 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKirchhoff-Inspired Neural Networks for Evolving High-Order Perception
Mar 25, 2026Deep learning architectures are fundamentally inspired by neuroscience, particularly the structure of the brain's sensory pathways, and have achieved remarkable success in learning informative data representations. Although these architectures mimic the communication mechanisms of biological neurons, their strategies for information encoding and transmission are fundamentally distinct. Biological systems depend on dynamic fluctuations in membrane potential; by contrast, conventional deep networks optimize weights and biases by adjusting the strengths of inter-neural connections, lacking a systematic mechanism to jointly characterize the interplay among signal intensity, coupling structure, and state evolution. To tackle this limitation, we propose the Kirchhoff-Inspired Neural Network (KINN), a state-variable-based network architecture constructed based on Kirchhoff's current law. KINN derives numerically stable state updates from fundamental ordinary differential equations, enabling the explicit decoupling and encoding of higher-order evolutionary components within a single layer while preserving physical consistency, interpretability, and end-to-end trainability. Extensive experiments on partial differential equation (PDE) solving and ImageNet image classification validate that KINN outperforms state-of-the-art existing methods.
AMLRIS: Alignment-aware Masked Learning for Referring Image Segmentation
Feb 26, 2026Referring Image Segmentation (RIS) aims to segment an object in an image identified by a natural language expression. The paper introduces Alignment-Aware Masked Learning (AML), a training strategy to enhance RIS by explicitly estimating pixel-level vision-language alignment, filtering out poorly aligned regions during optimization, and focusing on trustworthy cues. This approach results in state-of-the-art performance on RefCOCO datasets and also enhances robustness to diverse descriptions and scenarios
UrbanGS: A Scalable and Efficient Architecture for Geometrically Accurate Large-Scene Reconstruction
Feb 02, 2026While 3D Gaussian Splatting (3DGS) enables high-quality, real-time rendering for bounded scenes, its extension to large-scale urban environments gives rise to critical challenges in terms of geometric consistency, memory efficiency, and computational scalability. To address these issues, we present UrbanGS, a scalable reconstruction framework that effectively tackles these challenges for city-scale applications. First, we propose a Depth-Consistent D-Normal Regularization module. Unlike existing approaches that rely solely on monocular normal estimators, which can effectively update rotation parameters yet struggle to update position parameters, our method integrates D-Normal constraints with external depth supervision. This allows for comprehensive updates of all geometric parameters. By further incorporating an adaptive confidence weighting mechanism based on gradient consistency and inverse depth deviation, our approach significantly enhances multi-view depth alignment and geometric coherence, which effectively resolves the issue of geometric accuracy in complex large-scale scenes. To improve scalability, we introduce a Spatially Adaptive Gaussian Pruning (SAGP) strategy, which dynamically adjusts Gaussian density based on local geometric complexity and visibility to reduce redundancy. Additionally, a unified partitioning and view assignment scheme is designed to eliminate boundary artifacts and optimize computational load. Extensive experiments on multiple urban datasets demonstrate that UrbanGS achieves superior performance in rendering quality, geometric accuracy, and memory efficiency, providing a systematic solution for high-fidelity large-scale scene reconstruction.
HRGS: Hierarchical Gaussian Splatting for Memory-Efficient High-Resolution 3D Reconstruction
Jun 17, 2025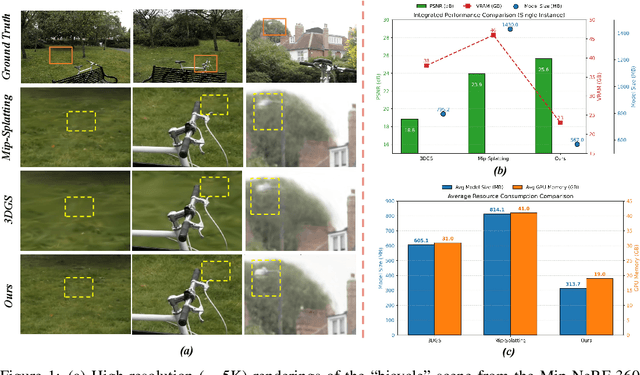

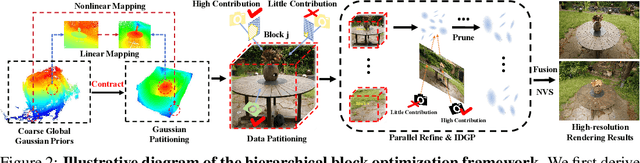

3D Gaussian Splatting (3DGS) has made significant strides in real-time 3D scene reconstruction, but faces memory scalability issues in high-resolution scenarios. To address this, we propose Hierarchical Gaussian Splatting (HRGS), a memory-efficient framework with hierarchical block-level optimization. First, we generate a global, coarse Gaussian representation from low-resolution data. Then, we partition the scene into multiple blocks, refining each block with high-resolution data. The partitioning involves two steps: Gaussian partitioning, where irregular scenes are normalized into a bounded cubic space with a uniform grid for task distribution, and training data partitioning, where only relevant observations are retained for each block. By guiding block refinement with the coarse Gaussian prior, we ensure seamless Gaussian fusion across adjacent blocks. To reduce computational demands, we introduce Importance-Driven Gaussian Pruning (IDGP), which computes importance scores for each Gaussian and removes those with minimal contribution, speeding up convergence and reducing memory usage. Additionally, we incorporate normal priors from a pretrained model to enhance surface reconstruction quality. Our method enables high-quality, high-resolution 3D scene reconstruction even under memory constraints. Extensive experiments on three benchmarks show that HRGS achieves state-of-the-art performance in high-resolution novel view synthesis (NVS) and surface reconstruction tasks.
Hierarchical corpus encoder: Fusing generative retrieval and dense indices
Feb 26, 2025



Generative retrieval employs sequence models for conditional generation of document IDs based on a query (DSI (Tay et al., 2022); NCI (Wang et al., 2022); inter alia). While this has led to improved performance in zero-shot retrieval, it is a challenge to support documents not seen during training. We identify the performance of generative retrieval lies in contrastive training between sibling nodes in a document hierarchy. This motivates our proposal, the hierarchical corpus encoder (HCE), which can be supported by traditional dense encoders. Our experiments show that HCE achieves superior results than generative retrieval models under both unsupervised zero-shot and supervised settings, while also allowing the easy addition and removal of documents to the index.
Prompt as Knowledge Bank: Boost Vision-language model via Structural Representation for zero-shot medical detection
Feb 22, 2025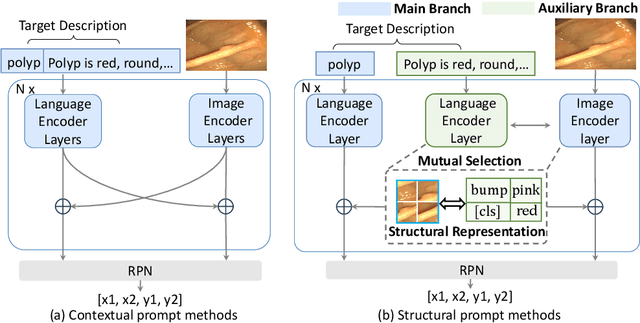

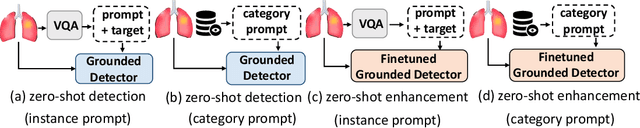

Zero-shot medical detection can further improve detection performance without relying on annotated medical images even upon the fine-tuned model, showing great clinical value. Recent studies leverage grounded vision-language models (GLIP) to achieve this by using detailed disease descriptions as prompts for the target disease name during the inference phase. However, these methods typically treat prompts as equivalent context to the target name, making it difficult to assign specific disease knowledge based on visual information, leading to a coarse alignment between images and target descriptions. In this paper, we propose StructuralGLIP, which introduces an auxiliary branch to encode prompts into a latent knowledge bank layer-by-layer, enabling more context-aware and fine-grained alignment. Specifically, in each layer, we select highly similar features from both the image representation and the knowledge bank, forming structural representations that capture nuanced relationships between image patches and target descriptions. These features are then fused across modalities to further enhance detection performance. Extensive experiments demonstrate that StructuralGLIP achieves a +4.1\% AP improvement over prior state-of-the-art methods across seven zero-shot medical detection benchmarks, and consistently improves fine-tuned models by +3.2\% AP on endoscopy image datasets.
Multi-Field Adaptive Retrieval
Oct 26, 2024

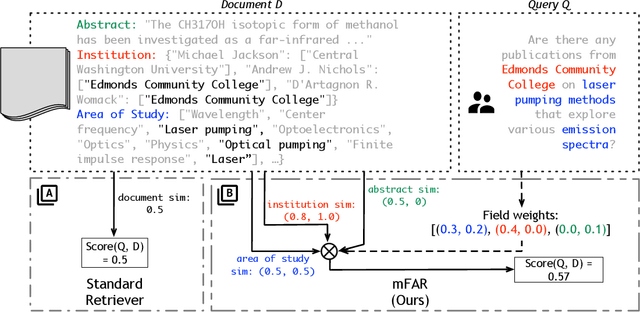
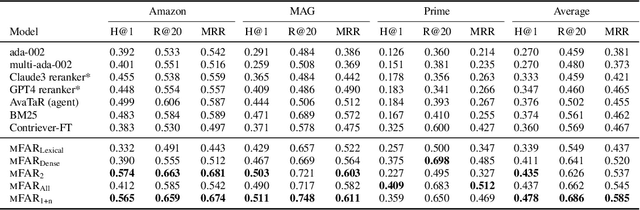
Document retrieval for tasks such as search and retrieval-augmented generation typically involves datasets that are unstructured: free-form text without explicit internal structure in each document. However, documents can have a structured form, consisting of fields such as an article title, message body, or HTML header. To address this gap, we introduce Multi-Field Adaptive Retrieval (MFAR), a flexible framework that accommodates any number of and any type of document indices on structured data. Our framework consists of two main steps: (1) the decomposition of an existing document into fields, each indexed independently through dense and lexical methods, and (2) learning a model which adaptively predicts the importance of a field by conditioning on the document query, allowing on-the-fly weighting of the most likely field(s). We find that our approach allows for the optimized use of dense versus lexical representations across field types, significantly improves in document ranking over a number of existing retrievers, and achieves state-of-the-art performance for multi-field structured data.
Learning to Retrieve Iteratively for In-Context Learning
Jun 20, 2024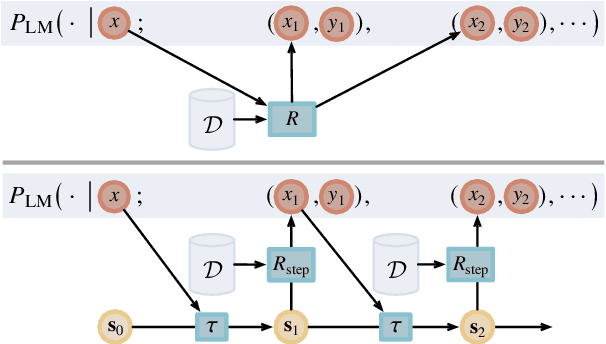
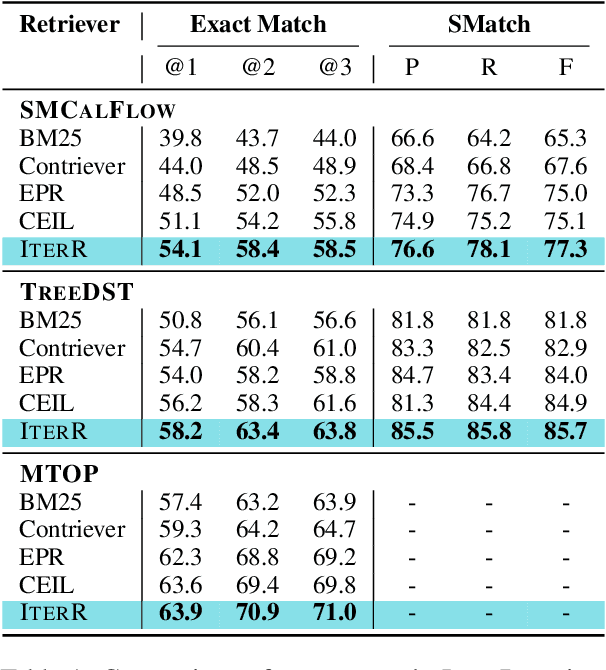
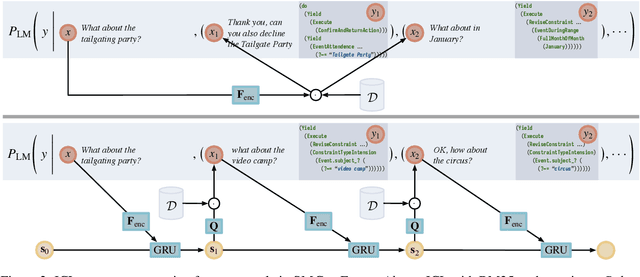
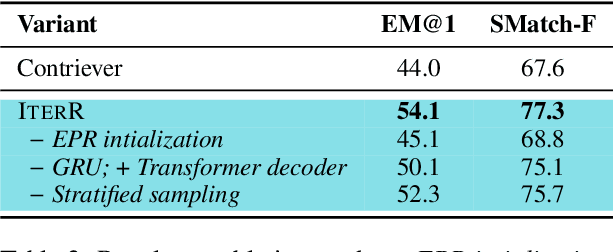
We introduce iterative retrieval, a novel framework that empowers retrievers to make iterative decisions through policy optimization. Finding an optimal portfolio of retrieved items is a combinatorial optimization problem, generally considered NP-hard. This approach provides a learned approximation to such a solution, meeting specific task requirements under a given family of large language models (LLMs). We propose a training procedure based on reinforcement learning, incorporating feedback from LLMs. We instantiate an iterative retriever for composing in-context learning (ICL) exemplars and apply it to various semantic parsing tasks that demand synthesized programs as outputs. By adding only 4M additional parameters for state encoding, we convert an off-the-shelf dense retriever into a stateful iterative retriever, outperforming previous methods in selecting ICL exemplars on semantic parsing datasets such as CalFlow, TreeDST, and MTOP. Additionally, the trained iterative retriever generalizes across different inference LLMs beyond the one used during training.
Streaming Sequence Transduction through Dynamic Compression
Feb 02, 2024



We introduce STAR (Stream Transduction with Anchor Representations), a novel Transformer-based model designed for efficient sequence-to-sequence transduction over streams. STAR dynamically segments input streams to create compressed anchor representations, achieving nearly lossless compression (12x) in Automatic Speech Recognition (ASR) and outperforming existing methods. Moreover, STAR demonstrates superior segmentation and latency-quality trade-offs in simultaneous speech-to-text tasks, optimizing latency, memory footprint, and quality.
A Unified View of Evaluation Metrics for Structured Prediction
Oct 20, 2023

We present a conceptual framework that unifies a variety of evaluation metrics for different structured prediction tasks (e.g. event and relation extraction, syntactic and semantic parsing). Our framework requires representing the outputs of these tasks as objects of certain data types, and derives metrics through matching of common substructures, possibly followed by normalization. We demonstrate how commonly used metrics for a number of tasks can be succinctly expressed by this framework, and show that new metrics can be naturally derived in a bottom-up way based on an output structure. We release a library that enables this derivation to create new metrics. Finally, we consider how specific characteristics of tasks motivate metric design decisions, and suggest possible modifications to existing metrics in line with those motivations.