 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Emotion-discriminative Representations for Zero-Shot Cross-lingual Speech Emotion Recognition
Jun 04, 2026Zero-shot cross-lingual speech emotion recognition (SER) remains challenging due to distribution mismatches across languages and the lack of emotion annotations in target language. Under such conditions, models trained solely on source-language data frequently suffer from degraded generalization when evaluated on unseen target languages. To address this limitation, we propose an emotion-discriminative representation learning method that integrates supervised contrastive learning and speaker adversarial learning. The contrastive learning promotes cross-lingual emotion alignment, while speaker adversarial learning suppresses speaker-related cues to encourage speaker-invariant representations. Experimental results under a zero-shot cross-lingual SER setting demonstrate that the proposed method significantly improves SER performance over conventional training strategies.
Advancing Electrolaryngeal Speech Enhancement Through Speech-Text Representation Learning
Jun 01, 2026Objective: laryngectomees depend on an electromechanical device to generate electrolaryngeal (EL) speech. Compared with normal speech, EL speech suffers from severe distortion, limited phonetic variation, unnatural prosody, and temporal shifts, degrading naturalness and intelligibility. Although sequence-to-sequence (seq2seq) voice conversion (VC) based EL-speech-to-normal-speech conversion (EL2SP) is promising, substantial mismatches between EL and normal speech inevitably cause cumulative mapping errors that limit performance. To address this, we describe a novel representation learning framework integrating speech and text representations to improve mapping and reconstruction quality within a seq2seq VC model. Methods: our methodology comprises two main stages: 1) representation integration and learning, and 2) reconstruction training. A network capable of incorporating auxiliary text information is first constructed with pretrained modules to learn speech--text-based integrated representations. Then, an autoencoder-style reconstruction strategy finalizes EL2SP model to inherit these representations without increasing model complexity. We introduce three fusion strategies including middle-, input-, and hybrid-level fusion strategies that progressively enhance learning. Moreover, besides standard seq2seq VC objectives, an additional reconstruction loss on the integrated representation is introduced to refine representation transfer. Results: experiments under different EL2SP datasets consistently demonstrate that our methods, combined with data augmentations, outperform baselines relying solely on speech representations. Furthermore, progressive improvements with system design depth validate the effectiveness of our methods. Significance: the proposed methods provide an extensible and practical methodology for EL speech enhancement and assistive communication technologies.
* 15 pages, 7 figures. Accepted to IEEE TBME
Gaze into the Details: Locality-Sensitive Enhancement for OCTA Retinal Vessel Segmentation
May 20, 2026Existing deep learning frameworks for Optical Coherence Tomography Angiography (OCTA) vessel segmentation are largely derived from the U-Net architecture, which serves as the foundation for most current designs. However, most of these methods focus only on holistic representation, struggling to address the problem of low local contrast unique to OCTA, which leads to vessel discontinuities and loss of detail. To address these problems, we propose LSENet, which builds upon the U-Net architecture by introducing three core innovative modules: To address vessel discontinuities, we introduce the Patch Information Enhance module (PIE), which replaces standard skip connections to execute patch-wise attention. To mitigate detail loss, the Multiscale Feature Fusion module (MFF) is proposed to feed the PIE module rich, multi-scale information by extracting visually interpretable features from both the original input and preceding layers. Finally, the Connectivity Refinement Decoder (CRD) is designed to refine features from all levels and utilize a large kernel in the final convolutional layer to reduce fragmentation. Experiments on three public datasets (OCTA-500, ROSE-1, and ROSSA) demonstrate that our proposed LSENet achieves state-of-the-art performance while requiring fewer parameters.
Beyond Polarity: Multi-Dimensional LLM Sentiment Signals for WTI Crude Oil Futures Return Prediction
Mar 12, 2026Forecasting crude oil prices remains challenging because market-relevant information is embedded in large volumes of unstructured news and is not fully captured by traditional polarity-based sentiment measures. This paper examines whether multi-dimensional sentiment signals extracted by large language models improve the prediction of weekly WTI crude oil futures returns. Using energy-sector news articles from 2020 to 2025, we construct five sentiment dimensions covering relevance, polarity, intensity, uncertainty, and forwardness based on GPT-4o, Llama 3.2-3b, and two benchmark models, FinBERT and AlphaVantage. We aggregate article-level signals to the weekly level and evaluate their predictive performance in a classification framework. The best results are achieved by combining GPT-4o and FinBERT, suggesting that LLM-based and conventional financial sentiment models provide complementary predictive information. SHAP analysis further shows that intensity- and uncertainty-related features are among the most important predictors, indicating that the predictive value of news sentiment extends beyond simple polarity. Overall, the results suggest that multi-dimensional LLM-based sentiment measures can improve commodity return forecasting and support energy-market risk monitoring.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Two-stage Framework for Robust Speech Emotion Recognition Using Target Speaker Extraction in Human Speech Noise Conditions
Sep 29, 2024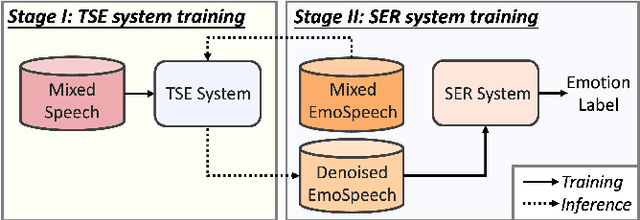
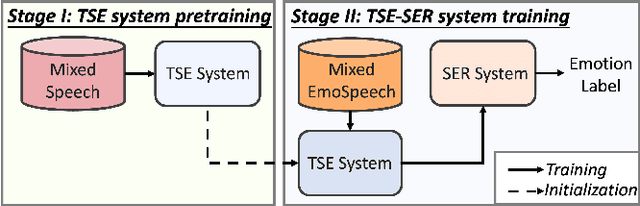
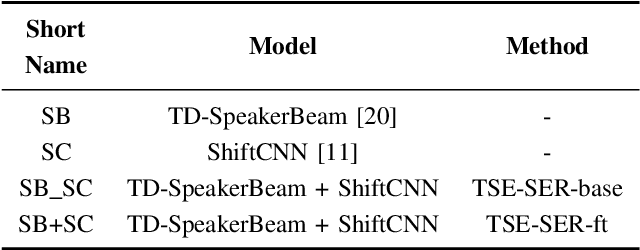
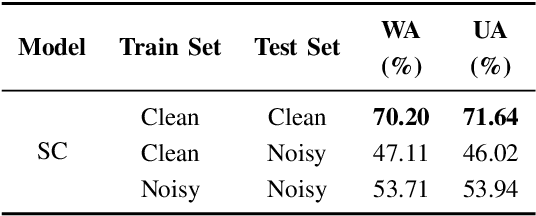
Developing a robust speech emotion recognition (SER) system in noisy conditions faces challenges posed by different noise properties. Most previous studies have not considered the impact of human speech noise, thus limiting the application scope of SER. In this paper, we propose a novel two-stage framework for the problem by cascading target speaker extraction (TSE) method and SER. We first train a TSE model to extract the speech of target speaker from a mixture. Then, in the second stage, we utilize the extracted speech for SER training. Additionally, we explore a joint training of TSE and SER models in the second stage. Our developed system achieves a 14.33% improvement in unweighted accuracy (UA) compared to a baseline without using TSE method, demonstrating the effectiveness of our framework in mitigating the impact of human speech noise. Moreover, we conduct experiments considering speaker gender, showing that our framework performs particularly well in different-gender mixture.
Electrolaryngeal Speech Intelligibility Enhancement Through Robust Linguistic Encoders
Sep 18, 2023



We propose a novel framework for electrolaryngeal speech intelligibility enhancement through the use of robust linguistic encoders. Pretraining and fine-tuning approaches have proven to work well in this task, but in most cases, various mismatches, such as the speech type mismatch (electrolaryngeal vs. typical) or a speaker mismatch between the datasets used in each stage, can deteriorate the conversion performance of this framework. To resolve this issue, we propose a linguistic encoder robust enough to project both EL and typical speech in the same latent space, while still being able to extract accurate linguistic information, creating a unified representation to reduce the speech type mismatch. Furthermore, we introduce HuBERT output features to the proposed framework for reducing the speaker mismatch, making it possible to effectively use a large-scale parallel dataset during pretraining. We show that compared to the conventional framework using mel-spectrogram input and output features, using the proposed framework enables the model to synthesize more intelligible and naturally sounding speech, as shown by a significant 16% improvement in character error rate and 0.83 improvement in naturalness score.
Intermediate Fine-Tuning Using Imperfect Synthetic Speech for Improving Electrolaryngeal Speech Recognition
Nov 02, 2022



Research on automatic speech recognition (ASR) systems for electrolaryngeal speakers has been relatively unexplored due to small datasets. When training data is lacking in ASR, a large-scale pretraining and fine tuning framework is often sufficient to achieve high recognition rates; however, in electrolaryngeal speech, the domain shift between the pretraining and fine-tuning data is too large to overcome, limiting the maximum improvement of recognition rates. To resolve this, we propose an intermediate fine-tuning step that uses imperfect synthetic speech to close the domain shift gap between the pretraining and target data. Despite the imperfect synthetic data, we show the effectiveness of this on electrolaryngeal speech datasets, with improvements of 6.1% over the baseline that did not use imperfect synthetic speech. Results show how the intermediate fine-tuning stage focuses on learning the high-level inherent features of the imperfect synthetic data rather than the low-level features such as intelligibility.
Two-stage training method for Japanese electrolaryngeal speech enhancement based on sequence-to-sequence voice conversion
Oct 19, 2022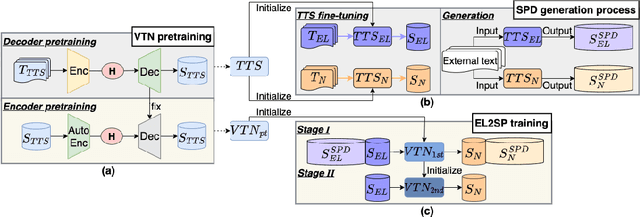
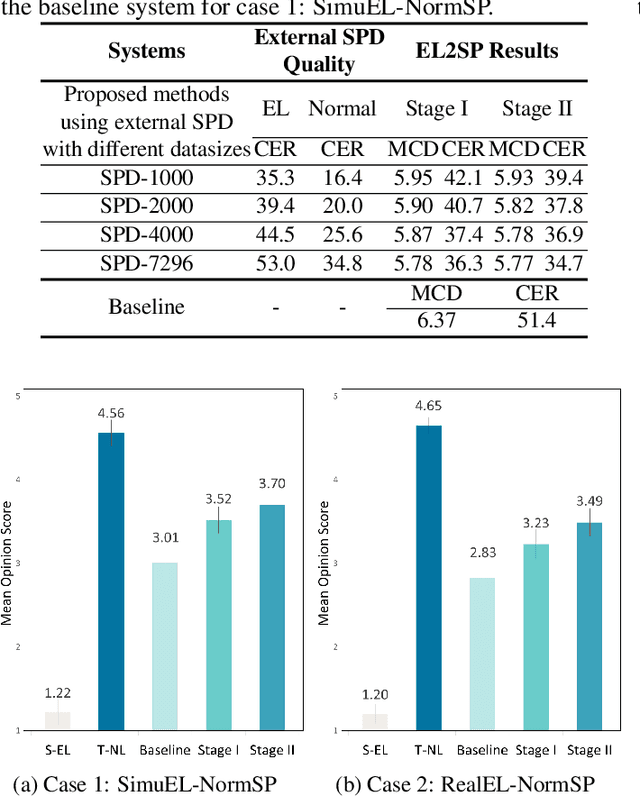

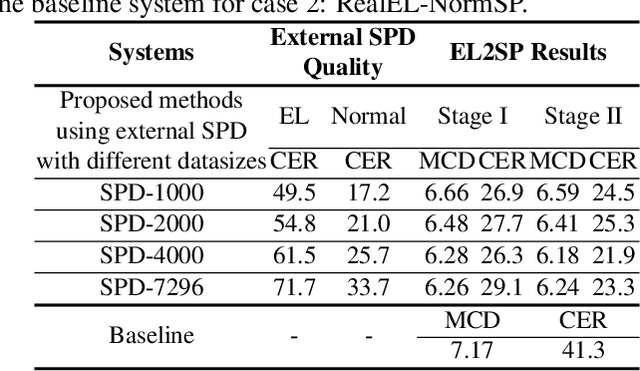
Sequence-to-sequence (seq2seq) voice conversion (VC) models have greater potential in converting electrolaryngeal (EL) speech to normal speech (EL2SP) compared to conventional VC models. However, EL2SP based on seq2seq VC requires a sufficiently large amount of parallel data for the model training and it suffers from significant performance degradation when the amount of training data is insufficient. To address this issue, we suggest a novel, two-stage strategy to optimize the performance on EL2SP based on seq2seq VC when a small amount of the parallel dataset is available. In contrast to utilizing high-quality data augmentations in previous studies, we first combine a large amount of imperfect synthetic parallel data of EL and normal speech, with the original dataset into VC training. Then, a second stage training is conducted with the original parallel dataset only. The results show that the proposed method progressively improves the performance of EL2SP based on seq2seq VC.
TCDCaps: Visual Tracking via Cascaded Dense Capsules
Feb 26, 2019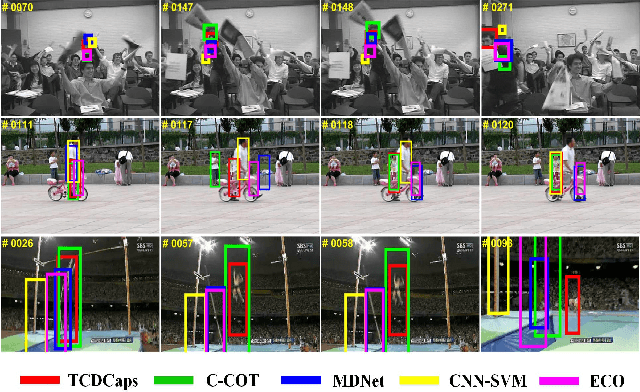
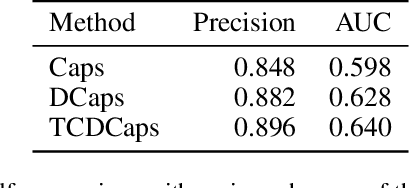
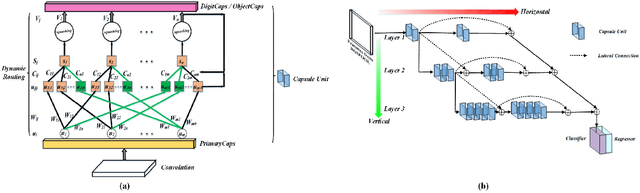

The critical challenge in tracking-by-detection framework is how to avoid drift problem during online learning, where the robust features for a variety of appearance changes are difficult to be learned and a reasonable intersection over union (IoU) threshold that defines the true/false positives is hard to set. This paper presents the TCDCaps method to address the problems above via a cascaded dense capsule architecture. To get robust features, we extend original capsules with dense-connected routing, which are referred as DCaps. Depending on the preservation of part-whole relationships in the Capsule Networks, our dense-connected capsules can capture a variety of appearance variations. In addition, to handle the issue of IoU threshold, a cascaded DCaps model (CDCaps) is proposed to improve the quality of candidates, it consists of sequential DCaps trained with increasing IoU thresholds so as to sequentially improve the quality of candidates. Extensive experiments on 3 popular benchmarks demonstrate the robustness of the proposed TCDCaps.