 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Field Adaptive Retrieval
Paper and Code


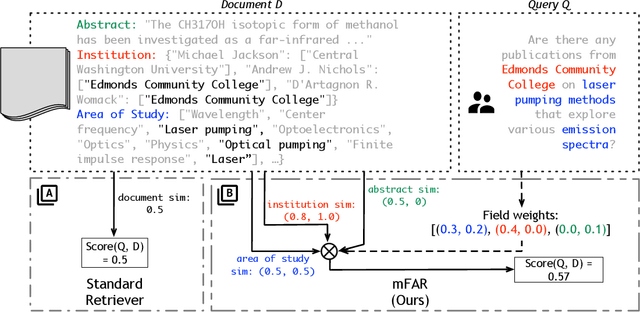
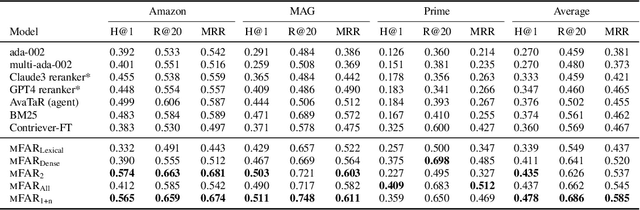
Document retrieval for tasks such as search and retrieval-augmented generation typically involves datasets that are unstructured: free-form text without explicit internal structure in each document. However, documents can have a structured form, consisting of fields such as an article title, message body, or HTML header. To address this gap, we introduce Multi-Field Adaptive Retrieval (MFAR), a flexible framework that accommodates any number of and any type of document indices on structured data. Our framework consists of two main steps: (1) the decomposition of an existing document into fields, each indexed independently through dense and lexical methods, and (2) learning a model which adaptively predicts the importance of a field by conditioning on the document query, allowing on-the-fly weighting of the most likely field(s). We find that our approach allows for the optimized use of dense versus lexical representations across field types, significantly improves in document ranking over a number of existing retrievers, and achieves state-of-the-art performance for multi-field structured data.