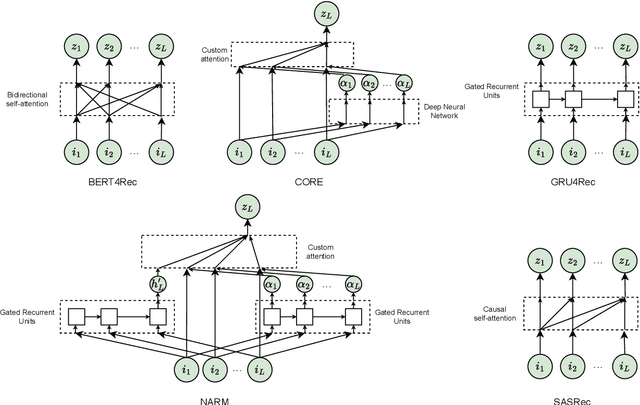

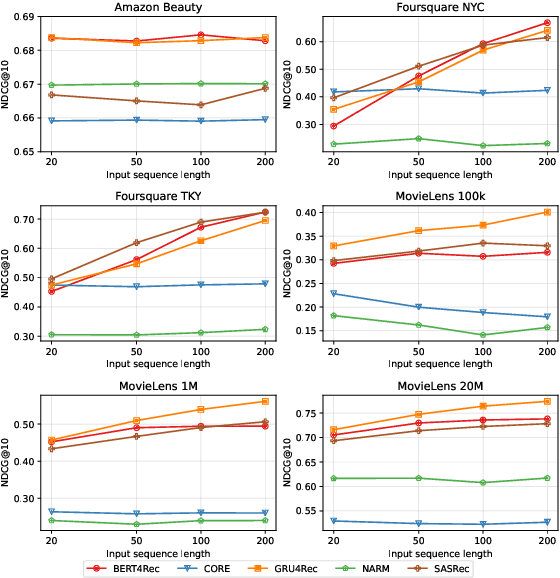
Sequential Recommender Systems (SRSs) have emerged as a highly efficient approach to recommendation systems. By leveraging sequential data, SRSs can identify temporal patterns in user behaviour, significantly improving recommendation accuracy and relevance.Ensuring the reproducibility of these models is paramount for advancing research and facilitating comparisons between them. Existing works exhibit shortcomings in reproducibility and replicability of results, leading to inconsistent statements across papers. Our work fills these gaps by standardising data pre-processing and model implementations, providing a comprehensive code resource, including a framework for developing SRSs and establishing a foundation for consistent and reproducible experimentation. We conduct extensive experiments on several benchmark datasets, comparing various SRSs implemented in our resource. We challenge prevailing performance benchmarks, offering new insights into the SR domain. For instance, SASRec does not consistently outperform GRU4Rec. On the contrary, when the number of model parameters becomes substantial, SASRec starts to clearly dominate all the other SRSs. This discrepancy underscores the significant impact that experimental configuration has on the outcomes and the importance of setting it up to ensure precise and comprehensive results. Failure to do so can lead to significantly flawed conclusions, highlighting the need for rigorous experimental design and analysis in SRS research. Our code is available at https://github.com/antoniopurificato/recsys_repro_conf.
A Tale of Trust and Accuracy: Base vs. Instruct LLMs in RAG Systems
Jun 21, 2024
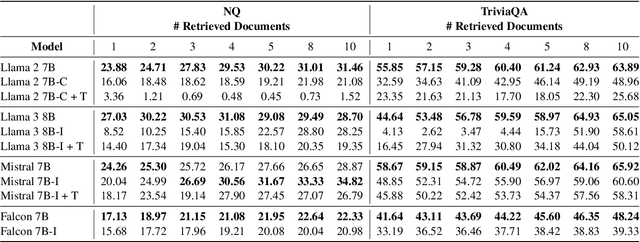
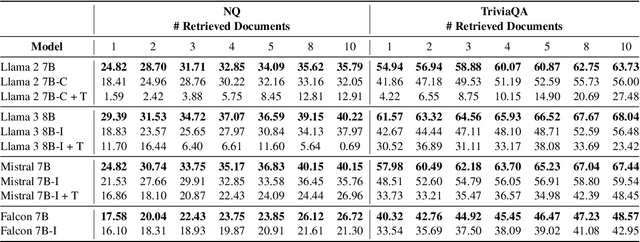
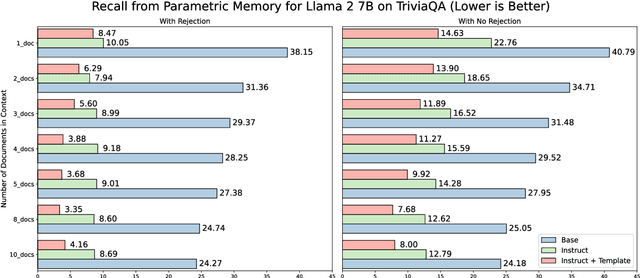
Retrieval Augmented Generation (RAG) represents a significant advancement in artificial intelligence combining a retrieval phase with a generative phase, with the latter typically being powered by large language models (LLMs). The current common practices in RAG involve using "instructed" LLMs, which are fine-tuned with supervised training to enhance their ability to follow instructions and are aligned with human preferences using state-of-the-art techniques. Contrary to popular belief, our study demonstrates that base models outperform their instructed counterparts in RAG tasks by 20% on average under our experimental settings. This finding challenges the prevailing assumptions about the superiority of instructed LLMs in RAG applications. Further investigations reveal a more nuanced situation, questioning fundamental aspects of RAG and suggesting the need for broader discussions on the topic; or, as Fromm would have it, "Seldom is a glance at the statistics enough to understand the meaning of the figures".
TEXT2TASTE: A Versatile Egocentric Vision System for Intelligent Reading Assistance Using Large Language Model
Apr 14, 2024The ability to read, understand and find important information from written text is a critical skill in our daily lives for our independence, comfort and safety. However, a significant part of our society is affected by partial vision impairment, which leads to discomfort and dependency in daily activities. To address the limitations of this part of society, we propose an intelligent reading assistant based on smart glasses with embedded RGB cameras and a Large Language Model (LLM), whose functionality goes beyond corrective lenses. The video recorded from the egocentric perspective of a person wearing the glasses is processed to localise text information using object detection and optical character recognition methods. The LLM processes the data and allows the user to interact with the text and responds to a given query, thus extending the functionality of corrective lenses with the ability to find and summarize knowledge from the text. To evaluate our method, we create a chat-based application that allows the user to interact with the system. The evaluation is conducted in a real-world setting, such as reading menus in a restaurant, and involves four participants. The results show robust accuracy in text retrieval. The system not only provides accurate meal suggestions but also achieves high user satisfaction, highlighting the potential of smart glasses and LLMs in assisting people with special needs.
The Power of Noise: Redefining Retrieval for RAG Systems
Jan 29, 2024



Retrieval-Augmented Generation (RAG) systems represent a significant advancement over traditional Large Language Models (LLMs). RAG systems enhance their generation ability by incorporating external data retrieved through an Information Retrieval (IR) phase, overcoming the limitations of standard LLMs, which are restricted to their pre-trained knowledge and limited context window. Most research in this area has predominantly concentrated on the generative aspect of LLMs within RAG systems. Our study fills this gap by thoroughly and critically analyzing the influence of IR components on RAG systems. This paper analyzes which characteristics a retriever should possess for an effective RAG's prompt formulation, focusing on the type of documents that should be retrieved. We evaluate various elements, such as the relevance of the documents to the prompt, their position, and the number included in the context. Our findings reveal, among other insights, that including irrelevant documents can unexpectedly enhance performance by more than 30% in accuracy, contradicting our initial assumption of diminished quality. These results underscore the need for developing specialized strategies to integrate retrieval with language generation models, thereby laying the groundwork for future research in this field.
Prompt-to-OS (P2OS): Revolutionizing Operating Systems and Human-Computer Interaction with Integrated AI Generative Models
Oct 07, 2023
In this paper, we present a groundbreaking paradigm for human-computer interaction that revolutionizes the traditional notion of an operating system. Within this innovative framework, user requests issued to the machine are handled by an interconnected ecosystem of generative AI models that seamlessly integrate with or even replace traditional software applications. At the core of this paradigm shift are large generative models, such as language and diffusion models, which serve as the central interface between users and computers. This pioneering approach leverages the abilities of advanced language models, empowering users to engage in natural language conversations with their computing devices. Users can articulate their intentions, tasks, and inquiries directly to the system, eliminating the need for explicit commands or complex navigation. The language model comprehends and interprets the user's prompts, generating and displaying contextual and meaningful responses that facilitate seamless and intuitive interactions. This paradigm shift not only streamlines user interactions but also opens up new possibilities for personalized experiences. Generative models can adapt to individual preferences, learning from user input and continuously improving their understanding and response generation. Furthermore, it enables enhanced accessibility, as users can interact with the system using speech or text, accommodating diverse communication preferences. However, this visionary concept raises significant challenges, including privacy, security, trustability, and the ethical use of generative models. Robust safeguards must be in place to protect user data and prevent potential misuse or manipulation of the language model. While the full realization of this paradigm is still far from being achieved, this paper serves as a starting point for envisioning this transformative potential.
RRAML: Reinforced Retrieval Augmented Machine Learning
Jul 27, 2023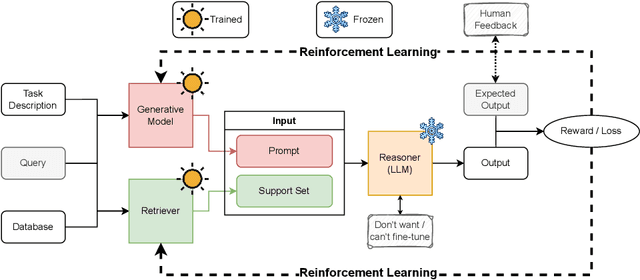
The emergence of large language models (LLMs) has revolutionized machine learning and related fields, showcasing remarkable abilities in comprehending, generating, and manipulating human language. However, their conventional usage through API-based text prompt submissions imposes certain limitations in terms of context constraints and external source availability. To address these challenges, we propose a novel framework called Reinforced Retrieval Augmented Machine Learning (RRAML). RRAML integrates the reasoning capabilities of LLMs with supporting information retrieved by a purpose-built retriever from a vast user-provided database. By leveraging recent advancements in reinforcement learning, our method effectively addresses several critical challenges. Firstly, it circumvents the need for accessing LLM gradients. Secondly, our method alleviates the burden of retraining LLMs for specific tasks, as it is often impractical or impossible due to restricted access to the model and the computational intensity involved. Additionally we seamlessly link the retriever's task with the reasoner, mitigating hallucinations and reducing irrelevant, and potentially damaging retrieved documents. We believe that the research agenda outlined in this paper has the potential to profoundly impact the field of AI, democratizing access to and utilization of LLMs for a wide range of entities.
Fauno: The Italian Large Language Model that will leave you senza parole!
Jun 26, 2023
This paper presents Fauno, the first and largest open-source Italian conversational Large Language Model (LLM). Our goal with Fauno is to democratize the study of LLMs in Italian, demonstrating that obtaining a fine-tuned conversational bot with a single GPU is possible. In addition, we release a collection of datasets for conversational AI in Italian. The datasets on which we fine-tuned Fauno include various topics such as general question answering, computer science, and medical questions. We release our code and datasets on \url{https://github.com/RSTLess-research/Fauno-Italian-LLM}