 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOfficeQA Pro: An Enterprise Benchmark for End-to-End Grounded Reasoning
Mar 09, 2026We introduce OfficeQA Pro, a benchmark for evaluating AI agents on grounded, multi-document reasoning over a large and heterogeneous document corpus. The corpus consists of U.S. Treasury Bulletins spanning nearly 100 years, comprising 89,000 pages and over 26 million numerical values. OfficeQA Pro consists of 133 questions that require precise document parsing, retrieval, and analytical reasoning across both unstructured text and tabular data. Frontier LLMs including Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro Preview achieve less than 5% accuracy on OfficeQA Pro when relying on parametric knowledge, and less than 12% with additional access to the web. When provided directly with the document corpus, frontier agents still struggle on over half of questions, scoring 34.1% on average. We find that providing agents with a structured document representation produced by Databricks' ai_parse_document yields a 16.1% average relative performance gain across agents. We conduct additional ablations to study the effects of model selection, table representation, retrieval strategy, and test-time scaling on performance. Despite these improvements, significant headroom remains before agents can be considered reliable at enterprise-grade grounded reasoning.
KARL: Knowledge Agents via Reinforcement Learning
Mar 05, 2026We present a system for training enterprise search agents via reinforcement learning that achieves state-of-the-art performance across a diverse suite of hard-to-verify agentic search tasks. Our work makes four core contributions. First, we introduce KARLBench, a multi-capability evaluation suite spanning six distinct search regimes, including constraint-driven entity search, cross-document report synthesis, tabular numerical reasoning, exhaustive entity retrieval, procedural reasoning over technical documentation, and fact aggregation over internal enterprise notes. Second, we show that models trained across heterogeneous search behaviors generalize substantially better than those optimized for any single benchmark. Third, we develop an agentic synthesis pipeline that employs long-horizon reasoning and tool use to generate diverse, grounded, and high-quality training data, with iterative bootstrapping from increasingly capable models. Fourth, we propose a new post-training paradigm based on iterative large-batch off-policy RL that is sample efficient, robust to train-inference engine discrepancies, and naturally extends to multi-task training with out-of-distribution generalization. Compared to Claude 4.6 and GPT 5.2, KARL is Pareto-optimal on KARLBench across cost-quality and latency-quality trade-offs, including tasks that were out-of-distribution during training. With sufficient test-time compute, it surpasses the strongest closed models. These results show that tailored synthetic data in combination with multi-task reinforcement learning enables cost-efficient and high-performing knowledge agents for grounded reasoning.
Prompt Triage: Structured Optimization Enhances Vision-Language Model Performance on Medical Imaging Benchmarks
Nov 14, 2025Vision-language foundation models (VLMs) show promise for diverse imaging tasks but often underperform on medical benchmarks. Prior efforts to improve performance include model finetuning, which requires large domain-specific datasets and significant compute, or manual prompt engineering, which is hard to generalize and often inaccessible to medical institutions seeking to deploy these tools. These challenges motivate interest in approaches that draw on a model's embedded knowledge while abstracting away dependence on human-designed prompts to enable scalable, weight-agnostic performance improvements. To explore this, we adapt the Declarative Self-improving Python (DSPy) framework for structured automated prompt optimization in medical vision-language systems through a comprehensive, formal evaluation. We implement prompting pipelines for five medical imaging tasks across radiology, gastroenterology, and dermatology, evaluating 10 open-source VLMs with four prompt optimization techniques. Optimized pipelines achieved a median relative improvement of 53% over zero-shot prompting baselines, with the largest gains ranging from 300% to 3,400% on tasks where zero-shot performance is low. These results highlight the substantial potential of applying automated prompt optimization to medical AI systems, demonstrating significant gains for vision-based applications requiring accurate clinical image interpretation. By reducing dependence on prompt design to elicit intended outputs, these techniques allow clinicians to focus on patient care and clinical decision-making. Furthermore, our experiments offer scalability and preserve data privacy, demonstrating performance improvement on open-source VLMs. We publicly release our evaluation pipelines to support reproducible research on specialized medical tasks, available at https://github.com/DaneshjouLab/prompt-triage-lab.
LangProBe: a Language Programs Benchmark
Feb 27, 2025
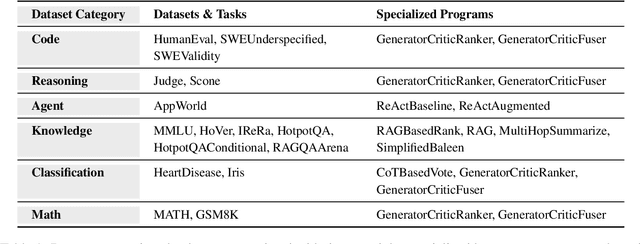
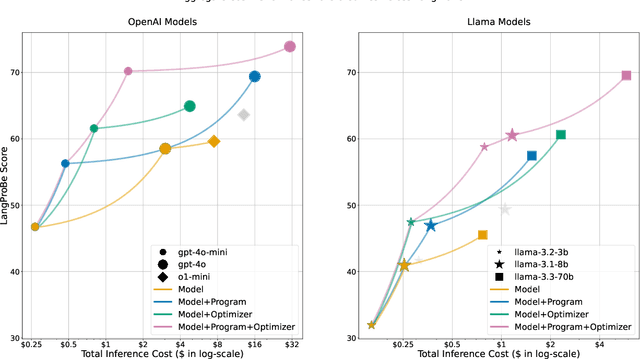
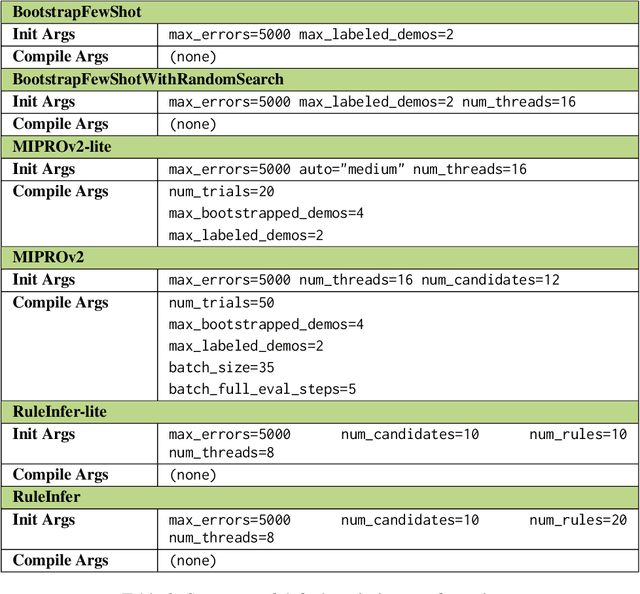
Composing language models (LMs) into multi-step language programs and automatically optimizing their modular prompts is now a mainstream paradigm for building AI systems, but the tradeoffs in this space have only scarcely been studied before. We introduce LangProBe, the first large-scale benchmark for evaluating the architectures and optimization strategies for language programs, with over 2000 combinations of tasks, architectures, optimizers, and choices of LMs. Using LangProBe, we are the first to study the impact of program architectures and optimizers (and their compositions together and with different models) on tradeoffs of quality and cost. We find that optimized language programs offer strong cost--quality Pareto improvement over raw calls to models, but simultaneously demonstrate that human judgment (or empirical decisions) about which compositions to pursue is still necessary for best performance. We will open source the code and evaluation data for LangProBe.
DSPy Assertions: Computational Constraints for Self-Refining Language Model Pipelines
Dec 20, 2023Chaining language model (LM) calls as composable modules is fueling a new powerful way of programming. However, ensuring that LMs adhere to important constraints remains a key challenge, one often addressed with heuristic "prompt engineering". We introduce LM Assertions, a new programming construct for expressing computational constraints that LMs should satisfy. We integrate our constructs into the recent DSPy programming model for LMs, and present new strategies that allow DSPy to compile programs with arbitrary LM Assertions into systems that are more reliable and more accurate. In DSPy, LM Assertions can be integrated at compile time, via automatic prompt optimization, and/or at inference time, via automatic selfrefinement and backtracking. We report on two early case studies for complex question answering (QA), in which the LM program must iteratively retrieve information in multiple hops and synthesize a long-form answer with citations. We find that LM Assertions improve not only compliance with imposed rules and guidelines but also enhance downstream task performance, delivering intrinsic and extrinsic gains up to 35.7% and 13.3%, respectively. Our reference implementation of LM Assertions is integrated into DSPy at https://github.com/stanfordnlp/dspy
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Oct 05, 2023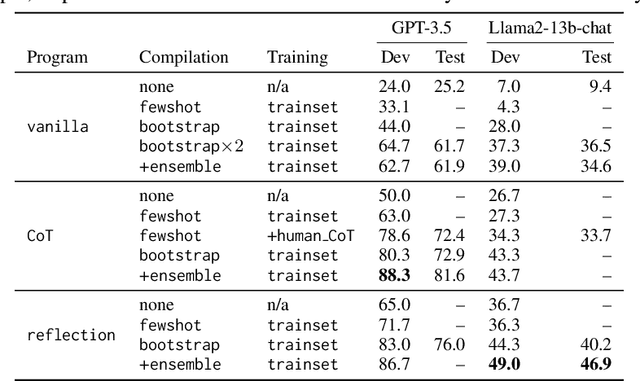

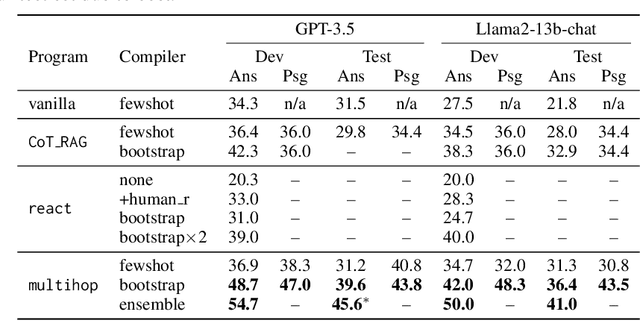

The ML community is rapidly exploring techniques for prompting language models (LMs) and for stacking them into pipelines that solve complex tasks. Unfortunately, existing LM pipelines are typically implemented using hard-coded "prompt templates", i.e. lengthy strings discovered via trial and error. Toward a more systematic approach for developing and optimizing LM pipelines, we introduce DSPy, a programming model that abstracts LM pipelines as text transformation graphs, i.e. imperative computational graphs where LMs are invoked through declarative modules. DSPy modules are parameterized, meaning they can learn (by creating and collecting demonstrations) how to apply compositions of prompting, finetuning, augmentation, and reasoning techniques. We design a compiler that will optimize any DSPy pipeline to maximize a given metric. We conduct two case studies, showing that succinct DSPy programs can express and optimize sophisticated LM pipelines that reason about math word problems, tackle multi-hop retrieval, answer complex questions, and control agent loops. Within minutes of compiling, a few lines of DSPy allow GPT-3.5 and llama2-13b-chat to self-bootstrap pipelines that outperform standard few-shot prompting (generally by over 25% and 65%, respectively) and pipelines with expert-created demonstrations (by up to 5-46% and 16-40%, respectively). On top of that, DSPy programs compiled to open and relatively small LMs like 770M-parameter T5 and llama2-13b-chat are competitive with approaches that rely on expert-written prompt chains for proprietary GPT-3.5. DSPy is available at https://github.com/stanfordnlp/dspy