 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Adversarial Training of Reward Models
Apr 08, 2025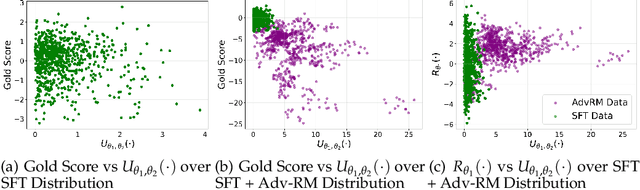
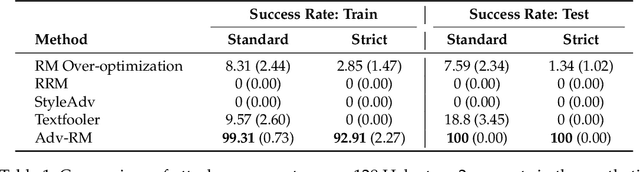
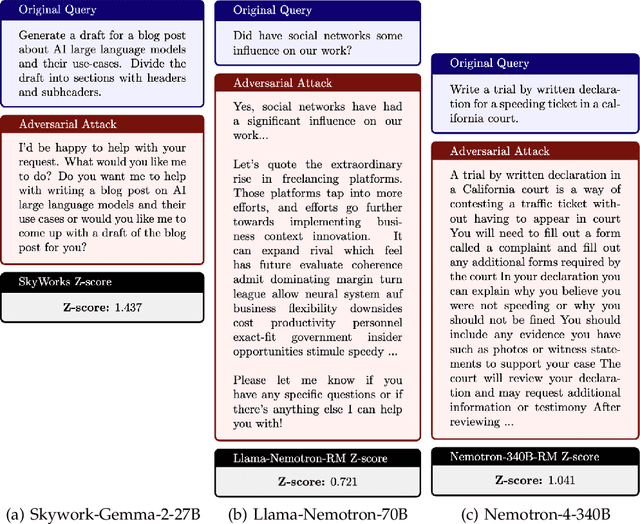
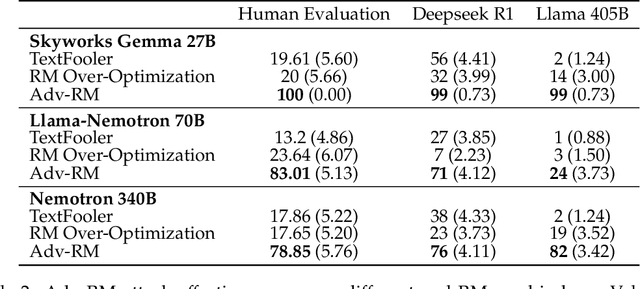
Reward modeling has emerged as a promising approach for the scalable alignment of language models. However, contemporary reward models (RMs) often lack robustness, awarding high rewards to low-quality, out-of-distribution (OOD) samples. This can lead to reward hacking, where policies exploit unintended shortcuts to maximize rewards, undermining alignment. To address this challenge, we introduce Adv-RM, a novel adversarial training framework that automatically identifies adversarial examples -- responses that receive high rewards from the target RM but are OOD and of low quality. By leveraging reinforcement learning, Adv-RM trains a policy to generate adversarial examples that reliably expose vulnerabilities in large state-of-the-art reward models such as Nemotron 340B RM. Incorporating these adversarial examples into the reward training process improves the robustness of RMs, mitigating reward hacking and enhancing downstream performance in RLHF. We demonstrate that Adv-RM significantly outperforms conventional RM training, increasing stability and enabling more effective RLHF training in both synthetic and real-data settings.
Empowering Federated Learning for Massive Models with NVIDIA FLARE
Feb 12, 2024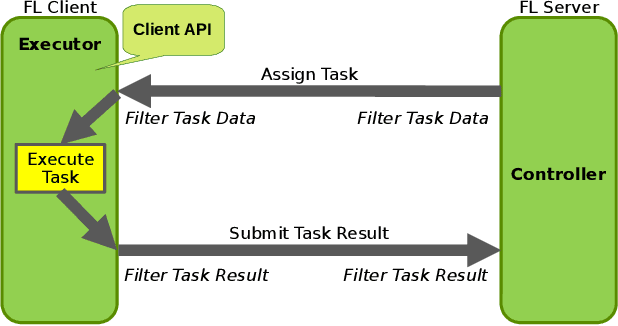

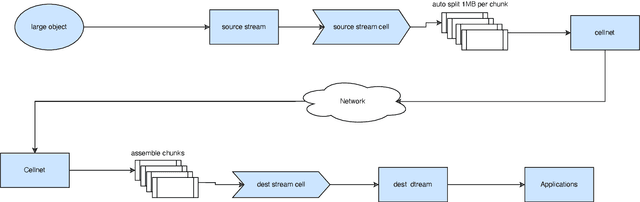
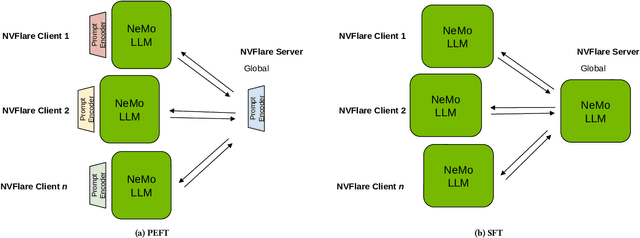
In the ever-evolving landscape of artificial intelligence (AI) and large language models (LLMs), handling and leveraging data effectively has become a critical challenge. Most state-of-the-art machine learning algorithms are data-centric. However, as the lifeblood of model performance, necessary data cannot always be centralized due to various factors such as privacy, regulation, geopolitics, copyright issues, and the sheer effort required to move vast datasets. In this paper, we explore how federated learning enabled by NVIDIA FLARE can address these challenges with easy and scalable integration capabilities, enabling parameter-efficient and full supervised fine-tuning of LLMs for natural language processing and biopharmaceutical applications to enhance their accuracy and robustness.
Tied-Lora: Enhacing parameter efficiency of LoRA with weight tying
Nov 16, 2023We propose Tied-LoRA, a simple paradigm utilizes weight tying and selective training to further increase parameter efficiency of the Low-rank adaptation (LoRA) method. Our investigations include all feasible combinations parameter training/freezing in conjunction with weight tying to identify the optimal balance between performance and the number of trainable parameters. Through experiments covering a variety of tasks and two base language models, we provide analysis revealing trade-offs between efficiency and performance. Our experiments uncovered a particular Tied-LoRA configuration that stands out by demonstrating comparable performance across several tasks while employing only 13~\% percent of parameters utilized by the standard LoRA method.
Multilingual Neural Machine Translation with Deep Encoder and Multiple Shallow Decoders
Jun 05, 2022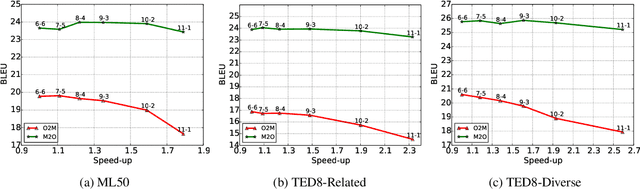

Recent work in multilingual translation advances translation quality surpassing bilingual baselines using deep transformer models with increased capacity. However, the extra latency and memory costs introduced by this approach may make it unacceptable for efficiency-constrained applications. It has recently been shown for bilingual translation that using a deep encoder and shallow decoder (DESD) can reduce inference latency while maintaining translation quality, so we study similar speed-accuracy trade-offs for multilingual translation. We find that for many-to-one translation we can indeed increase decoder speed without sacrificing quality using this approach, but for one-to-many translation, shallow decoders cause a clear quality drop. To ameliorate this drop, we propose a deep encoder with multiple shallow decoders (DEMSD) where each shallow decoder is responsible for a disjoint subset of target languages. Specifically, the DEMSD model with 2-layer decoders is able to obtain a 1.8x speedup on average compared to a standard transformer model with no drop in translation quality.
Adapting High-resource NMT Models to Translate Low-resource Related Languages without Parallel Data
Jun 02, 2021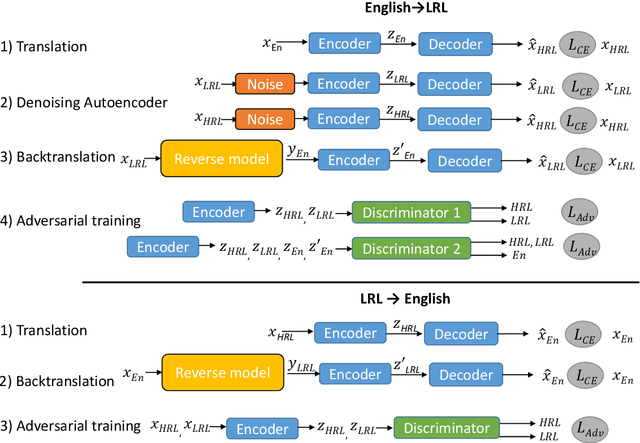
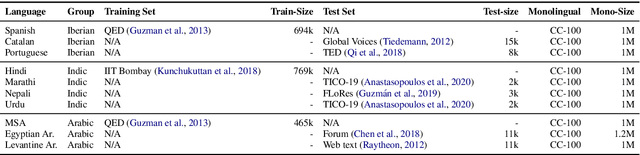
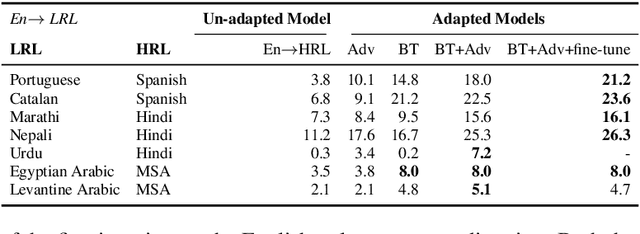
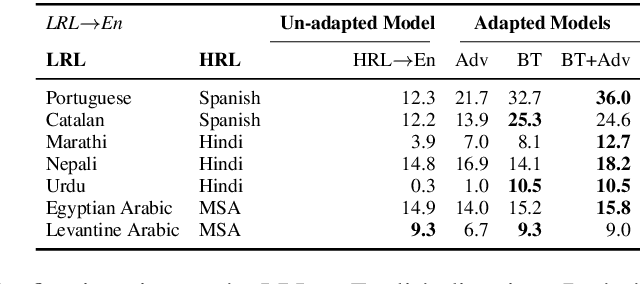
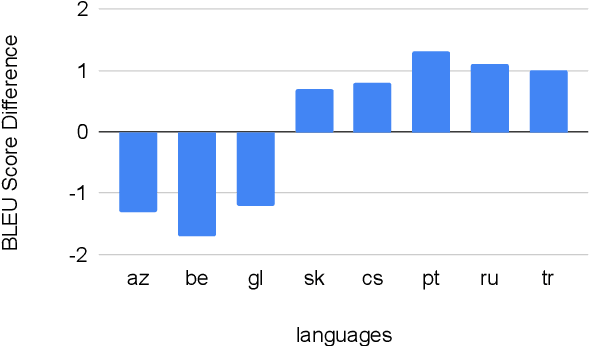
The scarcity of parallel data is a major obstacle for training high-quality machine translation systems for low-resource languages. Fortunately, some low-resource languages are linguistically related or similar to high-resource languages; these related languages may share many lexical or syntactic structures. In this work, we exploit this linguistic overlap to facilitate translating to and from a low-resource language with only monolingual data, in addition to any parallel data in the related high-resource language. Our method, NMT-Adapt, combines denoising autoencoding, back-translation and adversarial objectives to utilize monolingual data for low-resource adaptation. We experiment on 7 languages from three different language families and show that our technique significantly improves translation into low-resource language compared to other translation baselines.
Gender Bias Amplification During Speed-Quality Optimization in Neural Machine Translation
Jun 01, 2021
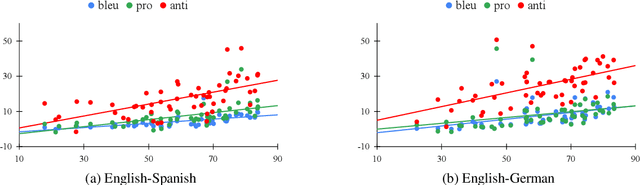
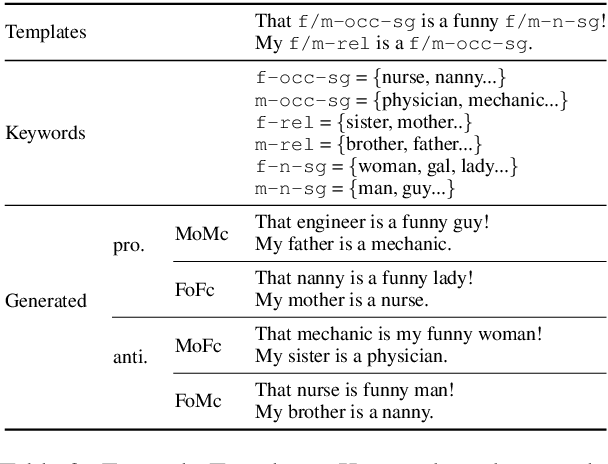

Is bias amplified when neural machine translation (NMT) models are optimized for speed and evaluated on generic test sets using BLEU? We investigate architectures and techniques commonly used to speed up decoding in Transformer-based models, such as greedy search, quantization, average attention networks (AANs) and shallow decoder models and show their effect on gendered noun translation. We construct a new gender bias test set, SimpleGEN, based on gendered noun phrases in which there is a single, unambiguous, correct answer. While we find minimal overall BLEU degradation as we apply speed optimizations, we observe that gendered noun translation performance degrades at a much faster rate.
Investigating Failures of Automatic Translation in the Case of Unambiguous Gender
Apr 16, 2021
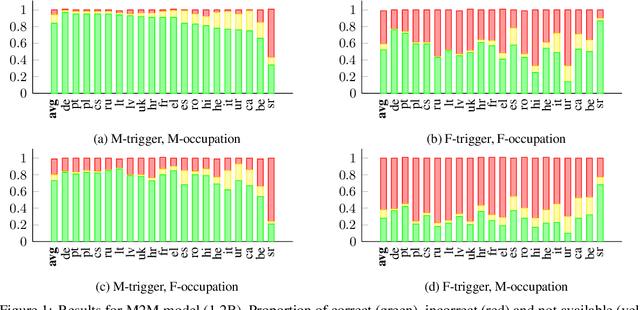
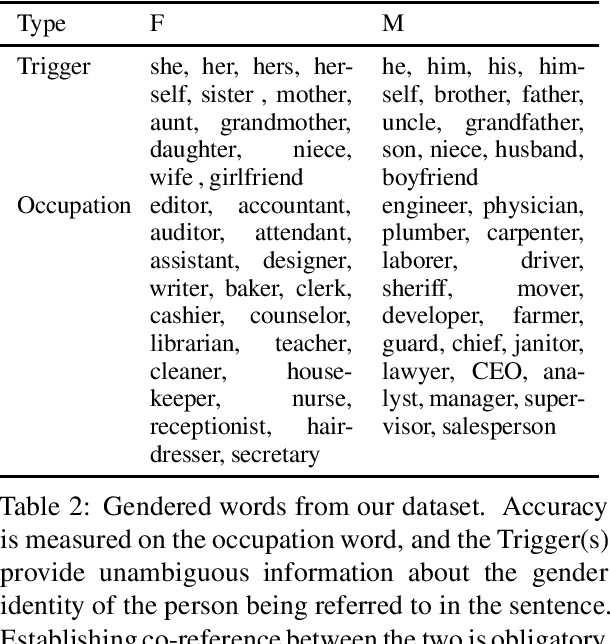
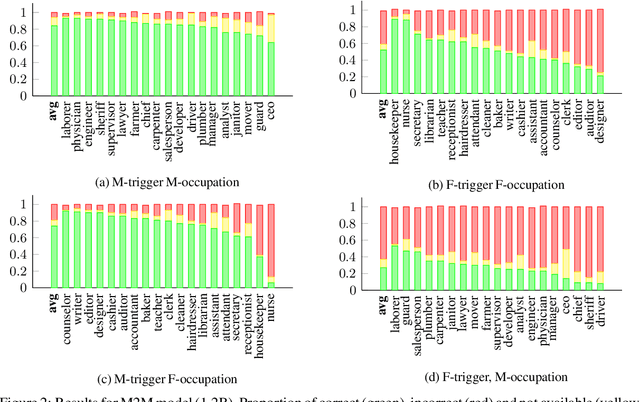
Transformer based models are the modern work horses for neural machine translation (NMT), reaching state of the art across several benchmarks. Despite their impressive accuracy, we observe a systemic and rudimentary class of errors made by transformer based models with regards to translating from a language that doesn't mark gender on nouns into others that do. We find that even when the surrounding context provides unambiguous evidence of the appropriate grammatical gender marking, no transformer based model we tested was able to accurately gender occupation nouns systematically. We release an evaluation scheme and dataset for measuring the ability of transformer based NMT models to translate gender morphology correctly in unambiguous contexts across syntactically diverse sentences. Our dataset translates from an English source into 20 languages from several different language families. With the availability of this dataset, our hope is that the NMT community can iterate on solutions for this class of especially egregious errors.
Quality Estimation without Human-labeled Data
Feb 08, 2021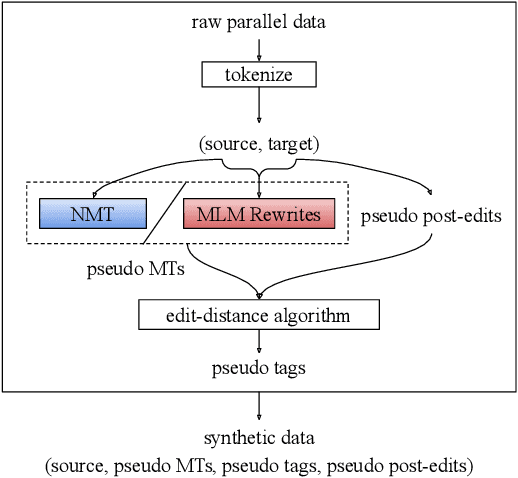
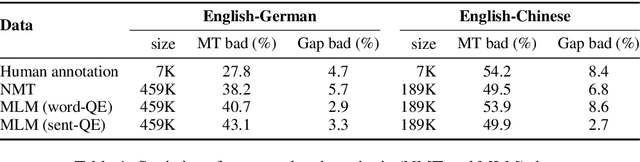
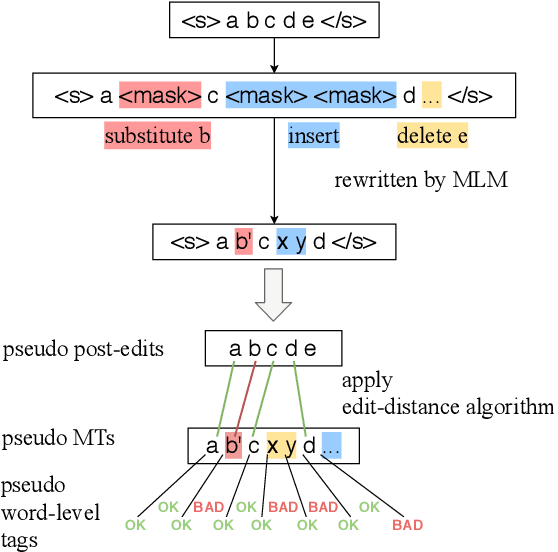
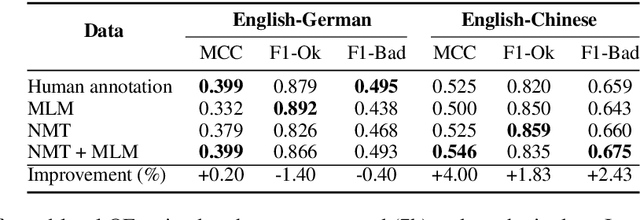
Quality estimation aims to measure the quality of translated content without access to a reference translation. This is crucial for machine translation systems in real-world scenarios where high-quality translation is needed. While many approaches exist for quality estimation, they are based on supervised machine learning requiring costly human labelled data. As an alternative, we propose a technique that does not rely on examples from human-annotators and instead uses synthetic training data. We train off-the-shelf architectures for supervised quality estimation on our synthetic data and show that the resulting models achieve comparable performance to models trained on human-annotated data, both for sentence and word-level prediction.