 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Retrieve Iteratively for In-Context Learning
Jun 20, 2024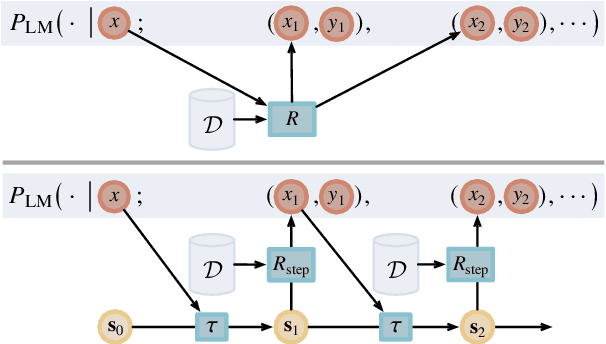
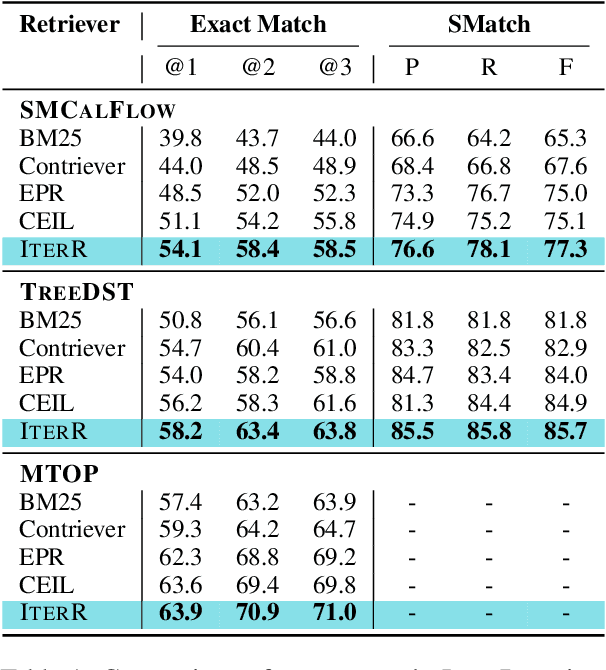
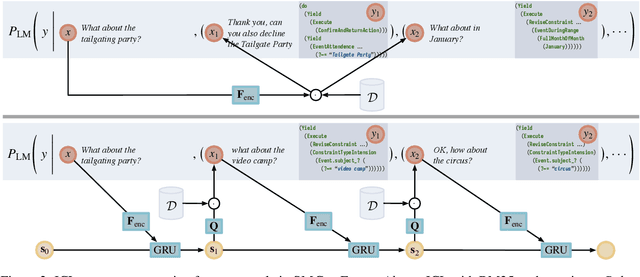
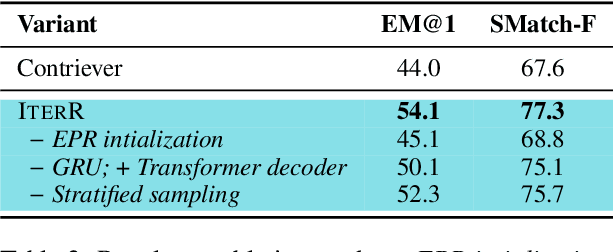
We introduce iterative retrieval, a novel framework that empowers retrievers to make iterative decisions through policy optimization. Finding an optimal portfolio of retrieved items is a combinatorial optimization problem, generally considered NP-hard. This approach provides a learned approximation to such a solution, meeting specific task requirements under a given family of large language models (LLMs). We propose a training procedure based on reinforcement learning, incorporating feedback from LLMs. We instantiate an iterative retriever for composing in-context learning (ICL) exemplars and apply it to various semantic parsing tasks that demand synthesized programs as outputs. By adding only 4M additional parameters for state encoding, we convert an off-the-shelf dense retriever into a stateful iterative retriever, outperforming previous methods in selecting ICL exemplars on semantic parsing datasets such as CalFlow, TreeDST, and MTOP. Additionally, the trained iterative retriever generalizes across different inference LLMs beyond the one used during training.
ToolTalk: Evaluating Tool-Usage in a Conversational Setting
Nov 15, 2023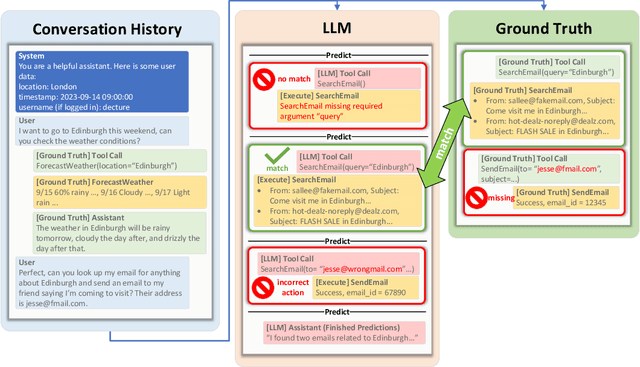



Large language models (LLMs) have displayed massive improvements in reasoning and decision-making skills and can hold natural conversations with users. Many recent works seek to augment LLM-based assistants with external tools so they can access private or up-to-date information and carry out actions on behalf of users. To better measure the performance of these assistants, this paper introduces ToolTalk, a benchmark consisting of complex user intents requiring multi-step tool usage specified through dialogue. ToolTalk contains 28 tools grouped into 7 plugins, and includes a complete simulated implementation of each tool, allowing for fully automated evaluation of assistants that rely on execution feedback. ToolTalk also emphasizes tools that externally affect the world rather than only tools for referencing or searching information. We evaluate GPT-3.5 and GPT-4 on ToolTalk resulting in success rates of 26% and 50% respectively. Our analysis of the errors reveals three major categories and suggests some future directions for improvement. We release ToolTalk at https://github.com/microsoft/ToolTalk.
Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation
Sep 21, 2023



We study the problem of in-context learning (ICL) with large language models (LLMs) on private datasets. This scenario poses privacy risks, as LLMs may leak or regurgitate the private examples demonstrated in the prompt. We propose a novel algorithm that generates synthetic few-shot demonstrations from the private dataset with formal differential privacy (DP) guarantees, and show empirically that it can achieve effective ICL. We conduct extensive experiments on standard benchmarks and compare our algorithm with non-private ICL and zero-shot solutions. Our results demonstrate that our algorithm can achieve competitive performance with strong privacy levels. These results open up new possibilities for ICL with privacy protection for a broad range of applications.
Privacy-Preserving Domain Adaptation of Semantic Parsers
Dec 20, 2022



Task-oriented dialogue systems often assist users with personal or confidential matters. For this reason, the developers of such a system are generally prohibited from observing actual usage. So how can they know where the system is failing and needs more training data or new functionality? In this work, we study ways in which realistic user utterances can be generated synthetically, to help increase the linguistic and functional coverage of the system, without compromising the privacy of actual users. To this end, we propose a two-stage Differentially Private (DP) generation method which first generates latent semantic parses, and then generates utterances based on the parses. Our proposed approach improves MAUVE by 3.8$\times$ and parse tree node-type overlap by 1.4$\times$ relative to current approaches for private synthetic data generation, improving both on fluency and semantic coverage. We further validate our approach on a realistic domain adaptation task of adding new functionality from private user data to a semantic parser, and show gains of 1.3$\times$ on its accuracy with the new feature.
BenchCLAMP: A Benchmark for Evaluating Language Models on Semantic Parsing
Jun 21, 2022
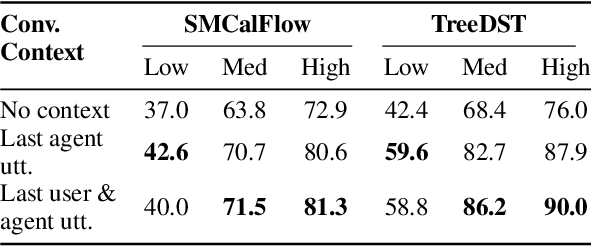
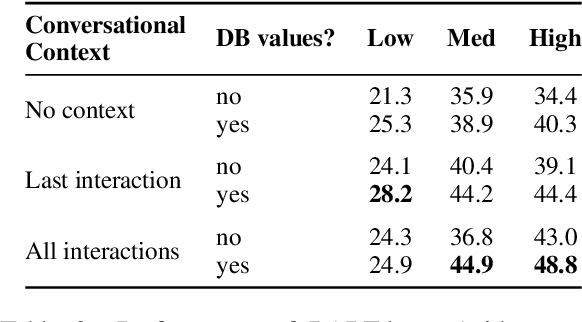

We introduce BenchCLAMP, a Benchmark to evaluate Constrained LAnguage Model Parsing, which produces semantic outputs based on the analysis of input text through constrained decoding of a prompted or fine-tuned language model. Developers of pretrained language models currently benchmark on classification, span extraction and free-text generation tasks. Semantic parsing is neglected in language model evaluation because of the complexity of handling task-specific architectures and representations. Recent work has shown that generation from a prompted or fine-tuned language model can perform well at semantic parsing when the output is constrained to be a valid semantic representation. BenchCLAMP includes context-free grammars for six semantic parsing datasets with varied output meaning representations, as well as a constrained decoding interface to generate outputs covered by these grammars. We provide low, medium, and high resource splits for each dataset, allowing accurate comparison of various language models under different data regimes. Our benchmark supports both prompt-based learning as well as fine-tuning, and provides an easy-to-use toolkit for language model developers to evaluate on semantic parsing.
Addressing Resource and Privacy Constraints in Semantic Parsing Through Data Augmentation
May 18, 2022
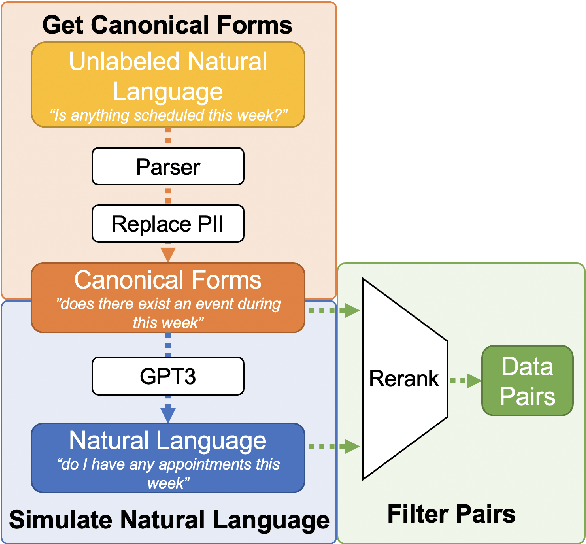


We introduce a novel setup for low-resource task-oriented semantic parsing which incorporates several constraints that may arise in real-world scenarios: (1) lack of similar datasets/models from a related domain, (2) inability to sample useful logical forms directly from a grammar, and (3) privacy requirements for unlabeled natural utterances. Our goal is to improve a low-resource semantic parser using utterances collected through user interactions. In this highly challenging but realistic setting, we investigate data augmentation approaches involving generating a set of structured canonical utterances corresponding to logical forms, before simulating corresponding natural language and filtering the resulting pairs. We find that such approaches are effective despite our restrictive setup: in a low-resource setting on the complex SMCalFlow calendaring dataset (Andreas et al., 2020), we observe 33% relative improvement over a non-data-augmented baseline in top-1 match.
Few-Shot Semantic Parsing with Language Models Trained On Code
Dec 16, 2021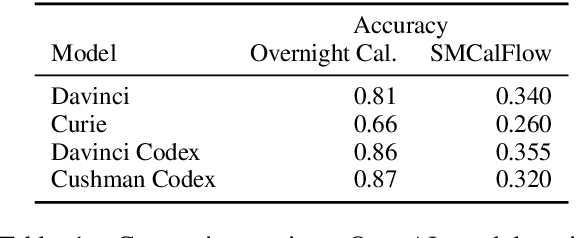
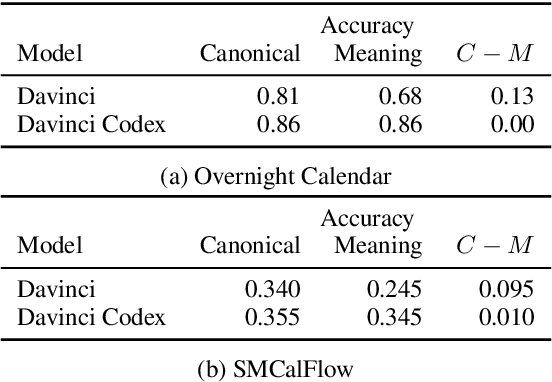
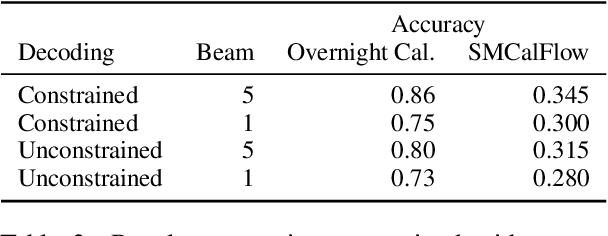
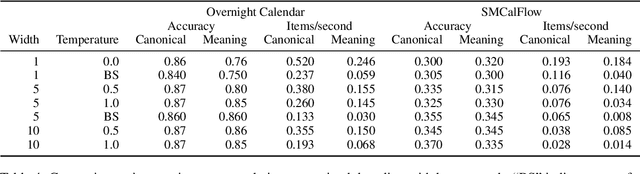
Large language models, prompted with in-context examples, can perform semantic parsing with little training data. They do better when we formulate the problem as paraphrasing into canonical utterances, which cast the underlying meaning representations into a controlled natural language-like representation. Intuitively, such models can more easily output canonical utterances as they are closer to the natural language used for pre-training. More recently, models also pre-trained on code, like OpenAI Codex, have risen in prominence. Since accurately modeling code requires understanding of executable semantics. such models may prove more adept at semantic parsing. In this paper, we test this hypothesis and find that Codex performs better at semantic parsing than equivalent GPT-3 models. We find that unlike GPT-3, Codex performs similarly when targeting meaning representations directly, perhaps as meaning representations used in semantic parsing are structured similar to code.
Pruning Pretrained Encoders with a Multitask Objective
Dec 10, 2021
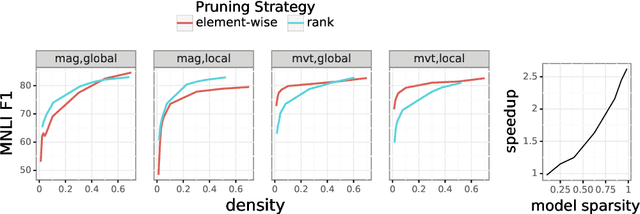
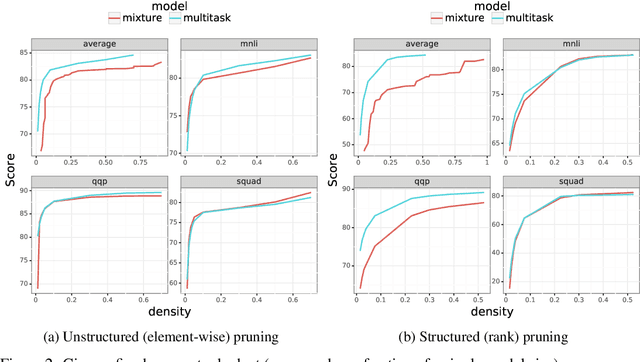

The sizes of pretrained language models make them challenging and expensive to use when there are multiple desired downstream tasks. In this work, we adopt recent strategies for model pruning during finetuning to explore the question of whether it is possible to prune a single encoder so that it can be used for multiple tasks. We allocate a fixed parameter budget and compare pruning a single model with a multitask objective against the best ensemble of single-task models. We find that under two pruning strategies (element-wise and rank pruning), the approach with the multitask objective outperforms training models separately when averaged across all tasks, and it is competitive on each individual one. Additional analysis finds that using a multitask objective during pruning can also be an effective method for reducing model sizes for low-resource tasks.
Constrained Language Models Yield Few-Shot Semantic Parsers
Apr 18, 2021

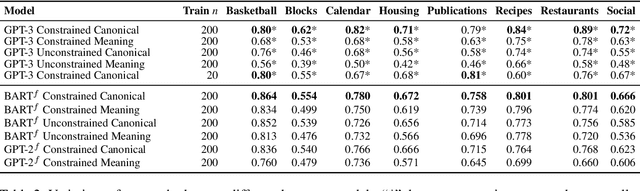

We explore the use of large pretrained language models as few-shot semantic parsers. The goal in semantic parsing is to generate a structured meaning representation given a natural language input. However, language models are trained to generate natural language. To bridge the gap, we use language models to paraphrase inputs into a controlled sublanguage resembling English that can be automatically mapped to a target meaning representation. With a small amount of data and very little code to convert into English-like representations, we provide a blueprint for rapidly bootstrapping semantic parsers and demonstrate good performance on multiple tasks.
Hierarchical Variational Imitation Learning of Control Programs
Dec 29, 2019
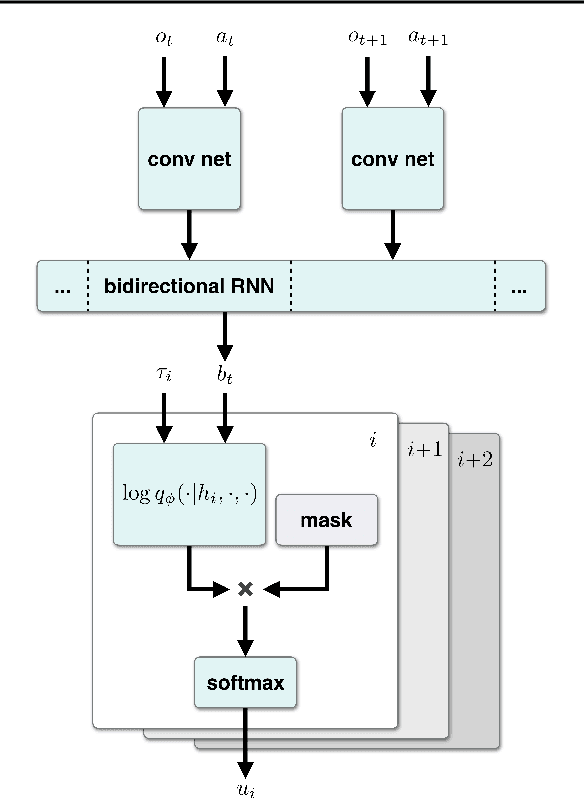
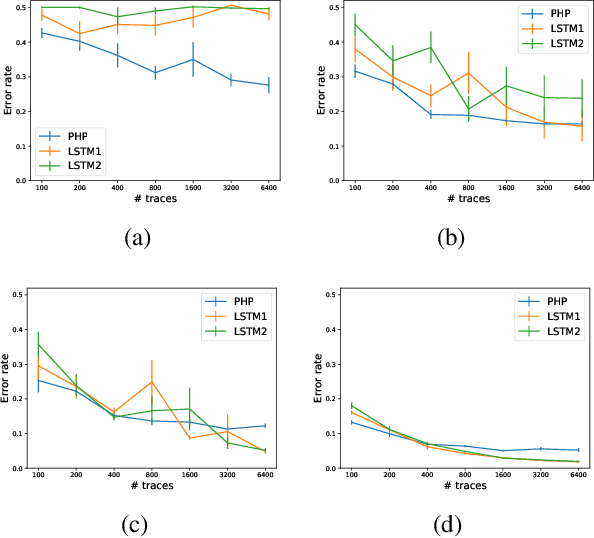
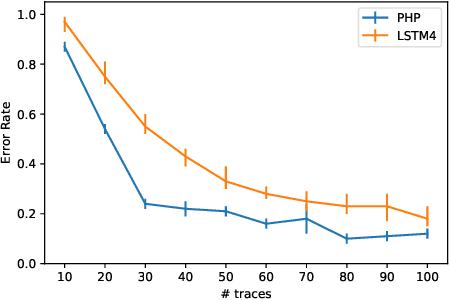
Autonomous agents can learn by imitating teacher demonstrations of the intended behavior. Hierarchical control policies are ubiquitously useful for such learning, having the potential to break down structured tasks into simpler sub-tasks, thereby improving data efficiency and generalization. In this paper, we propose a variational inference method for imitation learning of a control policy represented by parametrized hierarchical procedures (PHP), a program-like structure in which procedures can invoke sub-procedures to perform sub-tasks. Our method discovers the hierarchical structure in a dataset of observation-action traces of teacher demonstrations, by learning an approximate posterior distribution over the latent sequence of procedure calls and terminations. Samples from this learned distribution then guide the training of the hierarchical control policy. We identify and demonstrate a novel benefit of variational inference in the context of hierarchical imitation learning: in decomposing the policy into simpler procedures, inference can leverage acausal information that is unused by other methods. Training PHP with variational inference outperforms LSTM baselines in terms of data efficiency and generalization, requiring less than half as much data to achieve a 24% error rate in executing the bubble sort algorithm, and to achieve no error in executing Karel programs.