 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Search Fits All: Pareto-Optimal Eco-Friendly Model Selection
May 02, 2025



The environmental impact of Artificial Intelligence (AI) is emerging as a significant global concern, particularly regarding model training. In this paper, we introduce GREEN (Guided Recommendations of Energy-Efficient Networks), a novel, inference-time approach for recommending Pareto-optimal AI model configurations that optimize validation performance and energy consumption across diverse AI domains and tasks. Our approach directly addresses the limitations of current eco-efficient neural architecture search methods, which are often restricted to specific architectures or tasks. Central to this work is EcoTaskSet, a dataset comprising training dynamics from over 1767 experiments across computer vision, natural language processing, and recommendation systems using both widely used and cutting-edge architectures. Leveraging this dataset and a prediction model, our approach demonstrates effectiveness in selecting the best model configuration based on user preferences. Experimental results show that our method successfully identifies energy-efficient configurations while ensuring competitive performance.
The Role of Fake Users in Sequential Recommender Systems
Oct 13, 2024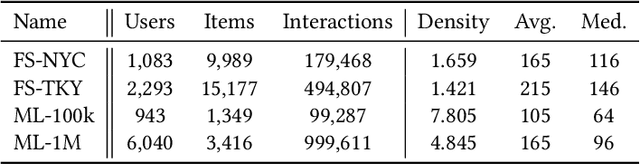
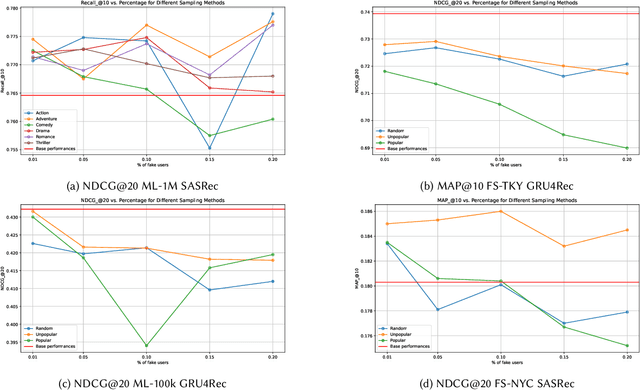
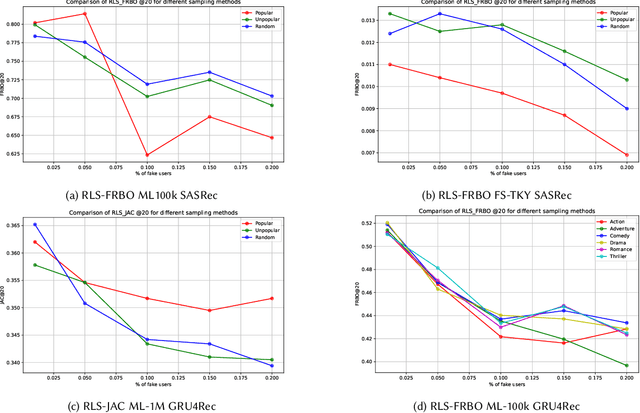
Sequential Recommender Systems (SRSs) are widely used to model user behavior over time, yet their robustness remains an under-explored area of research. In this paper, we conduct an empirical study to assess how the presence of fake users, who engage in random interactions, follow popular or unpopular items, or focus on a single genre, impacts the performance of SRSs in real-world scenarios. We evaluate two SRS models across multiple datasets, using established metrics such as Normalized Discounted Cumulative Gain (NDCG) and Rank Sensitivity List (RLS) to measure performance. While traditional metrics like NDCG remain relatively stable, our findings reveal that the presence of fake users severely degrades RLS metrics, often reducing them to near-zero values. These results highlight the need for further investigation into the effects of fake users on training data and emphasize the importance of developing more resilient SRSs that can withstand different types of adversarial attacks.
A Reproducible Analysis of Sequential Recommender Systems
Aug 07, 2024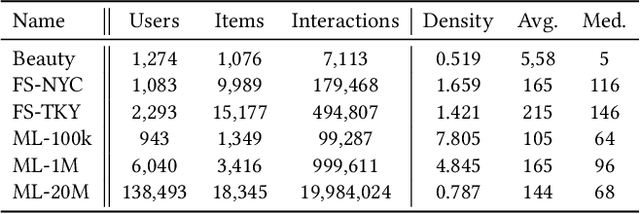
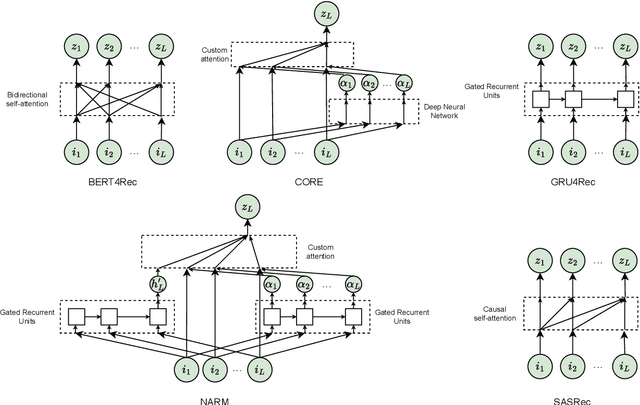

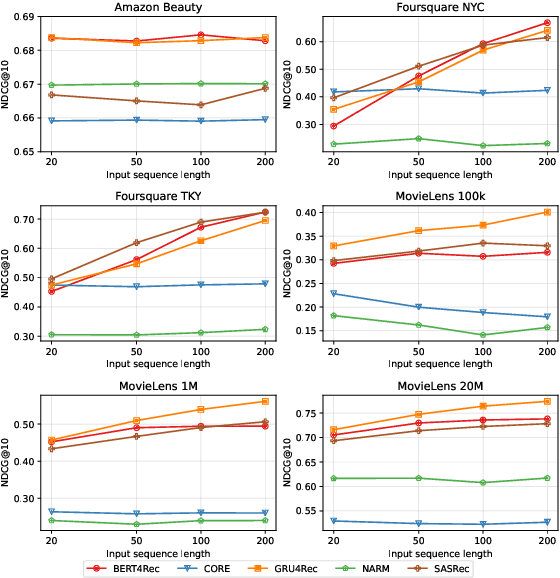
Sequential Recommender Systems (SRSs) have emerged as a highly efficient approach to recommendation systems. By leveraging sequential data, SRSs can identify temporal patterns in user behaviour, significantly improving recommendation accuracy and relevance.Ensuring the reproducibility of these models is paramount for advancing research and facilitating comparisons between them. Existing works exhibit shortcomings in reproducibility and replicability of results, leading to inconsistent statements across papers. Our work fills these gaps by standardising data pre-processing and model implementations, providing a comprehensive code resource, including a framework for developing SRSs and establishing a foundation for consistent and reproducible experimentation. We conduct extensive experiments on several benchmark datasets, comparing various SRSs implemented in our resource. We challenge prevailing performance benchmarks, offering new insights into the SR domain. For instance, SASRec does not consistently outperform GRU4Rec. On the contrary, when the number of model parameters becomes substantial, SASRec starts to clearly dominate all the other SRSs. This discrepancy underscores the significant impact that experimental configuration has on the outcomes and the importance of setting it up to ensure precise and comprehensive results. Failure to do so can lead to significantly flawed conclusions, highlighting the need for rigorous experimental design and analysis in SRS research. Our code is available at https://github.com/antoniopurificato/recsys_repro_conf.
Attention-Map Augmentation for Hypercomplex Breast Cancer Classification
Oct 11, 2023Breast cancer is the most widespread neoplasm among women and early detection of this disease is critical. Deep learning techniques have become of great interest to improve diagnostic performance. Nonetheless, discriminating between malignant and benign masses from whole mammograms remains challenging due to them being almost identical to an untrained eye and the region of interest (ROI) occupying a minuscule portion of the entire image. In this paper, we propose a framework, parameterized hypercomplex attention maps (PHAM), to overcome these problems. Specifically, we deploy an augmentation step based on computing attention maps. Then, the attention maps are used to condition the classification step by constructing a multi-dimensional input comprised of the original breast cancer image and the corresponding attention map. In this step, a parameterized hypercomplex neural network (PHNN) is employed to perform breast cancer classification. The framework offers two main advantages. First, attention maps provide critical information regarding the ROI and allow the neural model to concentrate on it. Second, the hypercomplex architecture has the ability to model local relations between input dimensions thanks to hypercomplex algebra rules, thus properly exploiting the information provided by the attention map. We demonstrate the efficacy of the proposed framework on both mammography images as well as histopathological ones, surpassing attention-based state-of-the-art networks and the real-valued counterpart of our method. The code of our work is available at https://github.com/elelo22/AttentionBCS.
Investigating the Robustness of Sequential Recommender Systems Against Training Data Perturbations: an Empirical Study
Jul 24, 2023Sequential Recommender Systems (SRSs) have been widely used to model user behavior over time, but their robustness in the face of perturbations to training data is a critical issue. In this paper, we conduct an empirical study to investigate the effects of removing items at different positions within a temporally ordered sequence. We evaluate two different SRS models on multiple datasets, measuring their performance using Normalized Discounted Cumulative Gain (NDCG) and Rank Sensitivity List metrics. Our results demonstrate that removing items at the end of the sequence significantly impacts performance, with NDCG decreasing up to 60\%, while removing items from the beginning or middle has no significant effect. These findings highlight the importance of considering the position of the perturbed items in the training data and shall inform the design of more robust SRSs.