 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeGraphs: Graph-based Temporal Reasoning
Jan 06, 2024Many real-world systems exhibit temporal, dynamic behaviors, which are captured as time series of complex agent interactions. To perform temporal reasoning, current methods primarily encode temporal dynamics through simple sequence-based models. However, in general these models fail to efficiently capture the full spectrum of rich dynamics in the input, since the dynamics is not uniformly distributed. In particular, relevant information might be harder to extract and computing power is wasted for processing all individual timesteps, even if they contain no significant changes or no new information. Here we propose TimeGraphs, a novel approach that characterizes dynamic interactions as a hierarchical temporal graph, diverging from traditional sequential representations. Our approach models the interactions using a compact graph-based representation, enabling adaptive reasoning across diverse time scales. Adopting a self-supervised method, TimeGraphs constructs a multi-level event hierarchy from a temporal input, which is then used to efficiently reason about the unevenly distributed dynamics. This construction process is scalable and incremental to accommodate streaming data. We evaluate TimeGraphs on multiple datasets with complex, dynamic agent interactions, including a football simulator, the Resistance game, and the MOMA human activity dataset. The results demonstrate both robustness and efficiency of TimeGraphs on a range of temporal reasoning tasks. Our approach obtains state-of-the-art performance and leads to a performance increase of up to 12.2% on event prediction and recognition tasks over current approaches. Our experiments further demonstrate a wide array of capabilities including zero-shot generalization, robustness in case of data sparsity, and adaptability to streaming data flow.
Learning to Infer Unobserved Behaviors: Estimating User's Preference for a Site over Other Sites
Dec 15, 2023A site's recommendation system relies on knowledge of its users' preferences to offer relevant recommendations to them. These preferences are for attributes that comprise items and content shown on the site, and are estimated from the data of users' interactions with the site. Another form of users' preferences is material too, namely, users' preferences for the site over other sites, since that shows users' base level propensities to engage with the site. Estimating users' preferences for the site, however, faces major obstacles because (a) the focal site usually has no data of its users' interactions with other sites; these interactions are users' unobserved behaviors for the focal site; and (b) the Machine Learning literature in recommendation does not offer a model of this situation. Even if (b) is resolved, the problem in (a) persists since without access to data of its users' interactions with other sites, there is no ground truth for evaluation. Moreover, it is most useful when (c) users' preferences for the site can be estimated at the individual level, since the site can then personalize recommendations to individual users. We offer a method to estimate individual user's preference for a focal site, under this premise. In particular, we compute the focal site's share of a user's online engagements without any data from other sites. We show an evaluation framework for the model using only the focal site's data, allowing the site to test the model. We rely upon a Hierarchical Bayes Method and perform estimation in two different ways - Markov Chain Monte Carlo and Stochastic Gradient with Langevin Dynamics. Our results find good support for the approach to computing personalized share of engagement and for its evaluation.
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Oct 05, 2023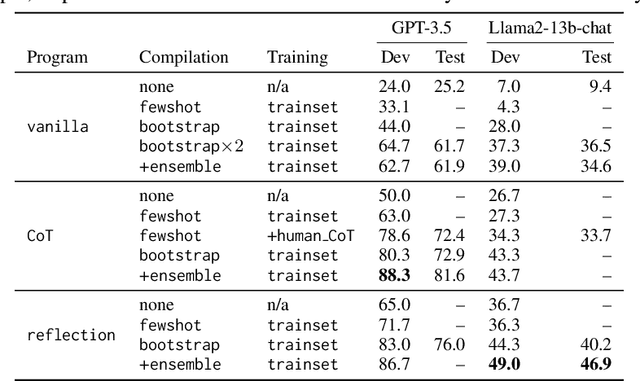

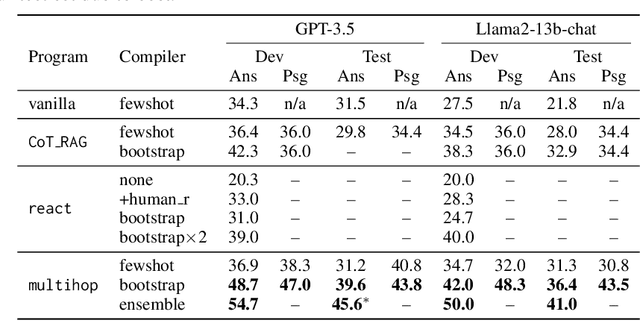

The ML community is rapidly exploring techniques for prompting language models (LMs) and for stacking them into pipelines that solve complex tasks. Unfortunately, existing LM pipelines are typically implemented using hard-coded "prompt templates", i.e. lengthy strings discovered via trial and error. Toward a more systematic approach for developing and optimizing LM pipelines, we introduce DSPy, a programming model that abstracts LM pipelines as text transformation graphs, i.e. imperative computational graphs where LMs are invoked through declarative modules. DSPy modules are parameterized, meaning they can learn (by creating and collecting demonstrations) how to apply compositions of prompting, finetuning, augmentation, and reasoning techniques. We design a compiler that will optimize any DSPy pipeline to maximize a given metric. We conduct two case studies, showing that succinct DSPy programs can express and optimize sophisticated LM pipelines that reason about math word problems, tackle multi-hop retrieval, answer complex questions, and control agent loops. Within minutes of compiling, a few lines of DSPy allow GPT-3.5 and llama2-13b-chat to self-bootstrap pipelines that outperform standard few-shot prompting (generally by over 25% and 65%, respectively) and pipelines with expert-created demonstrations (by up to 5-46% and 16-40%, respectively). On top of that, DSPy programs compiled to open and relatively small LMs like 770M-parameter T5 and llama2-13b-chat are competitive with approaches that rely on expert-written prompt chains for proprietary GPT-3.5. DSPy is available at https://github.com/stanfordnlp/dspy
Self-supervised Multi-view Disentanglement for Expansion of Visual Collections
Feb 04, 2023

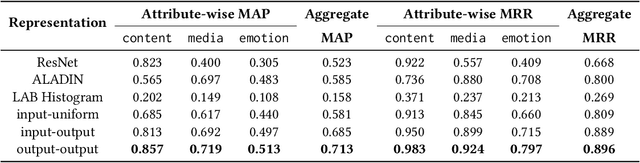
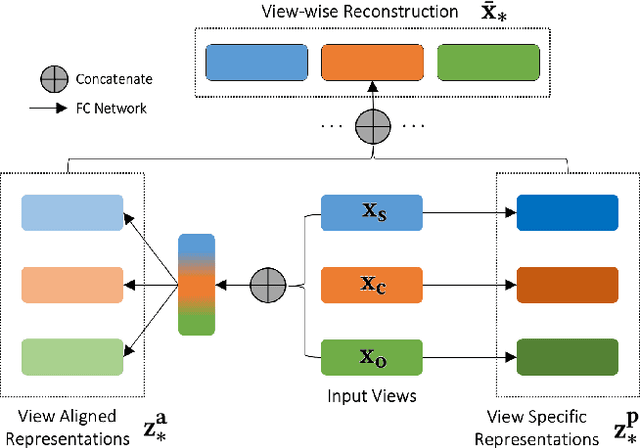
Image search engines enable the retrieval of images relevant to a query image. In this work, we consider the setting where a query for similar images is derived from a collection of images. For visual search, the similarity measurements may be made along multiple axes, or views, such as style and color. We assume access to a set of feature extractors, each of which computes representations for a specific view. Our objective is to design a retrieval algorithm that effectively combines similarities computed over representations from multiple views. To this end, we propose a self-supervised learning method for extracting disentangled view-specific representations for images such that the inter-view overlap is minimized. We show how this allows us to compute the intent of a collection as a distribution over views. We show how effective retrieval can be performed by prioritizing candidate expansion images that match the intent of a query collection. Finally, we present a new querying mechanism for image search enabled by composing multiple collections and perform retrieval under this setting using the techniques presented in this paper.
Generating Compositional Color Representations from Text
Sep 22, 2021
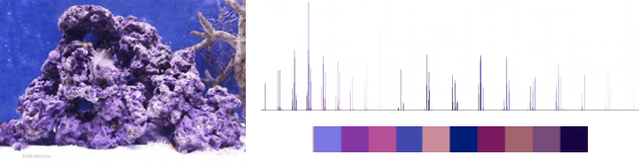
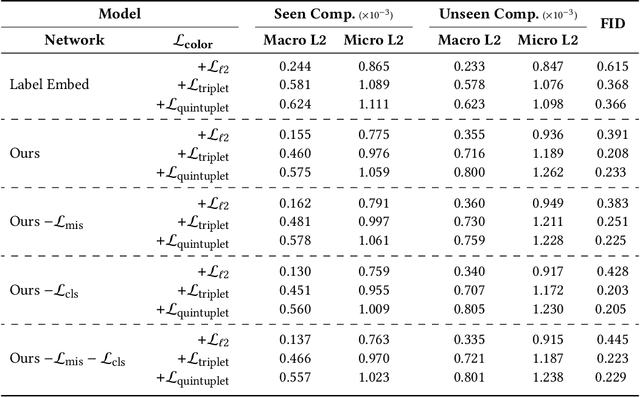

We consider the cross-modal task of producing color representations for text phrases. Motivated by the fact that a significant fraction of user queries on an image search engine follow an (attribute, object) structure, we propose a generative adversarial network that generates color profiles for such bigrams. We design our pipeline to learn composition - the ability to combine seen attributes and objects to unseen pairs. We propose a novel dataset curation pipeline from existing public sources. We describe how a set of phrases of interest can be compiled using a graph propagation technique, and then mapped to images. While this dataset is specialized for our investigations on color, the method can be extended to other visual dimensions where composition is of interest. We provide detailed ablation studies that test the behavior of our GAN architecture with loss functions from the contrastive learning literature. We show that the generative model achieves lower Frechet Inception Distance than discriminative ones, and therefore predicts color profiles that better match those from real images. Finally, we demonstrate improved performance in image retrieval and classification, indicating the crucial role that color plays in these downstream tasks.
Scene Graph Embeddings Using Relative Similarity Supervision
Apr 06, 2021
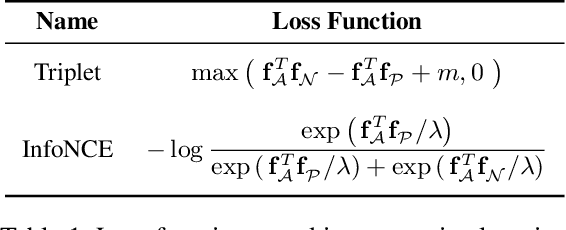
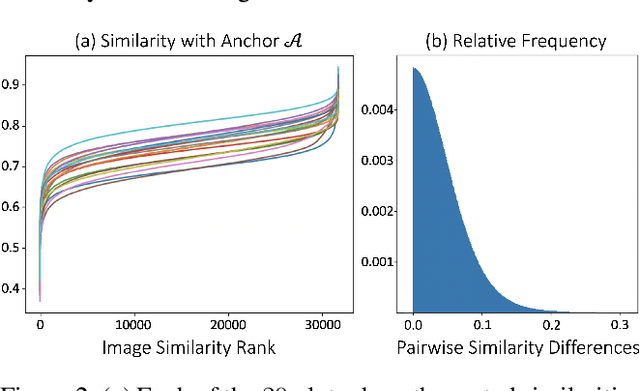
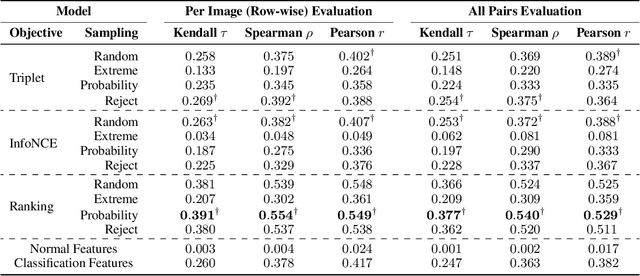
Scene graphs are a powerful structured representation of the underlying content of images, and embeddings derived from them have been shown to be useful in multiple downstream tasks. In this work, we employ a graph convolutional network to exploit structure in scene graphs and produce image embeddings useful for semantic image retrieval. Different from classification-centric supervision traditionally available for learning image representations, we address the task of learning from relative similarity labels in a ranking context. Rooted within the contrastive learning paradigm, we propose a novel loss function that operates on pairs of similar and dissimilar images and imposes relative ordering between them in embedding space. We demonstrate that this Ranking loss, coupled with an intuitive triple sampling strategy, leads to robust representations that outperform well-known contrastive losses on the retrieval task. In addition, we provide qualitative evidence of how retrieved results that utilize structured scene information capture the global context of the scene, different from visual similarity search.
Learning Colour Representations of Search Queries
Jun 17, 2020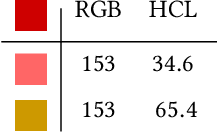
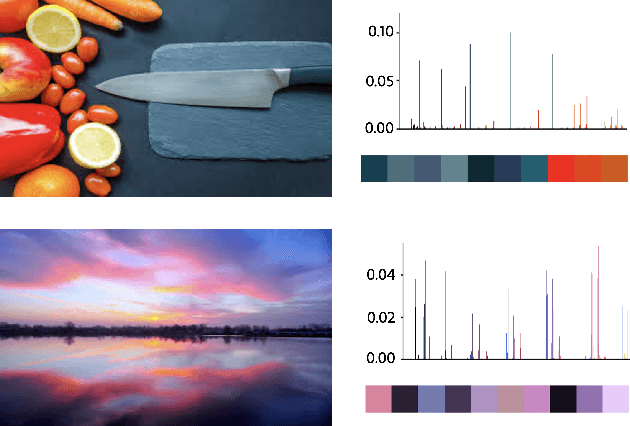

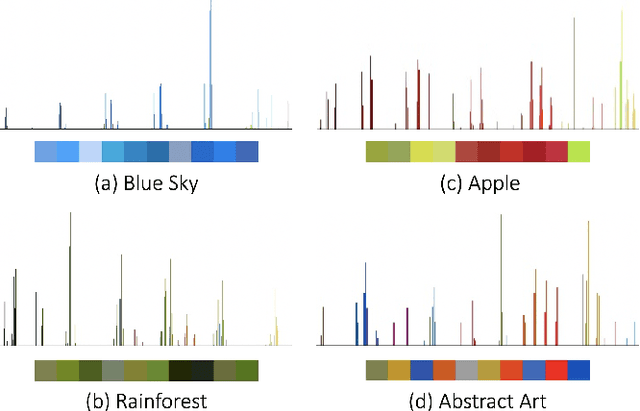
Image search engines rely on appropriately designed ranking features that capture various aspects of the content semantics as well as the historic popularity. In this work, we consider the role of colour in this relevance matching process. Our work is motivated by the observation that a significant fraction of user queries have an inherent colour associated with them. While some queries contain explicit colour mentions (such as 'black car' and 'yellow daisies'), other queries have implicit notions of colour (such as 'sky' and 'grass'). Furthermore, grounding queries in colour is not a mapping to a single colour, but a distribution in colour space. For instance, a search for 'trees' tends to have a bimodal distribution around the colours green and brown. We leverage historical clickthrough data to produce a colour representation for search queries and propose a recurrent neural network architecture to encode unseen queries into colour space. We also show how this embedding can be learnt alongside a cross-modal relevance ranker from impression logs where a subset of the result images were clicked. We demonstrate that the use of a query-image colour distance feature leads to an improvement in the ranker performance as measured by users' preferences of clicked versus skipped images.