 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrimodal Glioma Representation Alignment via Volumetric Contrastive Learning
Jun 12, 2026Glioma grading and survival prediction require the integration of heterogeneous information collected at different spatial and biological scales. Histopathology describes tissue morphology, mRNA expression captures molecular activity, and magnetic resonance imaging provides a non-invasive view of tumor extent and radiological heterogeneity. Existing glioma prognosis models often combine only two of these sources, while their alignment objectives remain mostly pairwise. This paper introduces GLORIA, a novel trimodal framework for GLioma Omics - Radiology - hIstopathology Alignment. GLORIA processes whole-slide image regions, gene-expression profiles, and 3D MRI volumes through modality-specific encoders, projects them into a shared latent space, and aligns them with a Gramian contrastive loss that measures the volume spanned by the three modality embeddings. The aligned representations are fused through a cross-modal gating module and optimized jointly for three-class glioma grading and overall survival prediction. We evaluate GLORIA on a matched TCGA-GBM/LGG and BraTS21 cohort, comprising 132 patients with all three modalities. On the shared trimodal test set, GLORIA improves over the bimodal WSI-mRNA baseline in all the metrics considered.
GRAMformer: Any-Order Modality Interactions via Volumetric Multimodal Cross-Attention
Jun 04, 2026Transformer-based multimodal models rely on attention mechanisms to integrate information across heterogeneous modalities. Despite their success, existing multimodal attention formulations compute their scores through collections of pairwise dot-product interactions or by concatenating all the modalities into the keys, even when multiple modalities should be jointly involved. As a consequence, current approaches either incur quadratic complexity in the number of modalities or fail to explicitly model interactions that depend on the joint configuration of multiple representations. In this work, we introduce the Volumetric Multimodal cross-Attention (VMA), a novel cross-attention mechanism in which attention scores are defined as a function of the joint geometry of a query and multiple modality-specific keys. VMA computes the volume spanned by query and key vectors across multiple modalities, capturing joint multimodal dependencies beyond pairwise similarity, enabling native modeling of any-order modality interactions. We integrate VMA into our novel multimodal transformer architecture, named GRAMformer, explicitly designed to integrate any number of modalities. We evaluate the proposed model on multimodal learning tasks, demonstrating improved effectiveness and efficiency.
Closing the gap in multimodal medical representation alignment
Feb 23, 2026In multimodal learning, CLIP has emerged as the de-facto approach for mapping different modalities into a shared latent space by bringing semantically similar representations closer while pushing apart dissimilar ones. However, CLIP-based contrastive losses exhibit unintended behaviors that negatively impact true semantic alignment, leading to sparse and fragmented latent spaces. This phenomenon, known as the modality gap, has been partially mitigated for standard text and image pairs but remains unknown and unresolved in more complex multimodal settings, such as the medical domain. In this work, we study this phenomenon in the latter case, revealing that the modality gap is present also in medical alignment, and we propose a modality-agnostic framework that closes this gap, ensuring that semantically related representations are more aligned, regardless of their source modality. Our method enhances alignment between radiology images and clinical text, improving cross-modal retrieval and image captioning.
Closing the Modality Gap Aligns Group-Wise Semantics
Jan 26, 2026In multimodal learning, CLIP has been recognized as the \textit{de facto} method for learning a shared latent space across multiple modalities, placing similar representations close to each other and moving them away from dissimilar ones. Although CLIP-based losses effectively align modalities at the semantic level, the resulting latent spaces often remain only partially shared, revealing a structural mismatch known as the modality gap. While the necessity of addressing this phenomenon remains debated, particularly given its limited impact on instance-wise tasks (e.g., retrieval), we prove that its influence is instead strongly pronounced in group-level tasks (e.g., clustering). To support this claim, we introduce a novel method designed to consistently reduce this discrepancy in two-modal settings, with a straightforward extension to the general $n$-modal case. Through our extensive evaluation, we demonstrate our novel insight: while reducing the gap provides only marginal or inconsistent improvements in traditional instance-wise tasks, it significantly enhances group-wise tasks. These findings may reshape our understanding of the modality gap, highlighting its key role in improving performance on tasks requiring semantic grouping.
Quaternion Wavelet-Conditioned Diffusion Models for Image Super-Resolution
May 05, 2025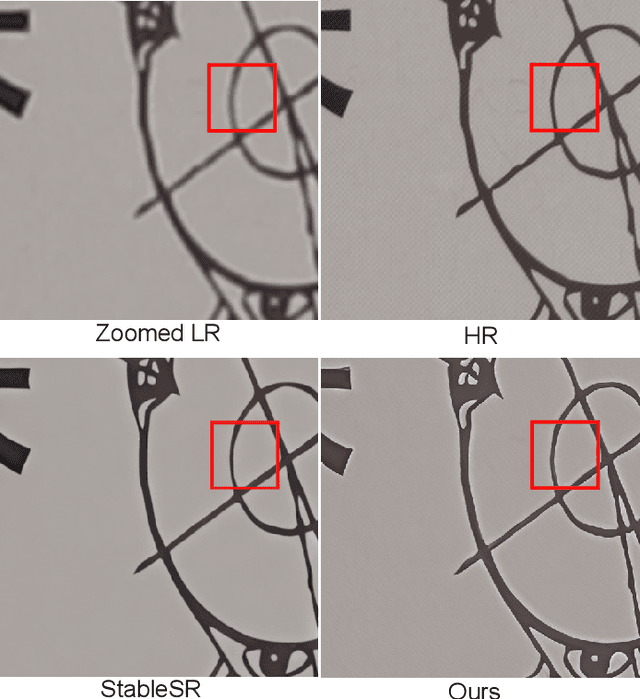
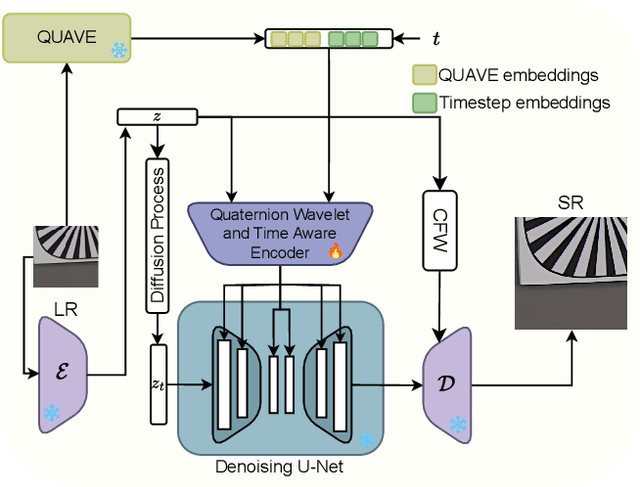

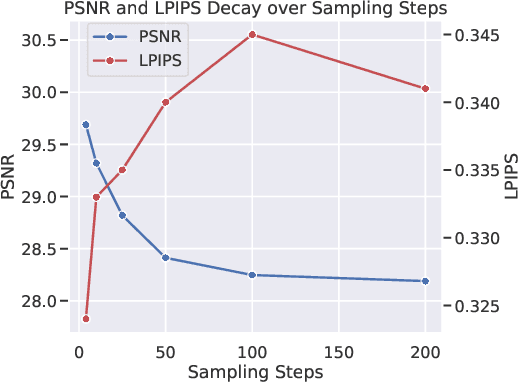
Image Super-Resolution is a fundamental problem in computer vision with broad applications spacing from medical imaging to satellite analysis. The ability to reconstruct high-resolution images from low-resolution inputs is crucial for enhancing downstream tasks such as object detection and segmentation. While deep learning has significantly advanced SR, achieving high-quality reconstructions with fine-grained details and realistic textures remains challenging, particularly at high upscaling factors. Recent approaches leveraging diffusion models have demonstrated promising results, yet they often struggle to balance perceptual quality with structural fidelity. In this work, we introduce ResQu a novel SR framework that integrates a quaternion wavelet preprocessing framework with latent diffusion models, incorporating a new quaternion wavelet- and time-aware encoder. Unlike prior methods that simply apply wavelet transforms within diffusion models, our approach enhances the conditioning process by exploiting quaternion wavelet embeddings, which are dynamically integrated at different stages of denoising. Furthermore, we also leverage the generative priors of foundation models such as Stable Diffusion. Extensive experiments on domain-specific datasets demonstrate that our method achieves outstanding SR results, outperforming in many cases existing approaches in perceptual quality and standard evaluation metrics. The code will be available after the revision process.
Beyond Answers: How LLMs Can Pursue Strategic Thinking in Education
Apr 07, 2025


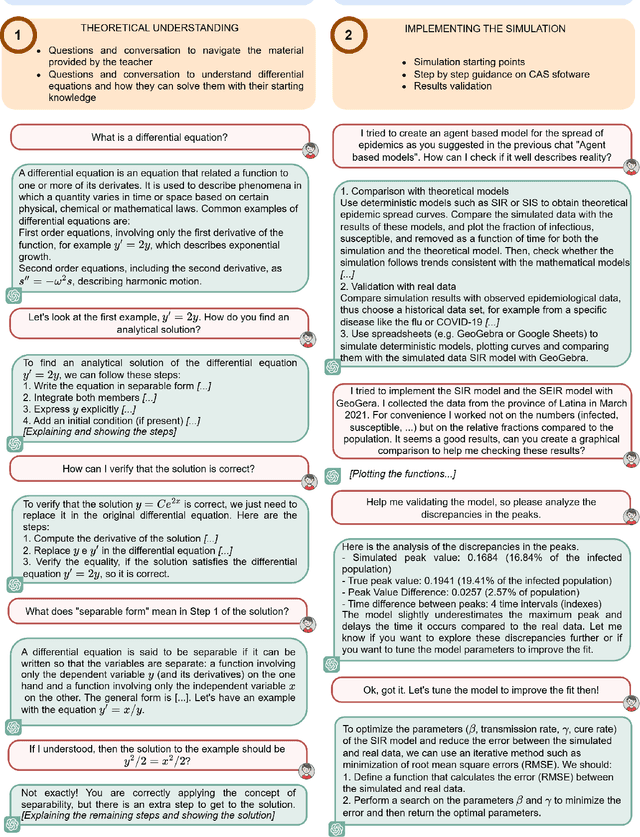
Artificial Intelligence (AI) holds transformative potential in education, enabling personalized learning, enhancing inclusivity, and encouraging creativity and curiosity. In this paper, we explore how Large Language Models (LLMs) can act as both patient tutors and collaborative partners to enhance education delivery. As tutors, LLMs personalize learning by offering step-by-step explanations and addressing individual needs, making education more inclusive for students with diverse backgrounds or abilities. As collaborators, they expand students' horizons, supporting them in tackling complex, real-world problems and co-creating innovative projects. However, to fully realize these benefits, LLMs must be leveraged not as tools for providing direct solutions but rather to guide students in developing resolving strategies and finding learning paths together. Therefore, a strong emphasis should be placed on educating students and teachers on the successful use of LLMs to ensure their effective integration into classrooms. Through practical examples and real-world case studies, this paper illustrates how LLMs can make education more inclusive and engaging while empowering students to reach their full potential.
Stable-V2A: Synthesis of Synchronized Sound Effects with Temporal and Semantic Controls
Dec 19, 2024



Sound designers and Foley artists usually sonorize a scene, such as from a movie or video game, by manually annotating and sonorizing each action of interest in the video. In our case, the intent is to leave full creative control to sound designers with a tool that allows them to bypass the more repetitive parts of their work, thus being able to focus on the creative aspects of sound production. We achieve this presenting Stable-V2A, a two-stage model consisting of: an RMS-Mapper that estimates an envelope representative of the audio characteristics associated with the input video; and Stable-Foley, a diffusion model based on Stable Audio Open that generates audio semantically and temporally aligned with the target video. Temporal alignment is guaranteed by the use of the envelope as a ControlNet input, while semantic alignment is achieved through the use of sound representations chosen by the designer as cross-attention conditioning of the diffusion process. We train and test our model on Greatest Hits, a dataset commonly used to evaluate V2A models. In addition, to test our model on a case study of interest, we introduce Walking The Maps, a dataset of videos extracted from video games depicting animated characters walking in different locations. Samples and code available on our demo page at https://ispamm.github.io/Stable-V2A.
Gramian Multimodal Representation Learning and Alignment
Dec 16, 2024



Human perception integrates multiple modalities, such as vision, hearing, and language, into a unified understanding of the surrounding reality. While recent multimodal models have achieved significant progress by aligning pairs of modalities via contrastive learning, their solutions are unsuitable when scaling to multiple modalities. These models typically align each modality to a designated anchor without ensuring the alignment of all modalities with each other, leading to suboptimal performance in tasks requiring a joint understanding of multiple modalities. In this paper, we structurally rethink the pairwise conventional approach to multimodal learning and we present the novel Gramian Representation Alignment Measure (GRAM), which overcomes the above-mentioned limitations. GRAM learns and then aligns $n$ modalities directly in the higher-dimensional space in which modality embeddings lie by minimizing the Gramian volume of the $k$-dimensional parallelotope spanned by the modality vectors, ensuring the geometric alignment of all modalities simultaneously. GRAM can replace cosine similarity in any downstream method, holding for 2 to $n$ modality and providing more meaningful alignment with respect to previous similarity measures. The novel GRAM-based contrastive loss function enhances the alignment of multimodal models in the higher-dimensional embedding space, leading to new state-of-the-art performance in downstream tasks such as video-audio-text retrieval and audio-video classification. The project page, the code, and the pretrained models are available at https://ispamm.github.io/GRAM/.
A Wavelet Diffusion GAN for Image Super-Resolution
Oct 23, 2024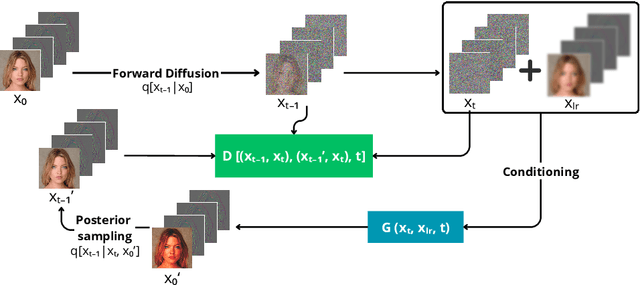
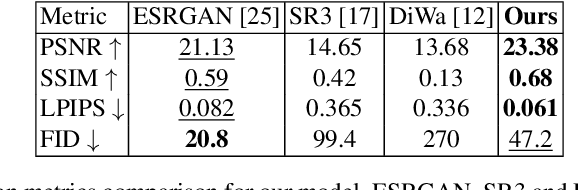
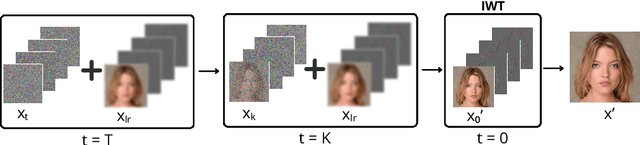

In recent years, diffusion models have emerged as a superior alternative to generative adversarial networks (GANs) for high-fidelity image generation, with wide applications in text-to-image generation, image-to-image translation, and super-resolution. However, their real-time feasibility is hindered by slow training and inference speeds. This study addresses this challenge by proposing a wavelet-based conditional Diffusion GAN scheme for Single-Image Super-Resolution (SISR). Our approach utilizes the diffusion GAN paradigm to reduce the timesteps required by the reverse diffusion process and the Discrete Wavelet Transform (DWT) to achieve dimensionality reduction, decreasing training and inference times significantly. The results of an experimental validation on the CelebA-HQ dataset confirm the effectiveness of our proposed scheme. Our approach outperforms other state-of-the-art methodologies successfully ensuring high-fidelity output while overcoming inherent drawbacks associated with diffusion models in time-sensitive applications.
Lightweight Diffusion Models for Resource-Constrained Semantic Communication
Oct 03, 2024



Recently, generative semantic communication models have proliferated as they are revolutionizing semantic communication frameworks, improving their performance, and opening the way to novel applications. Despite their impressive ability to regenerate content from the compressed semantic information received, generative models pose crucial challenges for communication systems in terms of high memory footprints and heavy computational load. In this paper, we present a novel Quantized GEnerative Semantic COmmunication framework, Q-GESCO. The core method of Q-GESCO is a quantized semantic diffusion model capable of regenerating transmitted images from the received semantic maps while simultaneously reducing computational load and memory footprint thanks to the proposed post-training quantization technique. Q-GESCO is robust to different channel noises and obtains comparable performance to the full precision counterpart in different scenarios saving up to 75% memory and 79% floating point operations. This allows resource-constrained devices to exploit the generative capabilities of Q-GESCO, widening the range of applications and systems for generative semantic communication frameworks. The code is available at https://github.com/ispamm/Q-GESCO.