 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adapter: Contextualizing Language Models in Parameters with A Single Forward Pass
Nov 08, 2024



Large language models (LMs) are typically adapted to improve performance on new contexts (\eg text prompts that define new tasks or domains) through fine-tuning or prompting. However, there is an accuracy compute tradeoff -- fine-tuning incurs significant training cost and prompting increases inference overhead. We introduce $GenerativeAdapter$, an effective and efficient adaptation method that directly maps new contexts to low-rank LM adapters, thereby significantly reducing inference overhead with no need for finetuning. The adapter generator is trained via self-supervised learning, and can be used to adapt a single frozen LM for any new task simply by mapping the associated task or domain context to a new adapter. We apply $GenerativeAdapter$ to two pretrained LMs (Mistral-7B-Instruct and Llama2-7B-Chat) and evaluate the adapted models in three adaption scenarios: knowledge acquisition from documents, learning from demonstrations, and personalization for users. In StreamingQA, our approach is effective in injecting knowledge into the LM's parameters, achieving a 63.5% improvement in F1 score over the model with supervised fine-tuning (from $19.5$ to $31.5$) for contexts as long as 32K tokens. In the MetaICL in-context learning evaluation, our method achieves an average accuracy of $44.9$ across 26 tasks, outperforming the base model. On MSC, our method proves to be highly competitive in memorizing user information from conversations with a 4x reduction in computation and memory costs compared to prompting with full conversation history. Together, these results suggest that $GenerativeAdapter$ should allow for general adaption to a wide range of different contexts.
Multi-Field Adaptive Retrieval
Oct 26, 2024

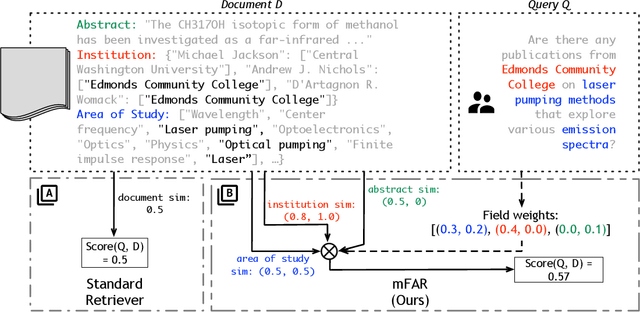
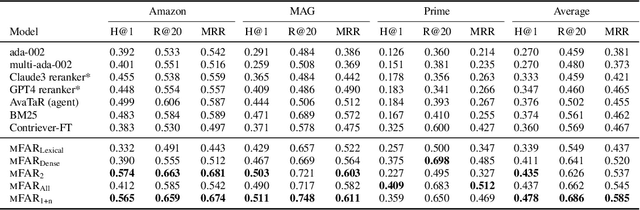
Document retrieval for tasks such as search and retrieval-augmented generation typically involves datasets that are unstructured: free-form text without explicit internal structure in each document. However, documents can have a structured form, consisting of fields such as an article title, message body, or HTML header. To address this gap, we introduce Multi-Field Adaptive Retrieval (MFAR), a flexible framework that accommodates any number of and any type of document indices on structured data. Our framework consists of two main steps: (1) the decomposition of an existing document into fields, each indexed independently through dense and lexical methods, and (2) learning a model which adaptively predicts the importance of a field by conditioning on the document query, allowing on-the-fly weighting of the most likely field(s). We find that our approach allows for the optimized use of dense versus lexical representations across field types, significantly improves in document ranking over a number of existing retrievers, and achieves state-of-the-art performance for multi-field structured data.
SMART: Self-learning Meta-strategy Agent for Reasoning Tasks
Oct 21, 2024Tasks requiring deductive reasoning, especially those involving multiple steps, often demand adaptive strategies such as intermediate generation of rationales or programs, as no single approach is universally optimal. While Language Models (LMs) can enhance their outputs through iterative self-refinement and strategy adjustments, they frequently fail to apply the most effective strategy in their first attempt. This inefficiency raises the question: Can LMs learn to select the optimal strategy in the first attempt, without a need for refinement? To address this challenge, we introduce SMART (Self-learning Meta-strategy Agent for Reasoning Tasks), a novel framework that enables LMs to autonomously learn and select the most effective strategies for various reasoning tasks. We model the strategy selection process as a Markov Decision Process and leverage reinforcement learning-driven continuous self-improvement to allow the model to find the suitable strategy to solve a given task. Unlike traditional self-refinement methods that rely on multiple inference passes or external feedback, SMART allows an LM to internalize the outcomes of its own reasoning processes and adjust its strategy accordingly, aiming for correct solutions on the first attempt. Our experiments across various reasoning datasets and with different model architectures demonstrate that SMART significantly enhances the ability of models to choose optimal strategies without external guidance (+15 points on the GSM8K dataset). By achieving higher accuracy with a single inference pass, SMART not only improves performance but also reduces computational costs for refinement-based strategies, paving the way for more efficient and intelligent reasoning in LMs.
Learning to Retrieve Iteratively for In-Context Learning
Jun 20, 2024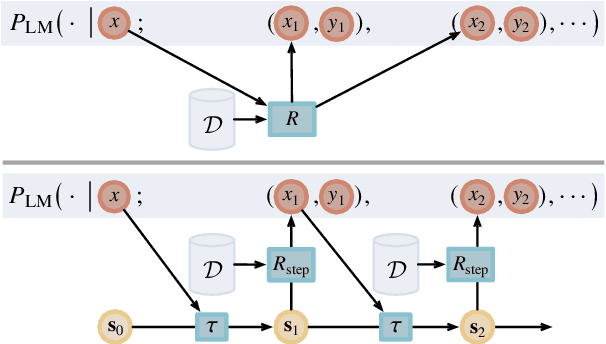
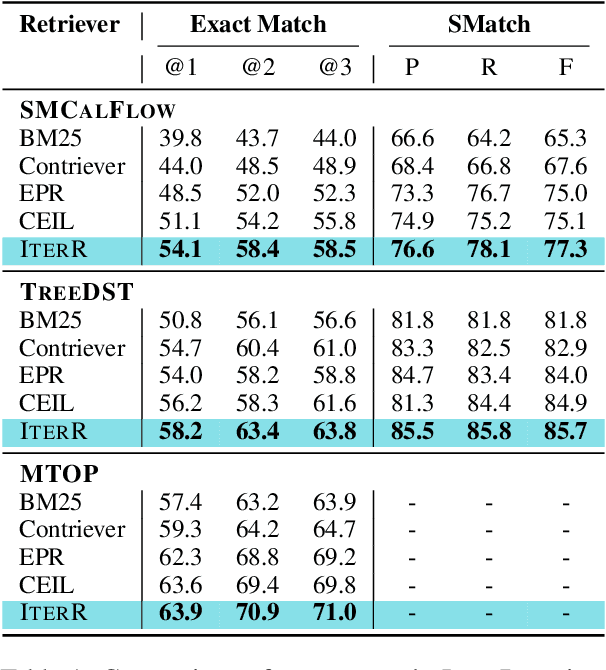
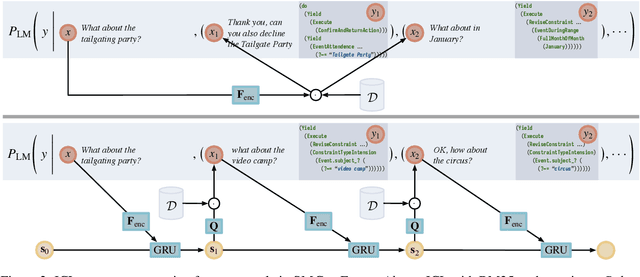
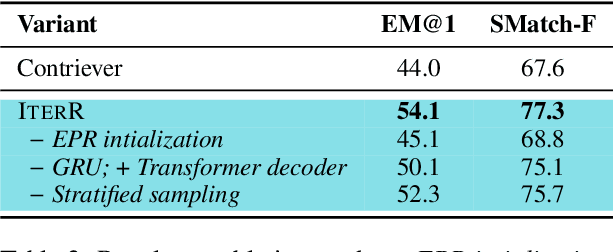
We introduce iterative retrieval, a novel framework that empowers retrievers to make iterative decisions through policy optimization. Finding an optimal portfolio of retrieved items is a combinatorial optimization problem, generally considered NP-hard. This approach provides a learned approximation to such a solution, meeting specific task requirements under a given family of large language models (LLMs). We propose a training procedure based on reinforcement learning, incorporating feedback from LLMs. We instantiate an iterative retriever for composing in-context learning (ICL) exemplars and apply it to various semantic parsing tasks that demand synthesized programs as outputs. By adding only 4M additional parameters for state encoding, we convert an off-the-shelf dense retriever into a stateful iterative retriever, outperforming previous methods in selecting ICL exemplars on semantic parsing datasets such as CalFlow, TreeDST, and MTOP. Additionally, the trained iterative retriever generalizes across different inference LLMs beyond the one used during training.
Interpreting User Requests in the Context of Natural Language Standing Instructions
Nov 16, 2023Users of natural language interfaces, generally powered by Large Language Models (LLMs),often must repeat their preferences each time they make a similar request. To alleviate this, we propose including some of a user's preferences and instructions in natural language -- collectively termed standing instructions -- as additional context for such interfaces. For example, when a user states I'm hungry, their previously expressed preference for Persian food will be automatically added to the LLM prompt, so as to influence the search for relevant restaurants. We develop NLSI, a language-to-program dataset consisting of over 2.4K dialogues spanning 17 domains, where each dialogue is paired with a user profile (a set of users specific standing instructions) and corresponding structured representations (API calls). A key challenge in NLSI is to identify which subset of the standing instructions is applicable to a given dialogue. NLSI contains diverse phenomena, from simple preferences to interdependent instructions such as triggering a hotel search whenever the user is booking tickets to an event. We conduct experiments on NLSI using prompting with large language models and various retrieval approaches, achieving a maximum of 44.7% exact match on API prediction. Our results demonstrate the challenges in identifying the relevant standing instructions and their interpretation into API calls.
SCREWS: A Modular Framework for Reasoning with Revisions
Sep 20, 2023Large language models (LLMs) can improve their accuracy on various tasks through iteratively refining and revising their output based on feedback. We observe that these revisions can introduce errors, in which case it is better to roll back to a previous result. Further, revisions are typically homogeneous: they use the same reasoning method that produced the initial answer, which may not correct errors. To enable exploration in this space, we present SCREWS, a modular framework for reasoning with revisions. It is comprised of three main modules: Sampling, Conditional Resampling, and Selection, each consisting of sub-modules that can be hand-selected per task. We show that SCREWS not only unifies several previous approaches under a common framework, but also reveals several novel strategies for identifying improved reasoning chains. We evaluate our framework with state-of-the-art LLMs (ChatGPT and GPT-4) on a diverse set of reasoning tasks and uncover useful new reasoning strategies for each: arithmetic word problems, multi-hop question answering, and code debugging. Heterogeneous revision strategies prove to be important, as does selection between original and revised candidates.
Few-Shot Adaptation for Parsing Contextual Utterances with LLMs
Sep 18, 2023


We evaluate the ability of semantic parsers based on large language models (LLMs) to handle contextual utterances. In real-world settings, there typically exists only a limited number of annotated contextual utterances due to annotation cost, resulting in an imbalance compared to non-contextual utterances. Therefore, parsers must adapt to contextual utterances with a few training examples. We examine four major paradigms for doing so in conversational semantic parsing i.e., Parse-with-Utterance-History, Parse-with-Reference-Program, Parse-then-Resolve, and Rewrite-then-Parse. To facilitate such cross-paradigm comparisons, we construct SMCalFlow-EventQueries, a subset of contextual examples from SMCalFlow with additional annotations. Experiments with in-context learning and fine-tuning suggest that Rewrite-then-Parse is the most promising paradigm when holistically considering parsing accuracy, annotation cost, and error types.
Natural Language Decomposition and Interpretation of Complex Utterances
May 15, 2023Natural language interfaces often require supervised data to translate user requests into programs, database queries, or other structured intent representations. During data collection, it can be difficult to anticipate and formalize the full range of user needs -- for example, in a system designed to handle simple requests (like $\textit{find my meetings tomorrow}$ or $\textit{move my meeting with my manager to noon})$, users may also express more elaborate requests (like $\textit{swap all my calls on Monday and Tuesday}$). We introduce an approach for equipping a simple language-to-code model to handle complex utterances via a process of hierarchical natural language decomposition. Our approach uses a pre-trained language model to decompose a complex utterance into a sequence of smaller natural language steps, then interprets each step using the language-to-code model. To test our approach, we collect and release DeCU -- a new NL-to-program benchmark to evaluate Decomposition of Complex Utterances. Experiments show that the proposed approach enables the interpretation of complex utterances with almost no complex training data, while outperforming standard few-shot prompting approaches.
Multilingual Coreference Resolution in Multiparty Dialogue
Aug 02, 2022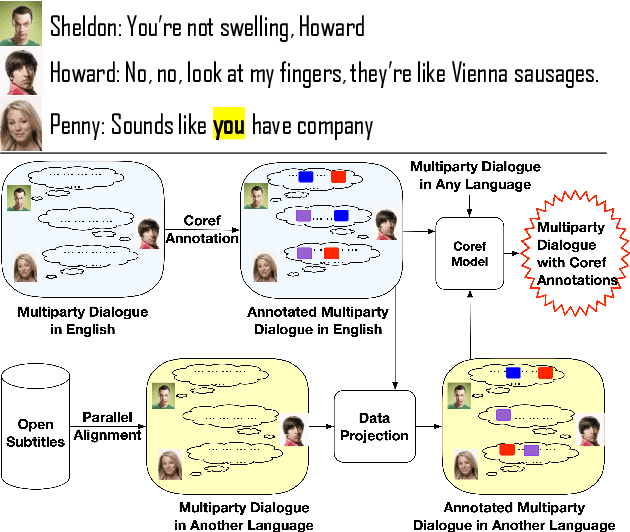
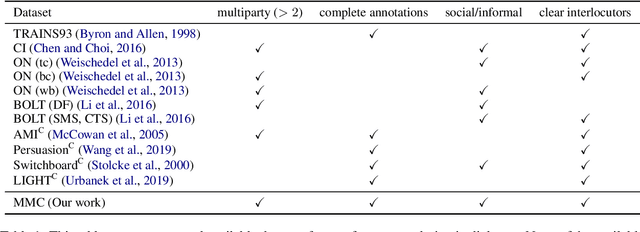
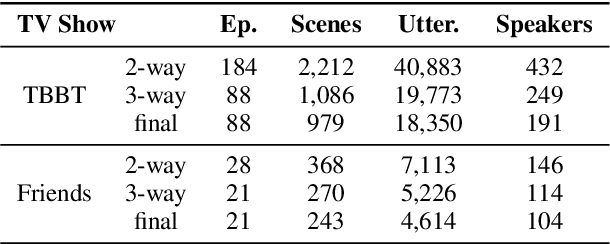
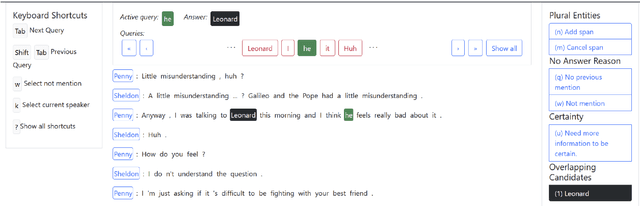
Existing multiparty dialogue datasets for coreference resolution are nascent, and many challenges are still unaddressed. We create a large-scale dataset, Multilingual Multiparty Coref (MMC), for this task based on TV transcripts. Due to the availability of gold-quality subtitles in multiple languages, we propose reusing the annotations to create silver coreference data in other languages (Chinese and Farsi) via annotation projection. On the gold (English) data, off-the-shelf models perform relatively poorly on MMC, suggesting that MMC has broader coverage of multiparty coreference than prior datasets. On the silver data, we find success both using it for data augmentation and training from scratch, which effectively simulates the zero-shot cross-lingual setting.
Pruning Pretrained Encoders with a Multitask Objective
Dec 10, 2021
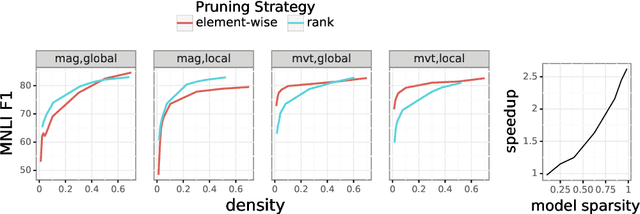
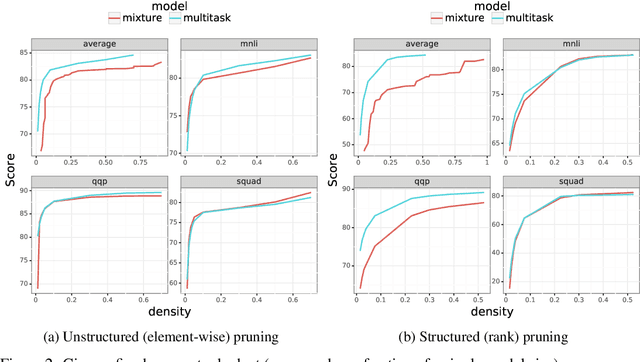

The sizes of pretrained language models make them challenging and expensive to use when there are multiple desired downstream tasks. In this work, we adopt recent strategies for model pruning during finetuning to explore the question of whether it is possible to prune a single encoder so that it can be used for multiple tasks. We allocate a fixed parameter budget and compare pruning a single model with a multitask objective against the best ensemble of single-task models. We find that under two pruning strategies (element-wise and rank pruning), the approach with the multitask objective outperforms training models separately when averaged across all tasks, and it is competitive on each individual one. Additional analysis finds that using a multitask objective during pruning can also be an effective method for reducing model sizes for low-resource tasks.