 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Quality and Variation: Spam Filtering Distorts Data Label Distributions
Sep 10, 2025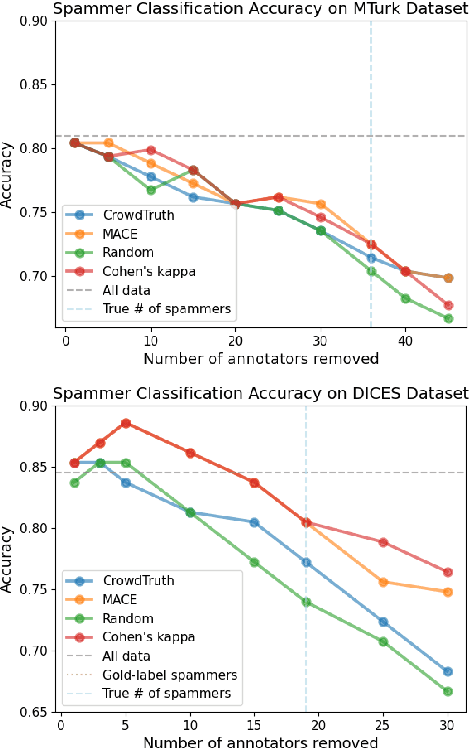
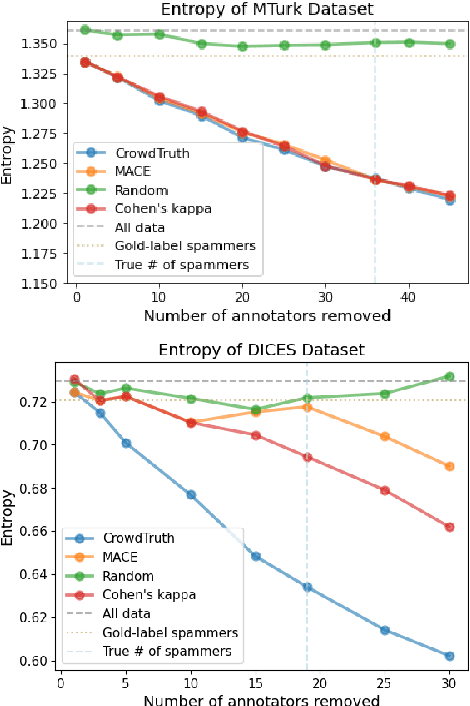
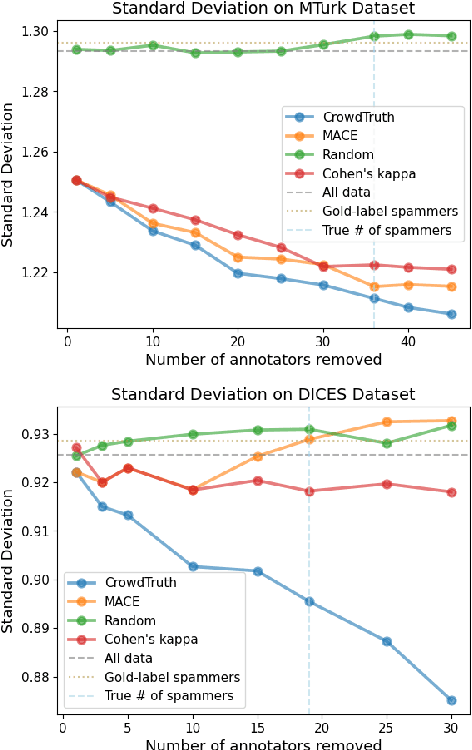
For machine learning datasets to accurately represent diverse opinions in a population, they must preserve variation in data labels while filtering out spam or low-quality responses. How can we balance annotator reliability and representation? We empirically evaluate how a range of heuristics for annotator filtering affect the preservation of variation on subjective tasks. We find that these methods, designed for contexts in which variation from a single ground-truth label is considered noise, often remove annotators who disagree instead of spam annotators, introducing suboptimal tradeoffs between accuracy and label diversity. We find that conservative settings for annotator removal (<5%) are best, after which all tested methods increase the mean absolute error from the true average label. We analyze performance on synthetic spam to observe that these methods often assume spam annotators are less random than real spammers tend to be: most spammers are distributionally indistinguishable from real annotators, and the minority that are distinguishable tend to give fixed answers, not random ones. Thus, tasks requiring the preservation of variation reverse the intuition of existing spam filtering methods: spammers tend to be less random than non-spammers, so metrics that assume variation is spam fare worse. These results highlight the need for spam removal methods that account for label diversity.
Multi-module GRPO: Composing Policy Gradients and Prompt Optimization for Language Model Programs
Aug 06, 2025Group Relative Policy Optimization (GRPO) has proven to be an effective tool for post-training language models (LMs). However, AI systems are increasingly expressed as modular programs that mix together multiple LM calls with distinct prompt templates and other tools, and it is not clear how best to leverage GRPO to improve these systems. We begin to address this challenge by defining mmGRPO, a simple multi-module generalization of GRPO that groups LM calls by module across rollouts and handles variable-length and interrupted trajectories. We find that mmGRPO, composed with automatic prompt optimization, improves accuracy by 11% on average across classification, many-hop search, and privacy-preserving delegation tasks against the post-trained LM, and by 5% against prompt optimization on its own. We open-source mmGRPO in DSPy as the dspy.GRPO optimizer.
Measuring General Intelligence with Generated Games
May 12, 2025We present gg-bench, a collection of game environments designed to evaluate general reasoning capabilities in language models. Unlike most static benchmarks, gg-bench is a data generating process where new evaluation instances can be generated at will. In particular, gg-bench is synthetically generated by (1) using a large language model (LLM) to generate natural language descriptions of novel games, (2) using the LLM to implement each game in code as a Gym environment, and (3) training reinforcement learning (RL) agents via self-play on the generated games. We evaluate language models by their winrate against these RL agents by prompting models with the game description, current board state, and a list of valid moves, after which models output the moves they wish to take. gg-bench is challenging: state-of-the-art LLMs such as GPT-4o and Claude 3.7 Sonnet achieve winrates of 7-9% on gg-bench using in-context learning, while reasoning models such as o1, o3-mini and DeepSeek-R1 achieve average winrates of 31-36%. We release the generated games, data generation process, and evaluation code in order to support future modeling work and expansion of our benchmark.
Why Do Multi-Agent LLM Systems Fail?
Mar 17, 2025Despite growing enthusiasm for Multi-Agent Systems (MAS), where multiple LLM agents collaborate to accomplish tasks, their performance gains across popular benchmarks remain minimal compared to single-agent frameworks. This gap highlights the need to analyze the challenges hindering MAS effectiveness. In this paper, we present the first comprehensive study of MAS challenges. We analyze five popular MAS frameworks across over 150 tasks, involving six expert human annotators. We identify 14 unique failure modes and propose a comprehensive taxonomy applicable to various MAS frameworks. This taxonomy emerges iteratively from agreements among three expert annotators per study, achieving a Cohen's Kappa score of 0.88. These fine-grained failure modes are organized into 3 categories, (i) specification and system design failures, (ii) inter-agent misalignment, and (iii) task verification and termination. To support scalable evaluation, we integrate MASFT with LLM-as-a-Judge. We also explore if identified failures could be easily prevented by proposing two interventions: improved specification of agent roles and enhanced orchestration strategies. Our findings reveal that identified failures require more complex solutions, highlighting a clear roadmap for future research. We open-source our dataset and LLM annotator.
Enough Coin Flips Can Make LLMs Act Bayesian
Mar 06, 2025Large language models (LLMs) exhibit the ability to generalize given few-shot examples in their input prompt, an emergent capability known as in-context learning (ICL). We investigate whether LLMs utilize ICL to perform structured reasoning in ways that are consistent with a Bayesian framework or rely on pattern matching. Using a controlled setting of biased coin flips, we find that: (1) LLMs often possess biased priors, causing initial divergence in zero-shot settings, (2) in-context evidence outweighs explicit bias instructions, (3) LLMs broadly follow Bayesian posterior updates, with deviations primarily due to miscalibrated priors rather than flawed updates, and (4) attention magnitude has negligible effect on Bayesian inference. With sufficient demonstrations of biased coin flips via ICL, LLMs update their priors in a Bayesian manner.
LangProBe: a Language Programs Benchmark
Feb 27, 2025
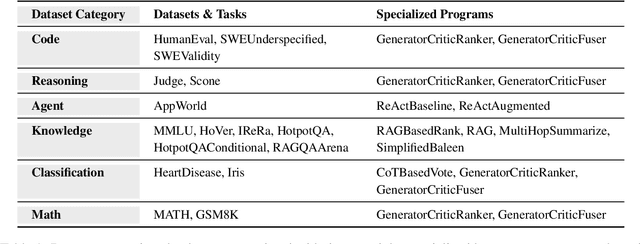
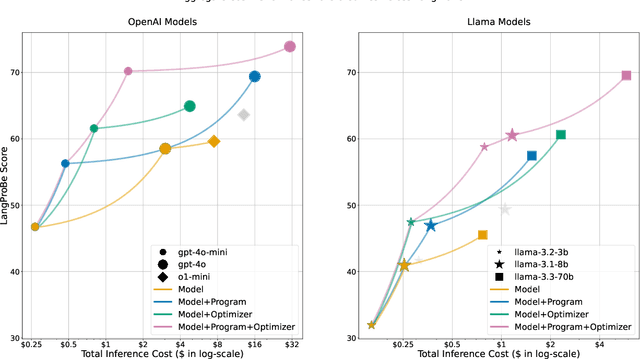
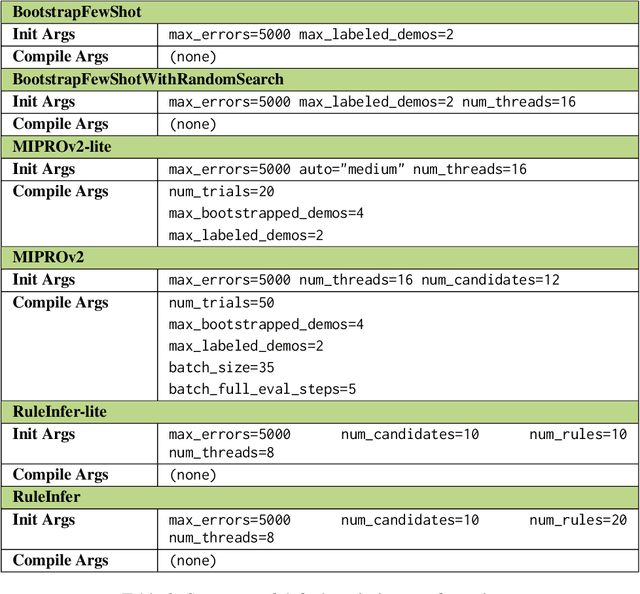
Composing language models (LMs) into multi-step language programs and automatically optimizing their modular prompts is now a mainstream paradigm for building AI systems, but the tradeoffs in this space have only scarcely been studied before. We introduce LangProBe, the first large-scale benchmark for evaluating the architectures and optimization strategies for language programs, with over 2000 combinations of tasks, architectures, optimizers, and choices of LMs. Using LangProBe, we are the first to study the impact of program architectures and optimizers (and their compositions together and with different models) on tradeoffs of quality and cost. We find that optimized language programs offer strong cost--quality Pareto improvement over raw calls to models, but simultaneously demonstrate that human judgment (or empirical decisions) about which compositions to pursue is still necessary for best performance. We will open source the code and evaluation data for LangProBe.
Predicting Emergent Capabilities by Finetuning
Nov 25, 2024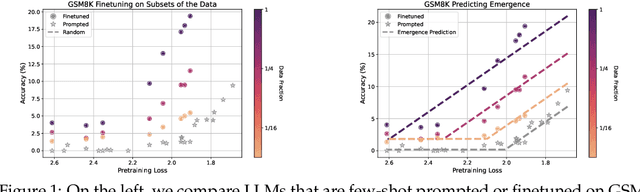

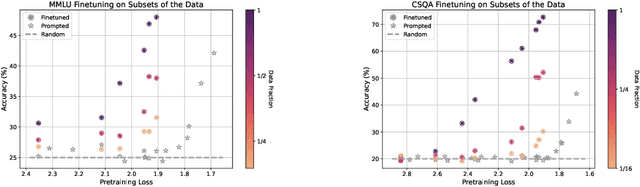
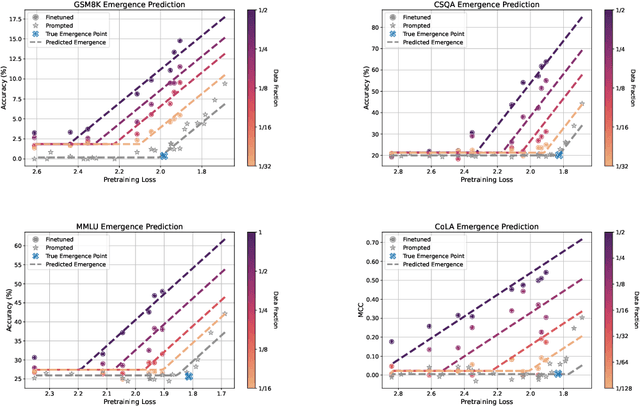
A fundamental open challenge in modern LLM scaling is the lack of understanding around emergent capabilities. In particular, language model pretraining loss is known to be highly predictable as a function of compute. However, downstream capabilities are far less predictable -- sometimes even exhibiting emergent jumps -- which makes it challenging to anticipate the capabilities of future models. In this work, we first pose the task of emergence prediction: given access to current LLMs that have random few-shot accuracy on a task, can we predict whether future models (GPT-N+1) will have non-trivial accuracy on that task? We then discover a simple insight for this problem: finetuning LLMs on a given task can shift the point in scaling at which emergence occurs towards less capable models. To operationalize this insight, we can finetune LLMs with varying amounts of data and fit a parametric function that predicts when emergence will occur (i.e., "emergence laws"). We validate this approach using four standard NLP benchmarks where large-scale open-source LLMs already demonstrate emergence (MMLU, GSM8K, CommonsenseQA, and CoLA). Using only small-scale LLMs, we find that, in some cases, we can accurately predict whether models trained with up to 4x more compute have emerged. Finally, we present a case study of two realistic uses for emergence prediction.
Explaining Datasets in Words: Statistical Models with Natural Language Parameters
Sep 13, 2024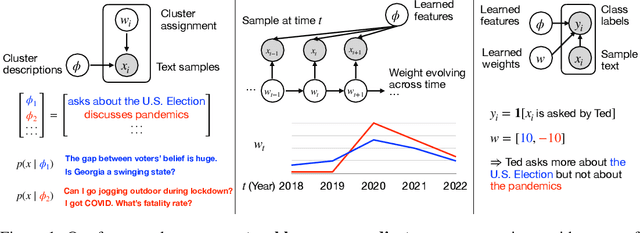


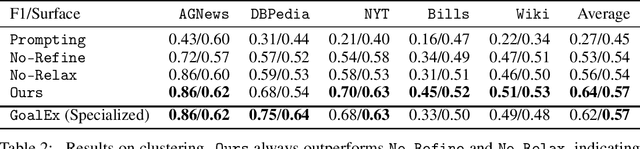
To make sense of massive data, we often fit simplified models and then interpret the parameters; for example, we cluster the text embeddings and then interpret the mean parameters of each cluster. However, these parameters are often high-dimensional and hard to interpret. To make model parameters directly interpretable, we introduce a family of statistical models -- including clustering, time series, and classification models -- parameterized by natural language predicates. For example, a cluster of text about COVID could be parameterized by the predicate "discusses COVID". To learn these statistical models effectively, we develop a model-agnostic algorithm that optimizes continuous relaxations of predicate parameters with gradient descent and discretizes them by prompting language models (LMs). Finally, we apply our framework to a wide range of problems: taxonomizing user chat dialogues, characterizing how they evolve across time, finding categories where one language model is better than the other, clustering math problems based on subareas, and explaining visual features in memorable images. Our framework is highly versatile, applicable to both textual and visual domains, can be easily steered to focus on specific properties (e.g. subareas), and explains sophisticated concepts that classical methods (e.g. n-gram analysis) struggle to produce.
Efficacy of Language Model Self-Play in Non-Zero-Sum Games
Jun 27, 2024Game-playing agents like AlphaGo have achieved superhuman performance through self-play, which is theoretically guaranteed to yield optimal policies in competitive games. However, most language tasks are partially or fully cooperative, so it is an open question whether techniques like self-play can effectively be used to improve language models. We empirically investigate this question in a negotiation game setting known as Deal or No Deal (DoND). Crucially, the objective in DoND can be modified to produce a fully cooperative game, a strictly competitive one, or anything in between. We finetune language models in self-play over multiple rounds of filtered behavior cloning in DoND for each of these objectives. Contrary to expectations, we find that language model self-play leads to significant performance gains in both cooperation and competition with humans, suggesting that self-play and related techniques have promise despite a lack of theoretical guarantees.
Linguistic Bias in ChatGPT: Language Models Reinforce Dialect Discrimination
Jun 13, 2024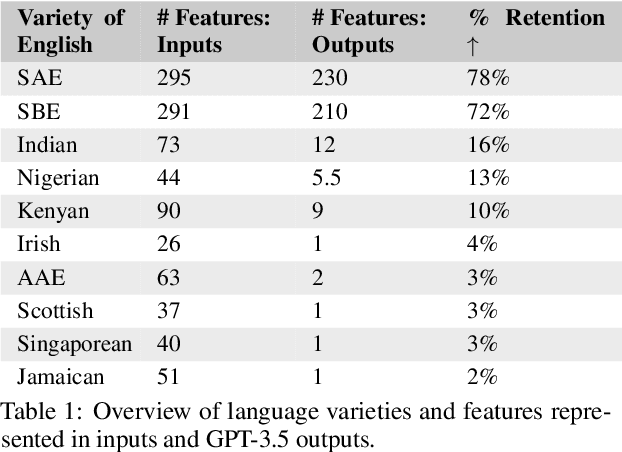
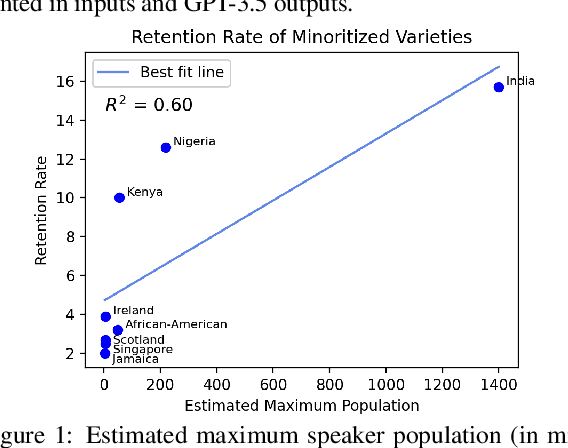
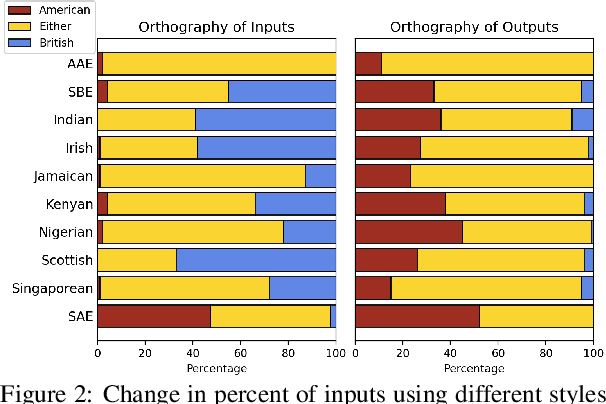
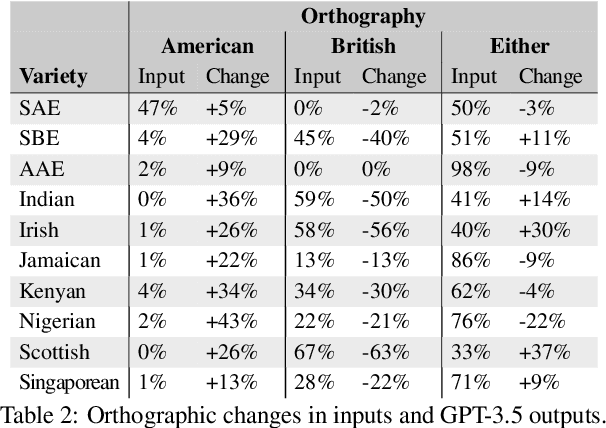
We present a large-scale study of linguistic bias exhibited by ChatGPT covering ten dialects of English (Standard American English, Standard British English, and eight widely spoken non-"standard" varieties from around the world). We prompted GPT-3.5 Turbo and GPT-4 with text by native speakers of each variety and analyzed the responses via detailed linguistic feature annotation and native speaker evaluation. We find that the models default to "standard" varieties of English; based on evaluation by native speakers, we also find that model responses to non-"standard" varieties consistently exhibit a range of issues: lack of comprehension (10% worse compared to "standard" varieties), stereotyping (16% worse), demeaning content (22% worse), and condescending responses (12% worse). We also find that if these models are asked to imitate the writing style of prompts in non-"standard" varieties, they produce text that exhibits lower comprehension of the input and is especially prone to stereotyping. GPT-4 improves on GPT-3.5 in terms of comprehension, warmth, and friendliness, but it also results in a marked increase in stereotyping (+17%). The results suggest that GPT-3.5 Turbo and GPT-4 exhibit linguistic discrimination in ways that can exacerbate harms for speakers of non-"standard" varieties.