 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Graph Embeddings Using Relative Similarity Supervision
Paper and Code
Apr 06, 2021
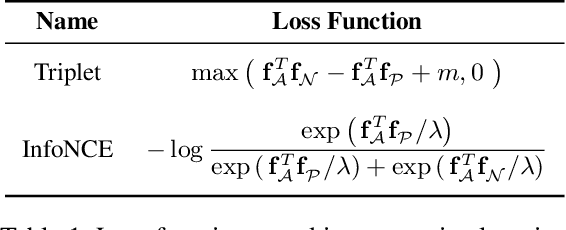
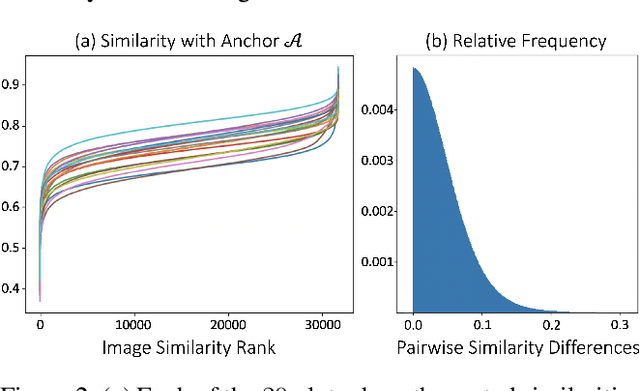
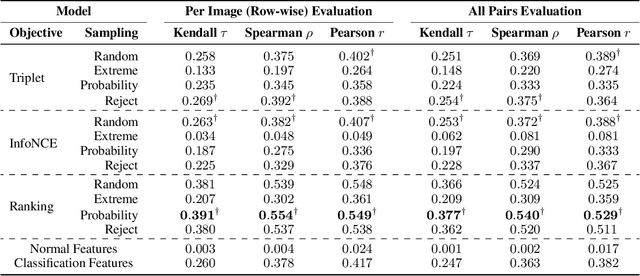
Scene graphs are a powerful structured representation of the underlying content of images, and embeddings derived from them have been shown to be useful in multiple downstream tasks. In this work, we employ a graph convolutional network to exploit structure in scene graphs and produce image embeddings useful for semantic image retrieval. Different from classification-centric supervision traditionally available for learning image representations, we address the task of learning from relative similarity labels in a ranking context. Rooted within the contrastive learning paradigm, we propose a novel loss function that operates on pairs of similar and dissimilar images and imposes relative ordering between them in embedding space. We demonstrate that this Ranking loss, coupled with an intuitive triple sampling strategy, leads to robust representations that outperform well-known contrastive losses on the retrieval task. In addition, we provide qualitative evidence of how retrieved results that utilize structured scene information capture the global context of the scene, different from visual similarity search.