 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable-V2A: Synthesis of Synchronized Sound Effects with Temporal and Semantic Controls
Dec 19, 2024



Sound designers and Foley artists usually sonorize a scene, such as from a movie or video game, by manually annotating and sonorizing each action of interest in the video. In our case, the intent is to leave full creative control to sound designers with a tool that allows them to bypass the more repetitive parts of their work, thus being able to focus on the creative aspects of sound production. We achieve this presenting Stable-V2A, a two-stage model consisting of: an RMS-Mapper that estimates an envelope representative of the audio characteristics associated with the input video; and Stable-Foley, a diffusion model based on Stable Audio Open that generates audio semantically and temporally aligned with the target video. Temporal alignment is guaranteed by the use of the envelope as a ControlNet input, while semantic alignment is achieved through the use of sound representations chosen by the designer as cross-attention conditioning of the diffusion process. We train and test our model on Greatest Hits, a dataset commonly used to evaluate V2A models. In addition, to test our model on a case study of interest, we introduce Walking The Maps, a dataset of videos extracted from video games depicting animated characters walking in different locations. Samples and code available on our demo page at https://ispamm.github.io/Stable-V2A.
Naturalistic Music Decoding from EEG Data via Latent Diffusion Models
May 17, 2024In this article, we explore the potential of using latent diffusion models, a family of powerful generative models, for the task of reconstructing naturalistic music from electroencephalogram (EEG) recordings. Unlike simpler music with limited timbres, such as MIDI-generated tunes or monophonic pieces, the focus here is on intricate music featuring a diverse array of instruments, voices, and effects, rich in harmonics and timbre. This study represents an initial foray into achieving general music reconstruction of high-quality using non-invasive EEG data, employing an end-to-end training approach directly on raw data without the need for manual pre-processing and channel selection. We train our models on the public NMED-T dataset and perform quantitative evaluation proposing neural embedding-based metrics. We additionally perform song classification based on the generated tracks. Our work contributes to the ongoing research in neural decoding and brain-computer interfaces, offering insights into the feasibility of using EEG data for complex auditory information reconstruction.
COCOLA: Coherence-Oriented Contrastive Learning of Musical Audio Representations
Apr 29, 2024



We present COCOLA (Coherence-Oriented Contrastive Learning for Audio), a contrastive learning method for musical audio representations that captures the harmonic and rhythmic coherence between samples. Our method operates at the level of stems (or their combinations) composing music tracks and allows the objective evaluation of compositional models for music in the task of accompaniment generation. We also introduce a new baseline for compositional music generation called CompoNet, based on ControlNet, generalizing the tasks of MSDM, and quantify it against the latter using COCOLA. We release all models trained on public datasets containing separate stems (MUSDB18-HQ, MoisesDB, Slakh2100, and CocoChorales).
Generalized Multi-Source Inference for Text Conditioned Music Diffusion Models
Mar 18, 2024



Multi-Source Diffusion Models (MSDM) allow for compositional musical generation tasks: generating a set of coherent sources, creating accompaniments, and performing source separation. Despite their versatility, they require estimating the joint distribution over the sources, necessitating pre-separated musical data, which is rarely available, and fixing the number and type of sources at training time. This paper generalizes MSDM to arbitrary time-domain diffusion models conditioned on text embeddings. These models do not require separated data as they are trained on mixtures, can parameterize an arbitrary number of sources, and allow for rich semantic control. We propose an inference procedure enabling the coherent generation of sources and accompaniments. Additionally, we adapt the Dirac separator of MSDM to perform source separation. We experiment with diffusion models trained on Slakh2100 and MTG-Jamendo, showcasing competitive generation and separation results in a relaxed data setting.
Zero-Shot Duet Singing Voices Separation with Diffusion Models
Nov 13, 2023In recent studies, diffusion models have shown promise as priors for solving audio inverse problems. These models allow us to sample from the posterior distribution of a target signal given an observed signal by manipulating the diffusion process. However, when separating audio sources of the same type, such as duet singing voices, the prior learned by the diffusion process may not be sufficient to maintain the consistency of the source identity in the separated audio. For example, the singer may change from one to another occasionally. Tackling this problem will be useful for separating sources in a choir, or a mixture of multiple instruments with similar timbre, without acquiring large amounts of paired data. In this paper, we examine this problem in the context of duet singing voices separation, and propose a method to enforce the coherency of singer identity by splitting the mixture into overlapping segments and performing posterior sampling in an auto-regressive manner, conditioning on the previous segment. We evaluate the proposed method on the MedleyVox dataset and show that the proposed method outperforms the naive posterior sampling baseline. Our source code and the pre-trained model are publicly available at https://github.com/yoyololicon/duet-svs-diffusion.
SyncFusion: Multimodal Onset-synchronized Video-to-Audio Foley Synthesis
Oct 23, 2023Sound design involves creatively selecting, recording, and editing sound effects for various media like cinema, video games, and virtual/augmented reality. One of the most time-consuming steps when designing sound is synchronizing audio with video. In some cases, environmental recordings from video shoots are available, which can aid in the process. However, in video games and animations, no reference audio exists, requiring manual annotation of event timings from the video. We propose a system to extract repetitive actions onsets from a video, which are then used - in conjunction with audio or textual embeddings - to condition a diffusion model trained to generate a new synchronized sound effects audio track. In this way, we leave complete creative control to the sound designer while removing the burden of synchronization with video. Furthermore, editing the onset track or changing the conditioning embedding requires much less effort than editing the audio track itself, simplifying the sonification process. We provide sound examples, source code, and pretrained models to faciliate reproducibility
Accelerating Transformer Inference for Translation via Parallel Decoding
May 17, 2023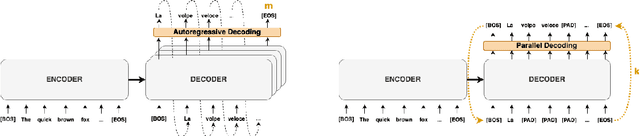
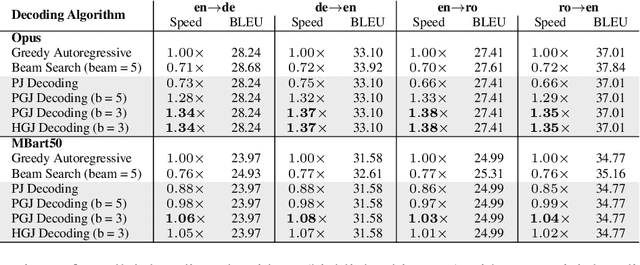

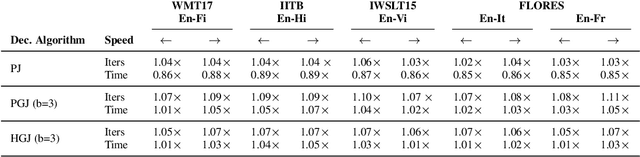
Autoregressive decoding limits the efficiency of transformers for Machine Translation (MT). The community proposed specific network architectures and learning-based methods to solve this issue, which are expensive and require changes to the MT model, trading inference speed at the cost of the translation quality. In this paper, we propose to address the problem from the point of view of decoding algorithms, as a less explored but rather compelling direction. We propose to reframe the standard greedy autoregressive decoding of MT with a parallel formulation leveraging Jacobi and Gauss-Seidel fixed-point iteration methods for fast inference. This formulation allows to speed up existing models without training or modifications while retaining translation quality. We present three parallel decoding algorithms and test them on different languages and models showing how the parallelization introduces a speedup up to 38% w.r.t. the standard autoregressive decoding and nearly 2x when scaling the method on parallel resources. Finally, we introduce a decoding dependency graph visualizer (DDGviz) that let us see how the model has learned the conditional dependence between tokens and inspect the decoding procedure.
Multi-Source Diffusion Models for Simultaneous Music Generation and Separation
Feb 07, 2023



In this work, we define a diffusion-based generative model capable of both music synthesis and source separation by learning the score of the joint probability density of sources sharing a context. Alongside the classic total inference tasks (i.e. generating a mixture, separating the sources), we also introduce and experiment on the partial inference task of source imputation, where we generate a subset of the sources given the others (e.g., play a piano track that goes well with the drums). Additionally, we introduce a novel inference method for the separation task. We train our model on Slakh2100, a standard dataset for musical source separation, provide qualitative results in the generation settings, and showcase competitive quantitative results in the separation setting. Our method is the first example of a single model that can handle both generation and separation tasks, thus representing a step toward general audio models.
Latent Autoregressive Source Separation
Jan 09, 2023Autoregressive models have achieved impressive results over a wide range of domains in terms of generation quality and downstream task performance. In the continuous domain, a key factor behind this success is the usage of quantized latent spaces (e.g., obtained via VQ-VAE autoencoders), which allow for dimensionality reduction and faster inference times. However, using existing pre-trained models to perform new non-trivial tasks is difficult since it requires additional fine-tuning or extensive training to elicit prompting. This paper introduces LASS as a way to perform vector-quantized Latent Autoregressive Source Separation (i.e., de-mixing an input signal into its constituent sources) without requiring additional gradient-based optimization or modifications of existing models. Our separation method relies on the Bayesian formulation in which the autoregressive models are the priors, and a discrete (non-parametric) likelihood function is constructed by performing frequency counts over latent sums of addend tokens. We test our method on images and audio with several sampling strategies (e.g., ancestral, beam search) showing competitive results with existing approaches in terms of separation quality while offering at the same time significant speedups in terms of inference time and scalability to higher dimensional data.
Unsupervised Source Separation via Bayesian Inference in the Latent Domain
Oct 11, 2021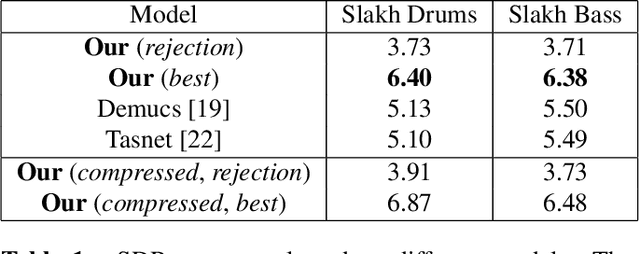
State of the art audio source separation models rely on supervised data-driven approaches, which can be expensive in terms of labeling resources. On the other hand, approaches for training these models without any direct supervision are typically high-demanding in terms of memory and time requirements, and remain impractical to be used at inference time. We aim to tackle these limitations by proposing a simple yet effective unsupervised separation algorithm, which operates directly on a latent representation of time-domain signals. Our algorithm relies on deep Bayesian priors in the form of pre-trained autoregressive networks to model the probability distributions of each source. We leverage the low cardinality of the discrete latent space, trained with a novel loss term imposing a precise arithmetic structure on it, to perform exact Bayesian inference without relying on an approximation strategy. We validate our approach on the Slakh dataset arXiv:1909.08494, demonstrating results in line with state of the art supervised approaches while requiring fewer resources with respect to other unsupervised methods.