 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Complementary Agents for Robust LLM Ensemble
May 21, 2026Multi-AI collaboration, such as ensembling or debating large language models (LLMs), is a promising paradigm for aggregating information and boosting performance. A foundational step in these pipelines is to feed the responses of several proposer LLMs into a summarizer LLM, which synthesizes a better answer. However, choosing which proposers to include is non-trivial. Existing approaches primarily focus either on accuracy (picking the strongest models) or diversity (ensuring variety), and often overlook the interactions among proposers and with the summarizer. We reframe proposer selection as a combinatorial selection problem akin to feature selection, where the value of an LLM lies in its complementarity with others. However, directly applying standard feature-selection algorithms is impractical in the LLM setting due to prohibitive time complexity. Motivated by this limitation, we explore an extensive range of computationally feasible, greedy-style selection algorithms that assess complementarity using a small labeled set. Our experiments validate complementarity as a guiding principle for proposer selection and identify methods that achieve the best performance-cost trade-offs in practice.
Mechanisms of AI Protein Folding in ESMFold
Feb 05, 2026How do protein structure prediction models fold proteins? We investigate this question by tracing how ESMFold folds a beta hairpin, a prevalent structural motif. Through counterfactual interventions on model latents, we identify two computational stages in the folding trunk. In the first stage, early blocks initialize pairwise biochemical signals: residue identities and associated biochemical features such as charge flow from sequence representations into pairwise representations. In the second stage, late blocks develop pairwise spatial features: distance and contact information accumulate in the pairwise representation. We demonstrate that the mechanisms underlying structural decisions of ESMFold can be localized, traced through interpretable representations, and manipulated with strong causal effects.
When Are Concepts Erased From Diffusion Models?
May 22, 2025Concept erasure, the ability to selectively prevent a model from generating specific concepts, has attracted growing interest, with various approaches emerging to address the challenge. However, it remains unclear how thoroughly these methods erase the target concept. We begin by proposing two conceptual models for the erasure mechanism in diffusion models: (i) reducing the likelihood of generating the target concept, and (ii) interfering with the model's internal guidance mechanisms. To thoroughly assess whether a concept has been truly erased from the model, we introduce a suite of independent evaluations. Our evaluation framework includes adversarial attacks, novel probing techniques, and analysis of the model's alternative generations in place of the erased concept. Our results shed light on the tension between minimizing side effects and maintaining robustness to adversarial prompts. Broadly, our work underlines the importance of comprehensive evaluation for erasure in diffusion models.
LAG-MMLU: Benchmarking Frontier LLM Understanding in Latvian and Giriama
Mar 14, 2025



As large language models (LLMs) rapidly advance, evaluating their performance is critical. LLMs are trained on multilingual data, but their reasoning abilities are mainly evaluated using English datasets. Hence, robust evaluation frameworks are needed using high-quality non-English datasets, especially low-resource languages (LRLs). This study evaluates eight state-of-the-art (SOTA) LLMs on Latvian and Giriama using a Massive Multitask Language Understanding (MMLU) subset curated with native speakers for linguistic and cultural relevance. Giriama is benchmarked for the first time. Our evaluation shows that OpenAI's o1 model outperforms others across all languages, scoring 92.8\% in English, 88.8\% in Latvian, and 70.8\% in Giriama on 0-shot tasks. Mistral-large (35.6\%) and Llama-70B IT (41\%) have weak performance, on both Latvian and Giriama. Our results underscore the need for localized benchmarks and human evaluations in advancing cultural AI contextualization.
* Accepted in NoDaLiDa/Baltic-HLT 2025
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Neuc-MDS: Non-Euclidean Multidimensional Scaling Through Bilinear Forms
Nov 16, 2024We introduce Non-Euclidean-MDS (Neuc-MDS), an extension of classical Multidimensional Scaling (MDS) that accommodates non-Euclidean and non-metric inputs. The main idea is to generalize the standard inner product to symmetric bilinear forms to utilize the negative eigenvalues of dissimilarity Gram matrices. Neuc-MDS efficiently optimizes the choice of (both positive and negative) eigenvalues of the dissimilarity Gram matrix to reduce STRESS, the sum of squared pairwise error. We provide an in-depth error analysis and proofs of the optimality in minimizing lower bounds of STRESS. We demonstrate Neuc-MDS's ability to address limitations of classical MDS raised by prior research, and test it on various synthetic and real-world datasets in comparison with both linear and non-linear dimension reduction methods.
Empowering Federated Learning for Massive Models with NVIDIA FLARE
Feb 12, 2024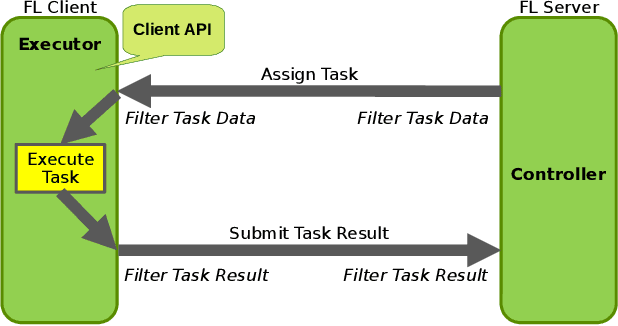

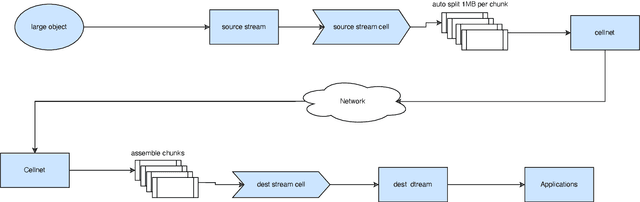
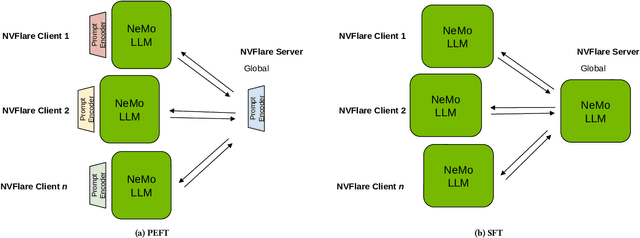
In the ever-evolving landscape of artificial intelligence (AI) and large language models (LLMs), handling and leveraging data effectively has become a critical challenge. Most state-of-the-art machine learning algorithms are data-centric. However, as the lifeblood of model performance, necessary data cannot always be centralized due to various factors such as privacy, regulation, geopolitics, copyright issues, and the sheer effort required to move vast datasets. In this paper, we explore how federated learning enabled by NVIDIA FLARE can address these challenges with easy and scalable integration capabilities, enabling parameter-efficient and full supervised fine-tuning of LLMs for natural language processing and biopharmaceutical applications to enhance their accuracy and robustness.
NVIDIA FLARE: Federated Learning from Simulation to Real-World
Oct 24, 2022



Federated learning (FL) enables building robust and generalizable AI models by leveraging diverse datasets from multiple collaborators without centralizing the data. We created NVIDIA FLARE as an open-source software development kit (SDK) to make it easier for data scientists to use FL in their research and real-world applications. The SDK includes solutions for state-of-the-art FL algorithms and federated machine learning approaches, which facilitate building workflows for distributed learning across enterprises and enable platform developers to create a secure, privacy-preserving offering for multiparty collaboration utilizing homomorphic encryption or differential privacy. The SDK is a lightweight, flexible, and scalable Python package, and allows researchers to bring their data science workflows implemented in any training libraries (PyTorch, TensorFlow, XGBoost, or even NumPy) and apply them in real-world FL settings. This paper introduces the key design principles of FLARE and illustrates some use cases (e.g., COVID analysis) with customizable FL workflows that implement different privacy-preserving algorithms. Code is available at https://github.com/NVIDIA/NVFlare.
PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation
Sep 16, 2022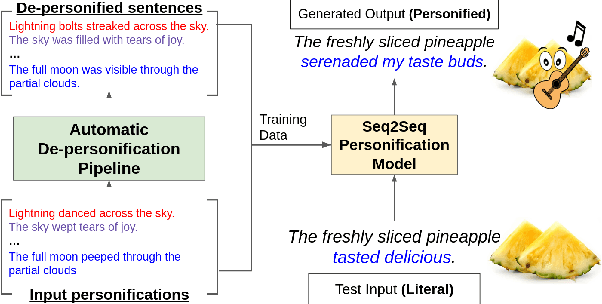
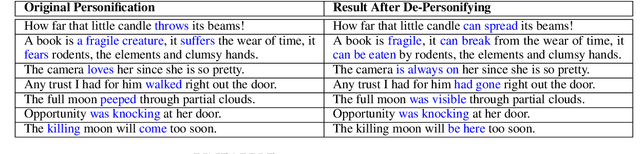
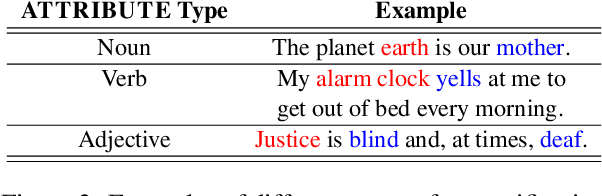
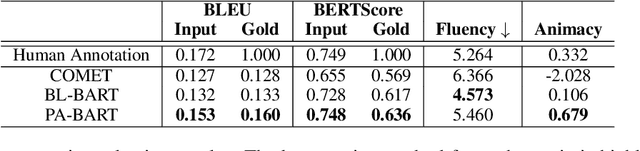
A personification is a figure of speech that endows inanimate entities with properties and actions typically seen as requiring animacy. In this paper, we explore the task of personification generation. To this end, we propose PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation. We curate a corpus of personifications called PersonifCorp, together with automatically generated de-personified literalizations of these personifications. We demonstrate the usefulness of this parallel corpus by training a seq2seq model to personify a given literal input. Both automatic and human evaluations show that fine-tuning with PersonifCorp leads to significant gains in personification-related qualities such as animacy and interestingness. A detailed qualitative analysis also highlights key strengths and imperfections of PINEAPPLE over baselines, demonstrating a strong ability to generate diverse and creative personifications that enhance the overall appeal of a sentence.
URLB: Unsupervised Reinforcement Learning Benchmark
Oct 28, 2021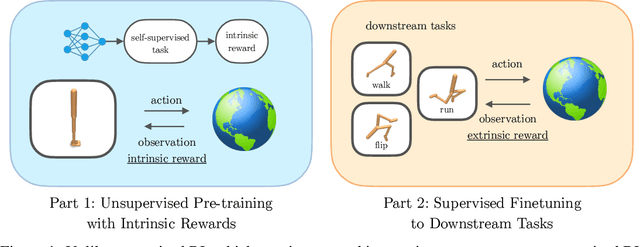
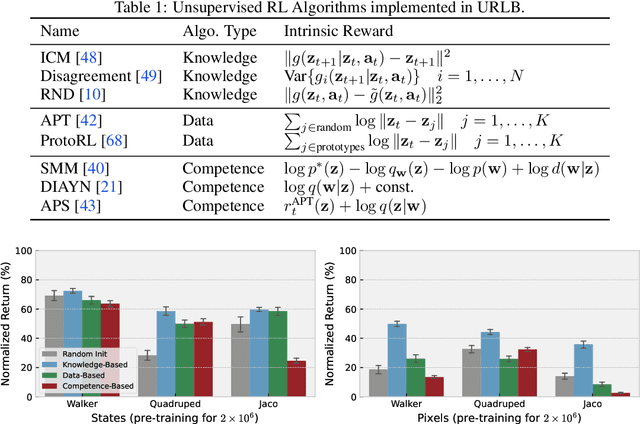

Deep Reinforcement Learning (RL) has emerged as a powerful paradigm to solve a range of complex yet specific control tasks. Yet training generalist agents that can quickly adapt to new tasks remains an outstanding challenge. Recent advances in unsupervised RL have shown that pre-training RL agents with self-supervised intrinsic rewards can result in efficient adaptation. However, these algorithms have been hard to compare and develop due to the lack of a unified benchmark. To this end, we introduce the Unsupervised Reinforcement Learning Benchmark (URLB). URLB consists of two phases: reward-free pre-training and downstream task adaptation with extrinsic rewards. Building on the DeepMind Control Suite, we provide twelve continuous control tasks from three domains for evaluation and open-source code for eight leading unsupervised RL methods. We find that the implemented baselines make progress but are not able to solve URLB and propose directions for future research.