 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLM Agents for Coordinating Multi-User Information Gathering
Feb 17, 2025This paper introduces PeopleJoin, a benchmark for evaluating LM-mediated collaborative problem solving. Given a user request, PeopleJoin agents must identify teammates who might be able to assist, converse with these teammates to gather information, and finally compile a useful answer or summary for the original user. PeopleJoin comprises two evaluation domains: PeopleJoin-QA, focused on questions about tabular data, and PeopleJoin-DocCreation, focused on document creation tasks. The two domains are adapted from existing NLP benchmarks for database question answering and multi-document summarization; here, however, the information needed to complete these tasks is distributed across synthetic ``organizations'' of 2--20 users, simulating natural multi-user collaboration scenarios. We implemented several popular LM agent architectures, evaluating their accuracy and efficiency at completing tasks, and highlight new research questions that can be studied using PeopleJoin.
Towards Robust Evaluation of Unlearning in LLMs via Data Transformations
Nov 23, 2024
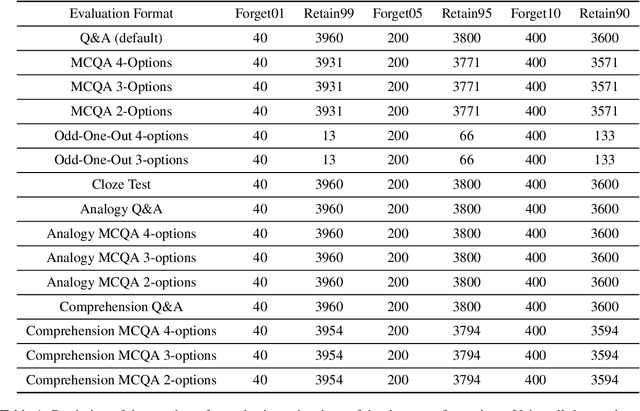


Large Language Models (LLMs) have shown to be a great success in a wide range of applications ranging from regular NLP-based use cases to AI agents. LLMs have been trained on a vast corpus of texts from various sources; despite the best efforts during the data pre-processing stage while training the LLMs, they may pick some undesirable information such as personally identifiable information (PII). Consequently, in recent times research in the area of Machine Unlearning (MUL) has become active, the main idea is to force LLMs to forget (unlearn) certain information (e.g., PII) without suffering from performance loss on regular tasks. In this work, we examine the robustness of the existing MUL techniques for their ability to enable leakage-proof forgetting in LLMs. In particular, we examine the effect of data transformation on forgetting, i.e., is an unlearned LLM able to recall forgotten information if there is a change in the format of the input? Our findings on the TOFU dataset highlight the necessity of using diverse data formats to quantify unlearning in LLMs more reliably.
Steering Large Language Models between Code Execution and Textual Reasoning
Oct 04, 2024



While a lot of recent research focuses on enhancing the textual reasoning capabilities of Large Language Models (LLMs) by optimizing the multi-agent framework or reasoning chains, several benchmark tasks can be solved with 100% success through direct coding, which is more scalable and avoids the computational overhead associated with textual iterating and searching. Textual reasoning has inherent limitations in solving tasks with challenges in math, logics, optimization, and searching, which is unlikely to be solved by simply scaling up the model and data size. The recently released OpenAI GPT Code Interpreter and multi-agent frameworks such as AutoGen have demonstrated remarkable proficiency of integrating code generation and execution to solve complex tasks using LLMs. However, based on our experiments on 7 existing popular methods for steering code/text generation in both single- and multi-turn settings with 14 tasks and 6 types of LLMs (including the new O1-preview), currently there is no optimal method to correctly steer LLMs to write code when needed. We discover some interesting patterns on when models use code vs. textual reasoning with the evolution to task complexity and model sizes, which even result in an astonishingly inverse scaling law. We also discover that results from LLM written code are not always better than using textual reasoning, even if the task could be solved through code. To mitigate the above issues, we propose three methods to better steer LLM code/text generation and achieve a notable improvement. The costs of token lengths and runtime are thoroughly discussed for all the methods. We believe the problem of steering LLM code/text generation is critical for future research and has much space for further improvement. Project Page, Datasets, and Codes are available at https://yongchao98.github.io/CodeSteer/.
Learning to Retrieve Iteratively for In-Context Learning
Jun 20, 2024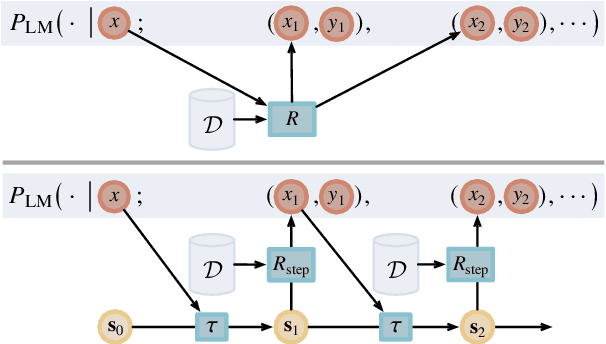
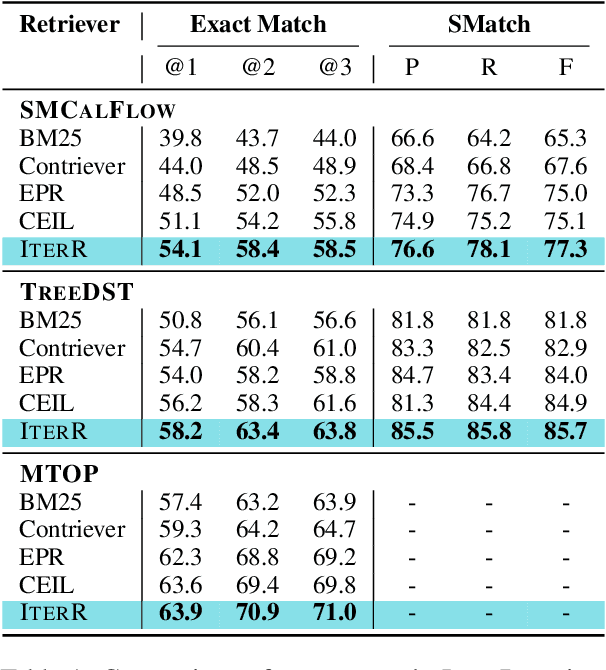
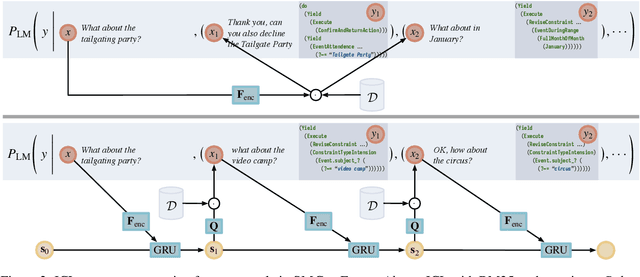
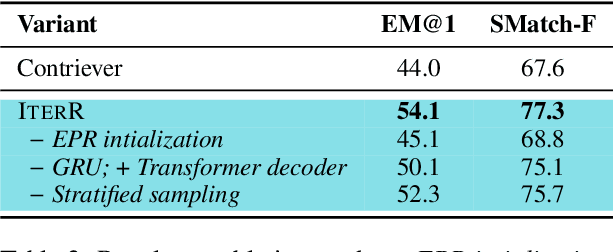
We introduce iterative retrieval, a novel framework that empowers retrievers to make iterative decisions through policy optimization. Finding an optimal portfolio of retrieved items is a combinatorial optimization problem, generally considered NP-hard. This approach provides a learned approximation to such a solution, meeting specific task requirements under a given family of large language models (LLMs). We propose a training procedure based on reinforcement learning, incorporating feedback from LLMs. We instantiate an iterative retriever for composing in-context learning (ICL) exemplars and apply it to various semantic parsing tasks that demand synthesized programs as outputs. By adding only 4M additional parameters for state encoding, we convert an off-the-shelf dense retriever into a stateful iterative retriever, outperforming previous methods in selecting ICL exemplars on semantic parsing datasets such as CalFlow, TreeDST, and MTOP. Additionally, the trained iterative retriever generalizes across different inference LLMs beyond the one used during training.
Interpreting User Requests in the Context of Natural Language Standing Instructions
Nov 16, 2023Users of natural language interfaces, generally powered by Large Language Models (LLMs),often must repeat their preferences each time they make a similar request. To alleviate this, we propose including some of a user's preferences and instructions in natural language -- collectively termed standing instructions -- as additional context for such interfaces. For example, when a user states I'm hungry, their previously expressed preference for Persian food will be automatically added to the LLM prompt, so as to influence the search for relevant restaurants. We develop NLSI, a language-to-program dataset consisting of over 2.4K dialogues spanning 17 domains, where each dialogue is paired with a user profile (a set of users specific standing instructions) and corresponding structured representations (API calls). A key challenge in NLSI is to identify which subset of the standing instructions is applicable to a given dialogue. NLSI contains diverse phenomena, from simple preferences to interdependent instructions such as triggering a hotel search whenever the user is booking tickets to an event. We conduct experiments on NLSI using prompting with large language models and various retrieval approaches, achieving a maximum of 44.7% exact match on API prediction. Our results demonstrate the challenges in identifying the relevant standing instructions and their interpretation into API calls.
SCREWS: A Modular Framework for Reasoning with Revisions
Sep 20, 2023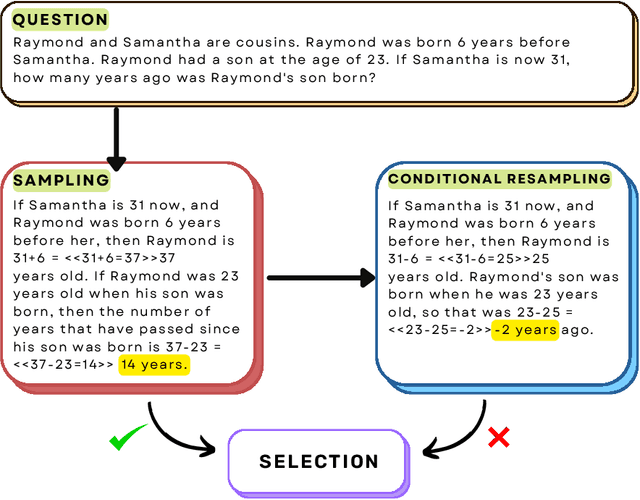
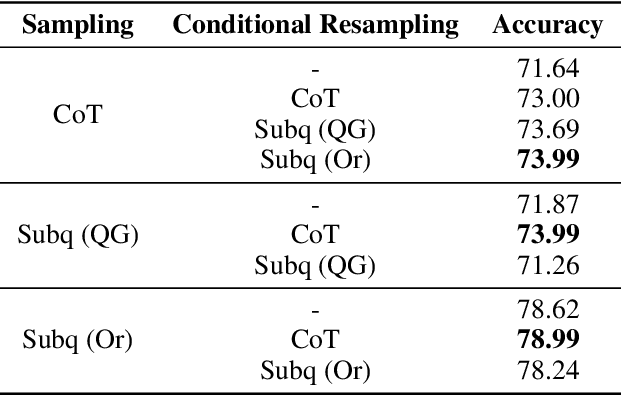
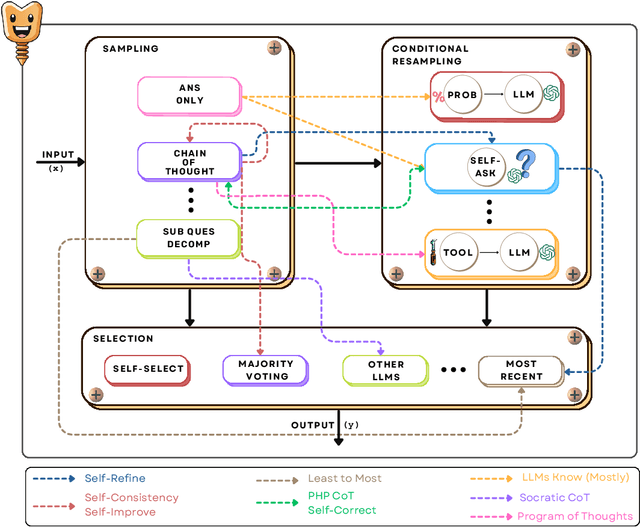

Large language models (LLMs) can improve their accuracy on various tasks through iteratively refining and revising their output based on feedback. We observe that these revisions can introduce errors, in which case it is better to roll back to a previous result. Further, revisions are typically homogeneous: they use the same reasoning method that produced the initial answer, which may not correct errors. To enable exploration in this space, we present SCREWS, a modular framework for reasoning with revisions. It is comprised of three main modules: Sampling, Conditional Resampling, and Selection, each consisting of sub-modules that can be hand-selected per task. We show that SCREWS not only unifies several previous approaches under a common framework, but also reveals several novel strategies for identifying improved reasoning chains. We evaluate our framework with state-of-the-art LLMs (ChatGPT and GPT-4) on a diverse set of reasoning tasks and uncover useful new reasoning strategies for each: arithmetic word problems, multi-hop question answering, and code debugging. Heterogeneous revision strategies prove to be important, as does selection between original and revised candidates.
Natural Language Decomposition and Interpretation of Complex Utterances
May 15, 2023Natural language interfaces often require supervised data to translate user requests into programs, database queries, or other structured intent representations. During data collection, it can be difficult to anticipate and formalize the full range of user needs -- for example, in a system designed to handle simple requests (like $\textit{find my meetings tomorrow}$ or $\textit{move my meeting with my manager to noon})$, users may also express more elaborate requests (like $\textit{swap all my calls on Monday and Tuesday}$). We introduce an approach for equipping a simple language-to-code model to handle complex utterances via a process of hierarchical natural language decomposition. Our approach uses a pre-trained language model to decompose a complex utterance into a sequence of smaller natural language steps, then interprets each step using the language-to-code model. To test our approach, we collect and release DeCU -- a new NL-to-program benchmark to evaluate Decomposition of Complex Utterances. Experiments show that the proposed approach enables the interpretation of complex utterances with almost no complex training data, while outperforming standard few-shot prompting approaches.
Ontologically Faithful Generation of Non-Player Character Dialogues
Dec 20, 2022We introduce a language generation task grounded in a popular video game environment. KNUDGE (KNowledge Constrained User-NPC Dialogue GEneration) involves generating dialogue trees conditioned on an ontology captured in natural language passages providing quest and entity specifications. KNUDGE is constructed from side quest dialogues drawn directly from game data of Obsidian Entertainment's The Outer Worlds, leading to real-world complexities in generation: (1) dialogues are branching trees as opposed to linear chains of utterances; (2) utterances must remain faithful to the game lore--character personas, backstories, and entity relationships; and (3) a dialogue must accurately reveal new quest-related details to the human player. We report results for supervised and in-context learning techniques, finding there is significant room for future work on creating realistic game-quality dialogues.
The Whole Truth and Nothing But the Truth: Faithful and Controllable Dialogue Response Generation with Dataflow Transduction and Constrained Decoding
Sep 16, 2022
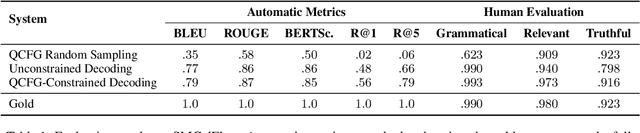
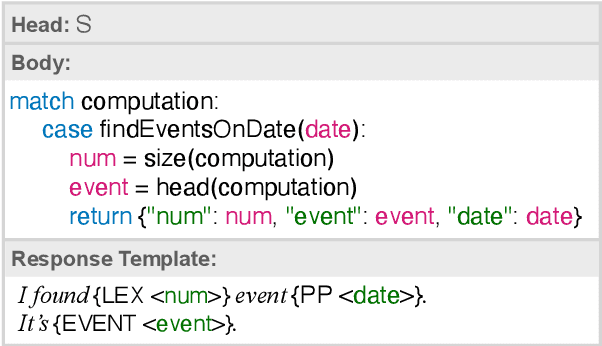
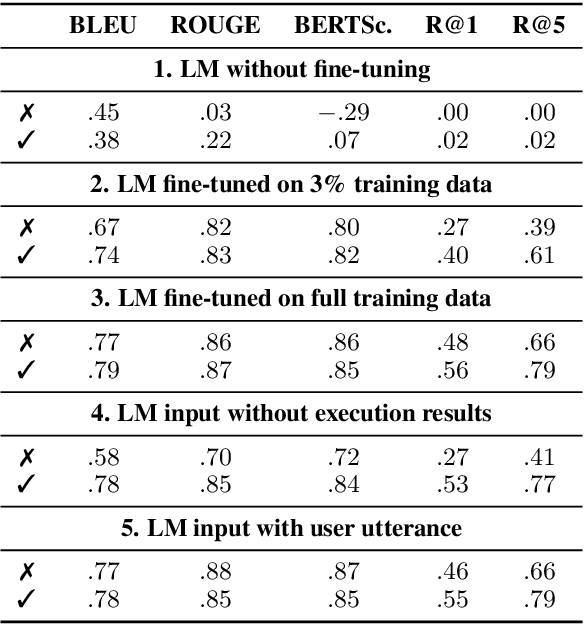
In a real-world dialogue system, generated responses must satisfy several interlocking constraints: being informative, truthful, and easy to control. The two predominant paradigms in language generation -- neural language modeling and rule-based generation -- both struggle to satisfy these constraints. Even the best neural models are prone to hallucination and omission of information, while existing formalisms for rule-based generation make it difficult to write grammars that are both flexible and fluent. We describe a hybrid architecture for dialogue response generation that combines the strengths of both approaches. This architecture has two components. First, a rule-based content selection model defined using a new formal framework called dataflow transduction, which uses declarative rules to transduce a dialogue agent's computations (represented as dataflow graphs) into context-free grammars representing the space of contextually acceptable responses. Second, a constrained decoding procedure that uses these grammars to constrain the output of a neural language model, which selects fluent utterances. The resulting system outperforms both rule-based and learned approaches in human evaluations of fluency, relevance, and truthfulness.
PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation
Sep 16, 2022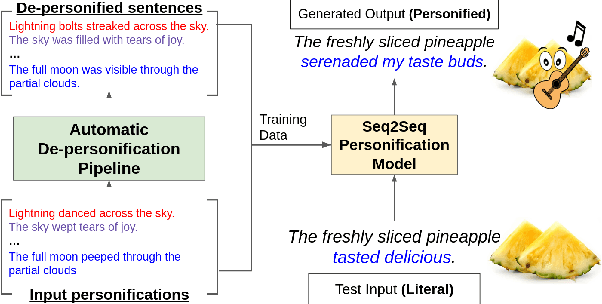
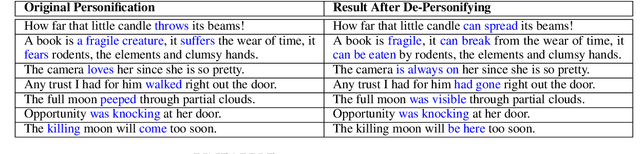
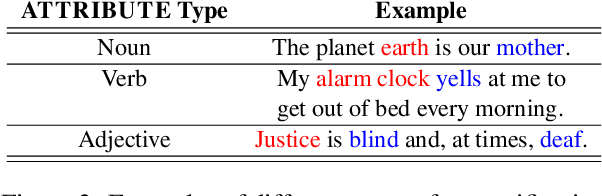
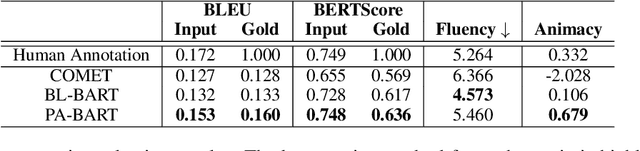
A personification is a figure of speech that endows inanimate entities with properties and actions typically seen as requiring animacy. In this paper, we explore the task of personification generation. To this end, we propose PINEAPPLE: Personifying INanimate Entities by Acquiring Parallel Personification data for Learning Enhanced generation. We curate a corpus of personifications called PersonifCorp, together with automatically generated de-personified literalizations of these personifications. We demonstrate the usefulness of this parallel corpus by training a seq2seq model to personify a given literal input. Both automatic and human evaluations show that fine-tuning with PersonifCorp leads to significant gains in personification-related qualities such as animacy and interestingness. A detailed qualitative analysis also highlights key strengths and imperfections of PINEAPPLE over baselines, demonstrating a strong ability to generate diverse and creative personifications that enhance the overall appeal of a sentence.