 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTractRLFusion: A GPT-Based Multi-Critic Policy Fusion Framework for Fiber Tractography
Jan 20, 2026Tractography plays a pivotal role in the non-invasive reconstruction of white matter fiber pathways, providing vital information on brain connectivity and supporting precise neurosurgical planning. Although traditional methods relied mainly on classical deterministic and probabilistic approaches, recent progress has benefited from supervised deep learning (DL) and deep reinforcement learning (DRL) to improve tract reconstruction. A persistent challenge in tractography is accurately reconstructing white matter tracts while minimizing spurious connections. To address this, we propose TractRLFusion, a novel GPT-based policy fusion framework that integrates multiple RL policies through a data-driven fusion strategy. Our method employs a two-stage training data selection process for effective policy fusion, followed by a multi-critic fine-tuning phase to enhance robustness and generalization. Experiments on HCP, ISMRM, and TractoInferno datasets demonstrate that TractRLFusion outperforms individual RL policies as well as state-of-the-art classical and DRL methods in accuracy and anatomical reliability.
Tract-RLFormer: A Tract-Specific RL policy based Decoder-only Transformer Network
Nov 08, 2024Fiber tractography is a cornerstone of neuroimaging, enabling the detailed mapping of the brain's white matter pathways through diffusion MRI. This is crucial for understanding brain connectivity and function, making it a valuable tool in neurological applications. Despite its importance, tractography faces challenges due to its complexity and susceptibility to false positives, misrepresenting vital pathways. To address these issues, recent strategies have shifted towards deep learning, utilizing supervised learning, which depends on precise ground truth, or reinforcement learning, which operates without it. In this work, we propose Tract-RLFormer, a network utilizing both supervised and reinforcement learning, in a two-stage policy refinement process that markedly improves the accuracy and generalizability across various data-sets. By employing a tract-specific approach, our network directly delineates the tracts of interest, bypassing the traditional segmentation process. Through rigorous validation on datasets such as TractoInferno, HCP, and ISMRM-2015, our methodology demonstrates a leap forward in tractography, showcasing its ability to accurately map the brain's white matter tracts.
IndicIRSuite: Multilingual Dataset and Neural Information Models for Indian Languages
Dec 15, 2023
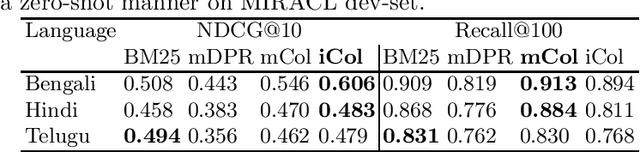
In this paper, we introduce Neural Information Retrieval resources for 11 widely spoken Indian Languages (Assamese, Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Oriya, Punjabi, Tamil, and Telugu) from two major Indian language families (Indo-Aryan and Dravidian). These resources include (a) INDIC-MARCO, a multilingual version of the MSMARCO dataset in 11 Indian Languages created using Machine Translation, and (b) Indic-ColBERT, a collection of 11 distinct Monolingual Neural Information Retrieval models, each trained on one of the 11 languages in the INDIC-MARCO dataset. To the best of our knowledge, IndicIRSuite is the first attempt at building large-scale Neural Information Retrieval resources for a large number of Indian languages, and we hope that it will help accelerate research in Neural IR for Indian Languages. Experiments demonstrate that Indic-ColBERT achieves 47.47% improvement in the MRR@10 score averaged over the INDIC-MARCO baselines for all 11 Indian languages except Oriya, 12.26% improvement in the NDCG@10 score averaged over the MIRACL Bengali and Hindi Language baselines, and 20% improvement in the MRR@100 Score over the Mr.Tydi Bengali Language baseline. IndicIRSuite is available at https://github.com/saifulhaq95/IndicIRSuite
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Oct 05, 2023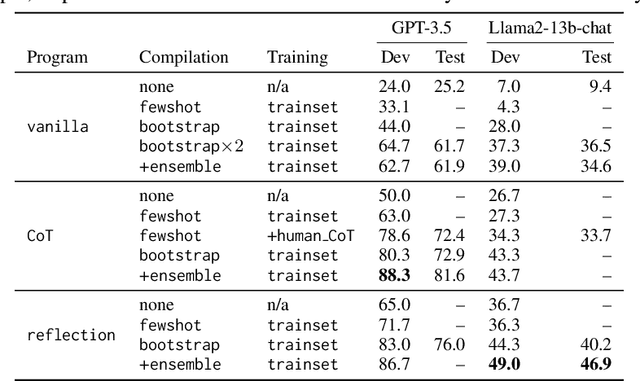

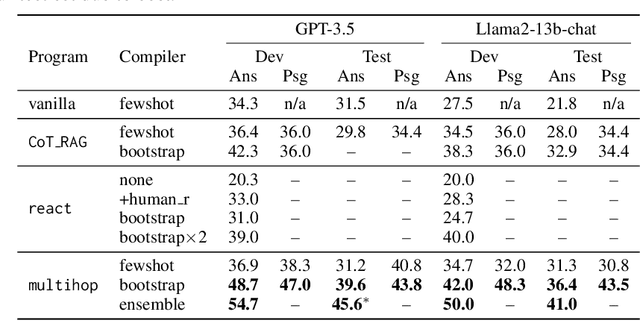

The ML community is rapidly exploring techniques for prompting language models (LMs) and for stacking them into pipelines that solve complex tasks. Unfortunately, existing LM pipelines are typically implemented using hard-coded "prompt templates", i.e. lengthy strings discovered via trial and error. Toward a more systematic approach for developing and optimizing LM pipelines, we introduce DSPy, a programming model that abstracts LM pipelines as text transformation graphs, i.e. imperative computational graphs where LMs are invoked through declarative modules. DSPy modules are parameterized, meaning they can learn (by creating and collecting demonstrations) how to apply compositions of prompting, finetuning, augmentation, and reasoning techniques. We design a compiler that will optimize any DSPy pipeline to maximize a given metric. We conduct two case studies, showing that succinct DSPy programs can express and optimize sophisticated LM pipelines that reason about math word problems, tackle multi-hop retrieval, answer complex questions, and control agent loops. Within minutes of compiling, a few lines of DSPy allow GPT-3.5 and llama2-13b-chat to self-bootstrap pipelines that outperform standard few-shot prompting (generally by over 25% and 65%, respectively) and pipelines with expert-created demonstrations (by up to 5-46% and 16-40%, respectively). On top of that, DSPy programs compiled to open and relatively small LMs like 770M-parameter T5 and llama2-13b-chat are competitive with approaches that rely on expert-written prompt chains for proprietary GPT-3.5. DSPy is available at https://github.com/stanfordnlp/dspy
Transforming Breast Cancer Diagnosis: Towards Real-Time Ultrasound to Mammogram Conversion for Cost-Effective Diagnosis
Aug 10, 2023
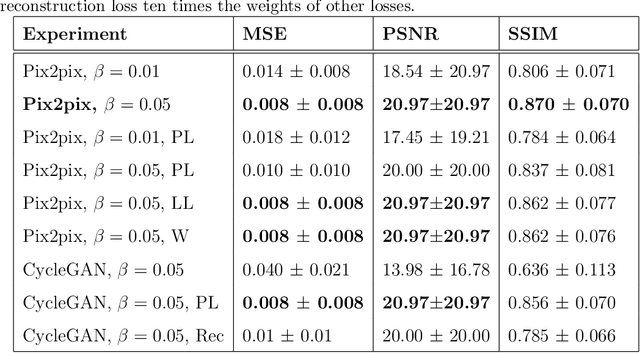

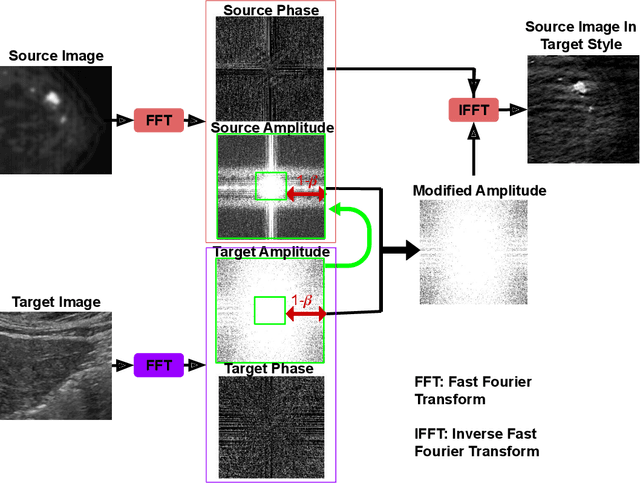
Ultrasound (US) imaging is better suited for intraoperative settings because it is real-time and more portable than other imaging techniques, such as mammography. However, US images are characterized by lower spatial resolution noise-like artifacts. This research aims to address these limitations by providing surgeons with mammogram-like image quality in real-time from noisy US images. Unlike previous approaches for improving US image quality that aim to reduce artifacts by treating them as (speckle noise), we recognize their value as informative wave interference pattern (WIP). To achieve this, we utilize the Stride software to numerically solve the forward model, generating ultrasound images from mammograms images by solving wave-equations. Additionally, we leverage the power of domain adaptation to enhance the realism of the simulated ultrasound images. Then, we utilize generative adversarial networks (GANs) to tackle the inverse problem of generating mammogram-quality images from ultrasound images. The resultant images have considerably more discernible details than the original US images.