 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Singing Voice Conversion Challenge 2025: From Singer Identity Conversion To Singing Style Conversion
Sep 19, 2025We present the findings of the latest iteration of the Singing Voice Conversion Challenge, a scientific event aiming to compare and understand different voice conversion systems in a controlled environment. Compared to previous iterations which solely focused on converting the singer identity, this year we also focused on converting the singing style of the singer. To create a controlled environment and thorough evaluations, we developed a new challenge database, introduced two tasks, open-sourced baselines, and conducted large-scale crowd-sourced listening tests and objective evaluations. The challenge was ran for two months and in total we evaluated 26 different systems. The results of the large-scale crowd-sourced listening test showed that top systems had comparable singer identity scores to ground truth samples. However, modeling the singing style and consequently achieving high naturalness still remains a challenge in this task, primarily due to the difficulty in modeling dynamic information in breathy, glissando, and vibrato singing styles.
Serenade: A Singing Style Conversion Framework Based On Audio Infilling
Mar 16, 2025We propose Serenade, a novel framework for the singing style conversion (SSC) task. Although singer identity conversion has made great strides in the previous years, converting the singing style of a singer has been an unexplored research area. We find three main challenges in SSC: modeling the target style, disentangling source style, and retaining the source melody. To model the target singing style, we use an audio infilling task by predicting a masked segment of the target mel-spectrogram with a flow-matching model using the complement of the masked target mel-spectrogram along with disentangled acoustic features. On the other hand, to disentangle the source singing style, we use a cyclic training approach, where we use synthetic converted samples as source inputs and reconstruct the original source mel-spectrogram as a target. Finally, to retain the source melody better, we investigate a post-processing module using a source-filter-based vocoder and resynthesize the converted waveforms using the original F0 patterns. Our results showed that the Serenade framework can handle generalized SSC tasks with the best overall similarity score, especially in modeling breathy and mixed singing styles. Moreover, although resynthesizing with the original F0 patterns alleviated out-of-tune singing and improved naturalness, we found a slight tradeoff in similarity due to not changing the F0 patterns into the target style.
A Preliminary Investigation on Flexible Singing Voice Synthesis Through Decomposed Framework with Inferrable Features
Jul 12, 2024We investigate the feasibility of a singing voice synthesis (SVS) system by using a decomposed framework to improve flexibility in generating singing voices. Due to data-driven approaches, SVS performs a music score-to-waveform mapping; however, the direct mapping limits control, such as being able to only synthesize in the language or the singers present in the labeled singing datasets. As collecting large singing datasets labeled with music scores is an expensive task, we investigate an alternative approach by decomposing the SVS system and inferring different singing voice features. We decompose the SVS system into three-stage modules of linguistic, pitch contour, and synthesis, in which singing voice features such as linguistic content, F0, voiced/unvoiced, singer embeddings, and loudness are directly inferred from audio. Through this decomposed framework, we show that we can alleviate the labeled dataset requirements, adapt to different languages or singers, and inpaint the lyrical content of singing voices. Our investigations show that the framework has the potential to reach state-of-the-art in SVS, even though the model has additional functionality and improved flexibility. The comprehensive analysis of our investigated framework's current capabilities sheds light on the ways the research community can achieve a flexible and multifunctional SVS system.
Quantifying the effect of speech pathology on automatic and human speaker verification
Jun 10, 2024



This study investigates how surgical intervention for speech pathology (specifically, as a result of oral cancer surgery) impacts the performance of an automatic speaker verification (ASV) system. Using two recently collected Dutch datasets with parallel pre and post-surgery audio from the same speaker, NKI-OC-VC and SPOKE, we assess the extent to which speech pathology influences ASV performance, and whether objective/subjective measures of speech severity are correlated with the performance. Finally, we carry out a perceptual study to compare judgements of ASV and human listeners. Our findings reveal that pathological speech negatively affects ASV performance, and the severity of the speech is negatively correlated with the performance. There is a moderate agreement in perceptual and objective scores of speaker similarity and severity, however, we could not clearly establish in the perceptual study, whether the same phenomenon also exists in human perception.
A Comparative Study of Voice Conversion Models with Large-Scale Speech and Singing Data: The T13 Systems for the Singing Voice Conversion Challenge 2023
Oct 08, 2023

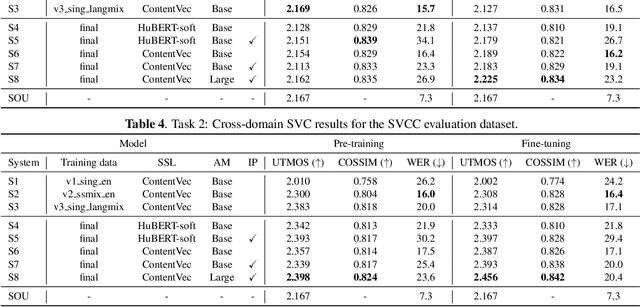
This paper presents our systems (denoted as T13) for the singing voice conversion challenge (SVCC) 2023. For both in-domain and cross-domain English singing voice conversion (SVC) tasks (Task 1 and Task 2), we adopt a recognition-synthesis approach with self-supervised learning-based representation. To achieve data-efficient SVC with a limited amount of target singer/speaker's data (150 to 160 utterances for SVCC 2023), we first train a diffusion-based any-to-any voice conversion model using publicly available large-scale 750 hours of speech and singing data. Then, we finetune the model for each target singer/speaker of Task 1 and Task 2. Large-scale listening tests conducted by SVCC 2023 show that our T13 system achieves competitive naturalness and speaker similarity for the harder cross-domain SVC (Task 2), which implies the generalization ability of our proposed method. Our objective evaluation results show that using large datasets is particularly beneficial for cross-domain SVC.
Improving severity preservation of healthy-to-pathological voice conversion with global style tokens
Oct 04, 2023In healthy-to-pathological voice conversion (H2P-VC), healthy speech is converted into pathological while preserving the identity. The paper improves on previous two-stage approach to H2P-VC where (1) speech is created first with the appropriate severity, (2) then the speaker identity of the voice is converted while preserving the severity of the voice. Specifically, we propose improvements to (2) by using phonetic posteriorgrams (PPG) and global style tokens (GST). Furthermore, we present a new dataset that contains parallel recordings of pathological and healthy speakers with the same identity which allows more precise evaluation. Listening tests by expert listeners show that the framework preserves severity of the source sample, while modelling target speaker's voice. We also show that (a) pathology impacts x-vectors but not all speaker information is lost, (b) choosing source speakers based on severity labels alone is insufficient.
Electrolaryngeal Speech Intelligibility Enhancement Through Robust Linguistic Encoders
Sep 18, 2023



We propose a novel framework for electrolaryngeal speech intelligibility enhancement through the use of robust linguistic encoders. Pretraining and fine-tuning approaches have proven to work well in this task, but in most cases, various mismatches, such as the speech type mismatch (electrolaryngeal vs. typical) or a speaker mismatch between the datasets used in each stage, can deteriorate the conversion performance of this framework. To resolve this issue, we propose a linguistic encoder robust enough to project both EL and typical speech in the same latent space, while still being able to extract accurate linguistic information, creating a unified representation to reduce the speech type mismatch. Furthermore, we introduce HuBERT output features to the proposed framework for reducing the speaker mismatch, making it possible to effectively use a large-scale parallel dataset during pretraining. We show that compared to the conventional framework using mel-spectrogram input and output features, using the proposed framework enables the model to synthesize more intelligible and naturally sounding speech, as shown by a significant 16% improvement in character error rate and 0.83 improvement in naturalness score.
The Singing Voice Conversion Challenge 2023
Jul 06, 2023



We present the latest iteration of the voice conversion challenge (VCC) series, a bi-annual scientific event aiming to compare and understand different voice conversion (VC) systems based on a common dataset. This year we shifted our focus to singing voice conversion (SVC), thus named the challenge the Singing Voice Conversion Challenge (SVCC). A new database was constructed for two tasks, namely in-domain and cross-domain SVC. The challenge was run for two months, and in total we received 26 submissions, including 2 baselines. Through a large-scale crowd-sourced listening test, we observed that for both tasks, although human-level naturalness was achieved by the top system, no team was able to obtain a similarity score as high as the target speakers. Also, as expected, cross-domain SVC is harder than in-domain SVC, especially in the similarity aspect. We also investigated whether existing objective measurements were able to predict perceptual performance, and found that only few of them could reach a significant correlation.
An Analysis of Personalized Speech Recognition System Development for the Deaf and Hard-of-Hearing
Jun 24, 2023Deaf or hard-of-hearing (DHH) speakers typically have atypical speech caused by deafness. With the growing support of speech-based devices and software applications, more work needs to be done to make these devices inclusive to everyone. To do so, we analyze the use of openly-available automatic speech recognition (ASR) tools with a DHH Japanese speaker dataset. As these out-of-the-box ASR models typically do not perform well on DHH speech, we provide a thorough analysis of creating personalized ASR systems. We collected a large DHH speaker dataset of four speakers totaling around 28.05 hours and thoroughly analyzed the performance of different training frameworks by varying the training data sizes. Our findings show that 1000 utterances (or 1-2 hours) from a target speaker can already significantly improve the model performance with minimal amount of work needed, thus we recommend researchers to collect at least 1000 utterances to make an efficient personalized ASR system. In cases where 1000 utterances is difficult to collect, we also discover significant improvements in using previously proposed data augmentation techniques such as intermediate fine-tuning when only 200 utterances are available.
Intermediate Fine-Tuning Using Imperfect Synthetic Speech for Improving Electrolaryngeal Speech Recognition
Nov 02, 2022



Research on automatic speech recognition (ASR) systems for electrolaryngeal speakers has been relatively unexplored due to small datasets. When training data is lacking in ASR, a large-scale pretraining and fine tuning framework is often sufficient to achieve high recognition rates; however, in electrolaryngeal speech, the domain shift between the pretraining and fine-tuning data is too large to overcome, limiting the maximum improvement of recognition rates. To resolve this, we propose an intermediate fine-tuning step that uses imperfect synthetic speech to close the domain shift gap between the pretraining and target data. Despite the imperfect synthetic data, we show the effectiveness of this on electrolaryngeal speech datasets, with improvements of 6.1% over the baseline that did not use imperfect synthetic speech. Results show how the intermediate fine-tuning stage focuses on learning the high-level inherent features of the imperfect synthetic data rather than the low-level features such as intelligibility.