 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpectation and Acoustic Neural Network Representations Enhance Music Identification from Brain Activity
Mar 03, 2026During music listening, cortical activity encodes both acoustic and expectation-related information. Prior work has shown that ANN representations resemble cortical representations and can serve as supervisory signals for EEG recognition. Here we show that distinguishing acoustic and expectation-related ANN representations as teacher targets improves EEG-based music identification. Models pretrained to predict either representation outperform non-pretrained baselines, and combining them yields complementary gains that exceed strong seed ensembles formed by varying random initializations. These findings show that teacher representation type shapes downstream performance and that representation learning can be guided by neural encoding. This work points toward advances in predictive music cognition and neural decoding. Our expectation representation, computed directly from raw signals without manual labels, reflects predictive structure beyond onset or pitch, enabling investigation of multilayer predictive encoding across diverse stimuli. Its scalability to large, diverse datasets further suggests potential for developing general-purpose EEG models grounded in cortical encoding principles.
PF-D2M: A Pose-free Diffusion Model for Universal Dance-to-Music Generation
Jan 22, 2026Dance-to-music generation aims to generate music that is aligned with dance movements. Existing approaches typically rely on body motion features extracted from a single human dancer and limited dance-to-music datasets, which restrict their performance and applicability to real-world scenarios involving multiple dancers and non-human dancers. In this paper, we propose PF-D2M, a universal diffusion-based dance-to-music generation model that incorporates visual features extracted from dance videos. PF-D2M is trained with a progressive training strategy that effectively addresses data scarcity and generalization challenges. Both objective and subjective evaluations show that PF-D2M achieves state-of-the-art performance in dance-music alignment and music quality.
Towards Realistic Synthetic Data for Automatic Drum Transcription
Jan 14, 2026Deep learning models define the state-of-the-art in Automatic Drum Transcription (ADT), yet their performance is contingent upon large-scale, paired audio-MIDI datasets, which are scarce. Existing workarounds that use synthetic data often introduce a significant domain gap, as they typically rely on low-fidelity SoundFont libraries that lack acoustic diversity. While high-quality one-shot samples offer a better alternative, they are not available in a standardized, large-scale format suitable for training. This paper introduces a new paradigm for ADT that circumvents the need for paired audio-MIDI training data. Our primary contribution is a semi-supervised method to automatically curate a large and diverse corpus of one-shot drum samples from unlabeled audio sources. We then use this corpus to synthesize a high-quality dataset from MIDI files alone, which we use to train a sequence-to-sequence transcription model. We evaluate our model on the ENST and MDB test sets, where it achieves new state-of-the-art results, significantly outperforming both fully supervised methods and previous synthetic-data approaches. The code for reproducing our experiments is publicly available at https://github.com/pier-maker92/ADT_STR
Predicting Artificial Neural Network Representations to Learn Recognition Model for Music Identification from Brain Recordings
Dec 20, 2024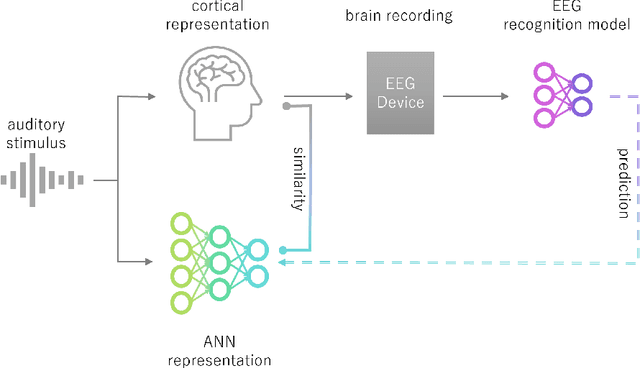
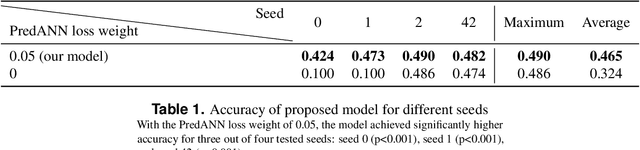
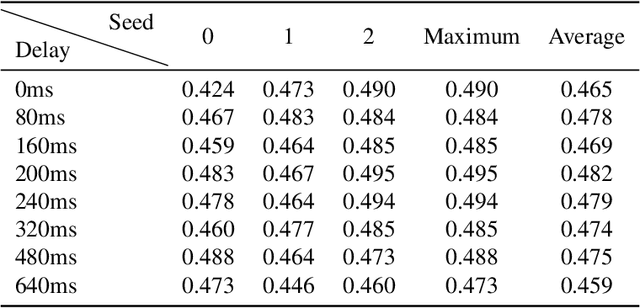
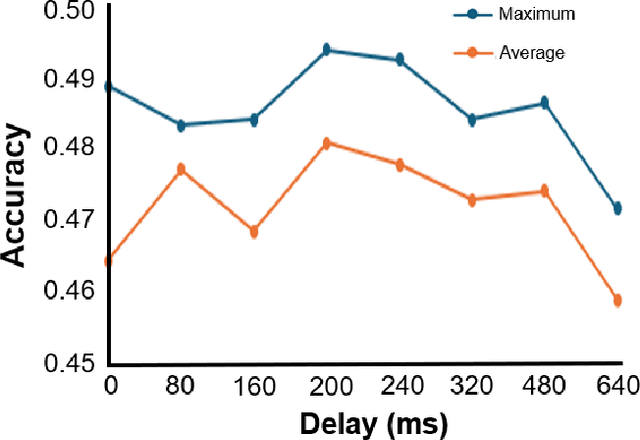
Recent studies have demonstrated that the representations of artificial neural networks (ANNs) can exhibit notable similarities to cortical representations when subjected to identical auditory sensory inputs. In these studies, the ability to predict cortical representations is probed by regressing from ANN representations to cortical representations. Building upon this concept, our approach reverses the direction of prediction: we utilize ANN representations as a supervisory signal to train recognition models using noisy brain recordings obtained through non-invasive measurements. Specifically, we focus on constructing a recognition model for music identification, where electroencephalography (EEG) brain recordings collected during music listening serve as input. By training an EEG recognition model to predict ANN representations-representations associated with music identification-we observed a substantial improvement in classification accuracy. This study introduces a novel approach to developing recognition models for brain recordings in response to external auditory stimuli. It holds promise for advancing brain-computer interfaces (BCI), neural decoding techniques, and our understanding of music cognition. Furthermore, it provides new insights into the relationship between auditory brain activity and ANN representations.
Music Foundation Model as Generic Booster for Music Downstream Tasks
Nov 05, 2024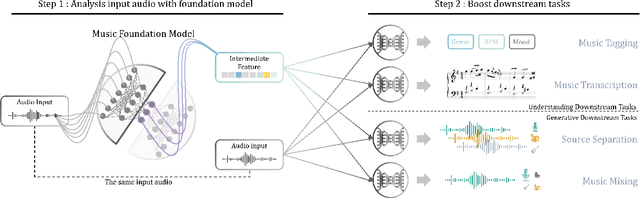


We demonstrate the efficacy of using intermediate representations from a single foundation model to enhance various music downstream tasks. We introduce SoniDo, a music foundation model (MFM) designed to extract hierarchical features from target music samples. By leveraging hierarchical intermediate features, SoniDo constrains the information granularity, leading to improved performance across various downstream tasks including both understanding and generative tasks. We specifically evaluated this approach on representative tasks such as music tagging, music transcription, music source separation, and music mixing. Our results reveal that the features extracted from foundation models provide valuable enhancements in training downstream task models. This highlights the capability of using features extracted from music foundation models as a booster for downstream tasks. Our approach not only benefits existing task-specific models but also supports music downstream tasks constrained by data scarcity. This paves the way for more effective and accessible music processing solutions.
Annotation-Free MIDI-to-Audio Synthesis via Concatenative Synthesis and Generative Refinement
Oct 22, 2024
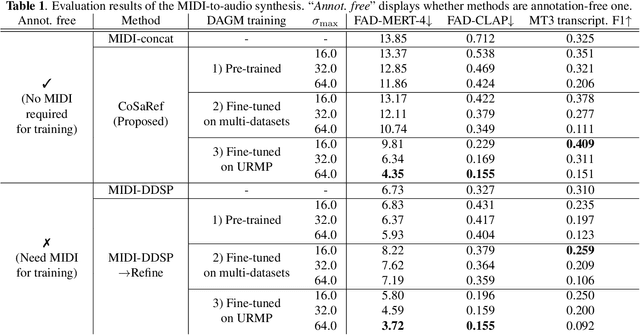
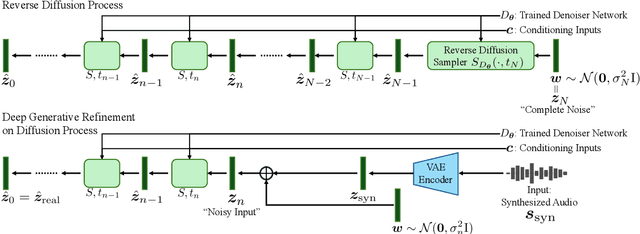
Recent MIDI-to-audio synthesis methods have employed deep neural networks to successfully generate high-quality and expressive instrumental tracks. However, these methods require MIDI annotations for supervised training, limiting the diversity of the output audio in terms of instrument timbres, and expression styles. We propose CoSaRef, a MIDI-to-audio synthesis method that can be developed without MIDI-audio paired datasets. CoSaRef first performs concatenative synthesis based on MIDI inputs and then refines the resulting audio into realistic tracks using a diffusion-based deep generative model trained on audio-only datasets. This approach enhances the diversity of audio timbres and expression styles. It also allows for control over the output timbre based on audio sample selection, similar to traditional functions in digital audio workstations. Experiments show that while inherently capable of generating general tracks with high control over timbre, CoSaRef can also perform comparably to conventional methods in generating realistic audio.
Music Proofreading with RefinPaint: Where and How to Modify Compositions given Context
Jul 12, 2024
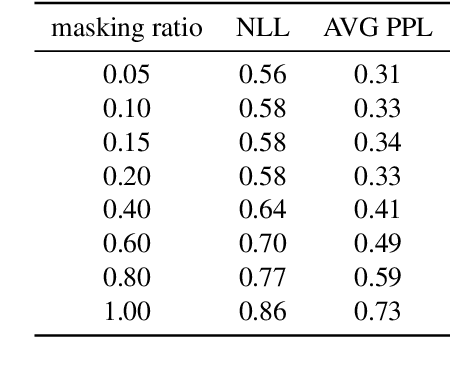
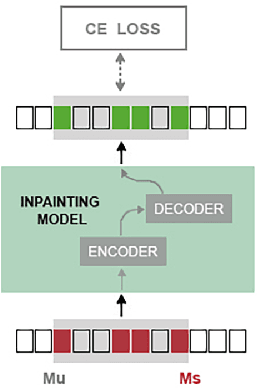
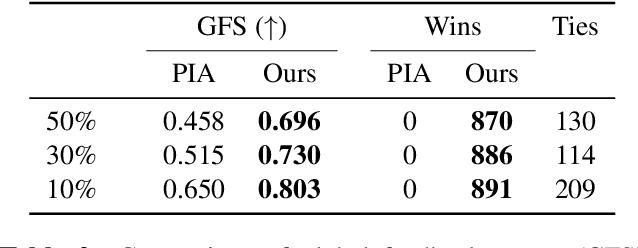
Autoregressive generative transformers are key in music generation, producing coherent compositions but facing challenges in human-machine collaboration. We propose RefinPaint, an iterative technique that improves the sampling process. It does this by identifying the weaker music elements using a feedback model, which then informs the choices for resampling by an inpainting model. This dual-focus methodology not only facilitates the machine's ability to improve its automatic inpainting generation through repeated cycles but also offers a valuable tool for humans seeking to refine their compositions with automatic proofreading. Experimental results suggest RefinPaint's effectiveness in inpainting and proofreading tasks, demonstrating its value for refining music created by both machines and humans. This approach not only facilitates creativity but also aids amateur composers in improving their work.
A Preliminary Investigation on Flexible Singing Voice Synthesis Through Decomposed Framework with Inferrable Features
Jul 12, 2024We investigate the feasibility of a singing voice synthesis (SVS) system by using a decomposed framework to improve flexibility in generating singing voices. Due to data-driven approaches, SVS performs a music score-to-waveform mapping; however, the direct mapping limits control, such as being able to only synthesize in the language or the singers present in the labeled singing datasets. As collecting large singing datasets labeled with music scores is an expensive task, we investigate an alternative approach by decomposing the SVS system and inferring different singing voice features. We decompose the SVS system into three-stage modules of linguistic, pitch contour, and synthesis, in which singing voice features such as linguistic content, F0, voiced/unvoiced, singer embeddings, and loudness are directly inferred from audio. Through this decomposed framework, we show that we can alleviate the labeled dataset requirements, adapt to different languages or singers, and inpaint the lyrical content of singing voices. Our investigations show that the framework has the potential to reach state-of-the-art in SVS, even though the model has additional functionality and improved flexibility. The comprehensive analysis of our investigated framework's current capabilities sheds light on the ways the research community can achieve a flexible and multifunctional SVS system.
Naturalistic Music Decoding from EEG Data via Latent Diffusion Models
May 17, 2024In this article, we explore the potential of using latent diffusion models, a family of powerful generative models, for the task of reconstructing naturalistic music from electroencephalogram (EEG) recordings. Unlike simpler music with limited timbres, such as MIDI-generated tunes or monophonic pieces, the focus here is on intricate music featuring a diverse array of instruments, voices, and effects, rich in harmonics and timbre. This study represents an initial foray into achieving general music reconstruction of high-quality using non-invasive EEG data, employing an end-to-end training approach directly on raw data without the need for manual pre-processing and channel selection. We train our models on the public NMED-T dataset and perform quantitative evaluation proposing neural embedding-based metrics. We additionally perform song classification based on the generated tracks. Our work contributes to the ongoing research in neural decoding and brain-computer interfaces, offering insights into the feasibility of using EEG data for complex auditory information reconstruction.
A Computational Analysis of Lyric Similarity Perception
Apr 02, 2024In musical compositions that include vocals, lyrics significantly contribute to artistic expression. Consequently, previous studies have introduced the concept of a recommendation system that suggests lyrics similar to a user's favorites or personalized preferences, aiding in the discovery of lyrics among millions of tracks. However, many of these systems do not fully consider human perceptions of lyric similarity, primarily due to limited research in this area. To bridge this gap, we conducted a comparative analysis of computational methods for modeling lyric similarity with human perception. Results indicated that computational models based on similarities between embeddings from pre-trained BERT-based models, the audio from which the lyrics are derived, and phonetic components are indicative of perceptual lyric similarity. This finding underscores the importance of semantic, stylistic, and phonetic similarities in human perception about lyric similarity. We anticipate that our findings will enhance the development of similarity-based lyric recommendation systems by offering pseudo-labels for neural network development and introducing objective evaluation metrics.