 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Federated Learning for Massive Models with NVIDIA FLARE
Paper and Code
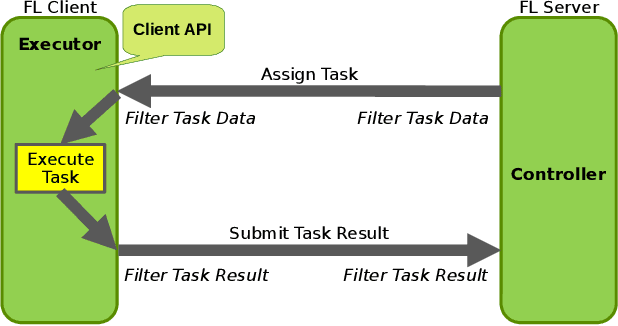

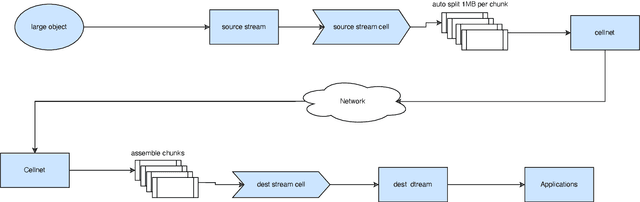
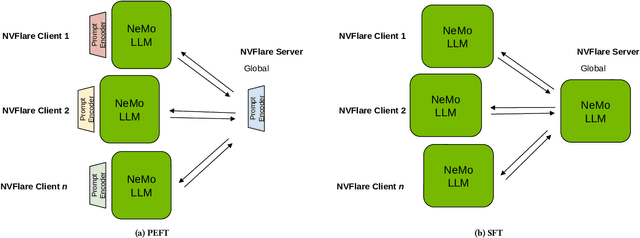
In the ever-evolving landscape of artificial intelligence (AI) and large language models (LLMs), handling and leveraging data effectively has become a critical challenge. Most state-of-the-art machine learning algorithms are data-centric. However, as the lifeblood of model performance, necessary data cannot always be centralized due to various factors such as privacy, regulation, geopolitics, copyright issues, and the sheer effort required to move vast datasets. In this paper, we explore how federated learning enabled by NVIDIA FLARE can address these challenges with easy and scalable integration capabilities, enabling parameter-efficient and full supervised fine-tuning of LLMs for natural language processing and biopharmaceutical applications to enhance their accuracy and robustness.