 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrack, Check, Repeat: An EM Approach to Unsupervised Tracking
Apr 07, 2021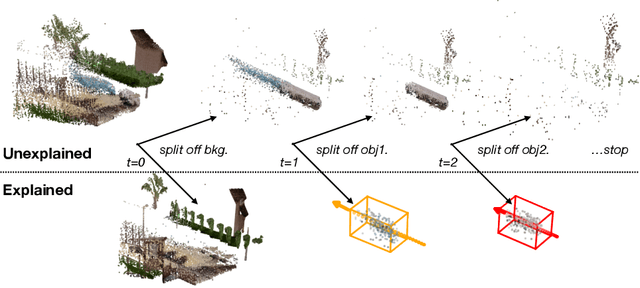
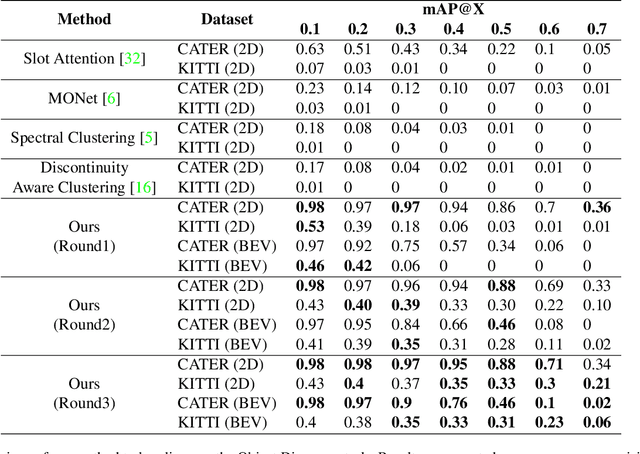


We propose an unsupervised method for detecting and tracking moving objects in 3D, in unlabelled RGB-D videos. The method begins with classic handcrafted techniques for segmenting objects using motion cues: we estimate optical flow and camera motion, and conservatively segment regions that appear to be moving independently of the background. Treating these initial segments as pseudo-labels, we learn an ensemble of appearance-based 2D and 3D detectors, under heavy data augmentation. We use this ensemble to detect new instances of the "moving" type, even if they are not moving, and add these as new pseudo-labels. Our method is an expectation-maximization algorithm, where in the expectation step we fire all modules and look for agreement among them, and in the maximization step we re-train the modules to improve this agreement. The constraint of ensemble agreement helps combat contamination of the generated pseudo-labels (during the E step), and data augmentation helps the modules generalize to yet-unlabelled data (during the M step). We compare against existing unsupervised object discovery and tracking methods, using challenging videos from CATER and KITTI, and show strong improvements over the state-of-the-art.
Scene Graph Embeddings Using Relative Similarity Supervision
Apr 06, 2021
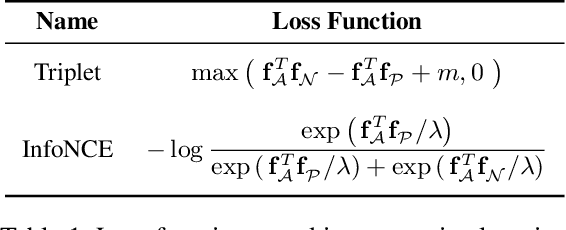
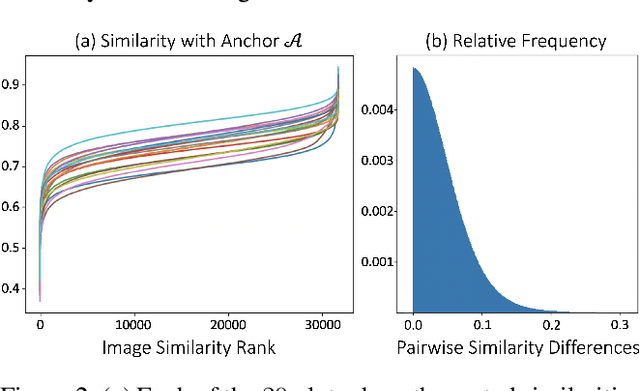
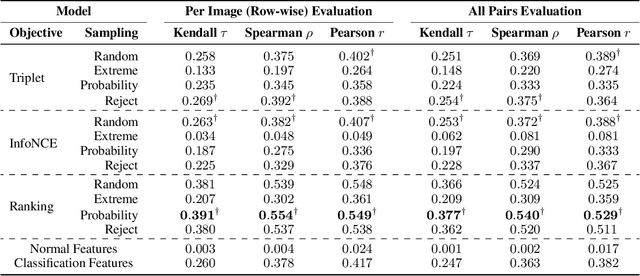
Scene graphs are a powerful structured representation of the underlying content of images, and embeddings derived from them have been shown to be useful in multiple downstream tasks. In this work, we employ a graph convolutional network to exploit structure in scene graphs and produce image embeddings useful for semantic image retrieval. Different from classification-centric supervision traditionally available for learning image representations, we address the task of learning from relative similarity labels in a ranking context. Rooted within the contrastive learning paradigm, we propose a novel loss function that operates on pairs of similar and dissimilar images and imposes relative ordering between them in embedding space. We demonstrate that this Ranking loss, coupled with an intuitive triple sampling strategy, leads to robust representations that outperform well-known contrastive losses on the retrieval task. In addition, we provide qualitative evidence of how retrieved results that utilize structured scene information capture the global context of the scene, different from visual similarity search.
LEAF-QA: Locate, Encode & Attend for Figure Question Answering
Jul 30, 2019
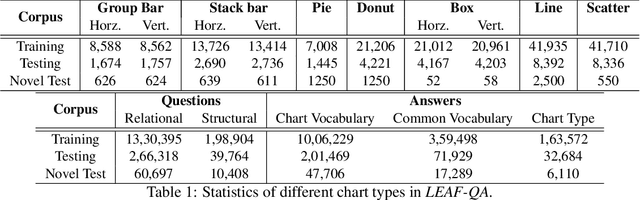
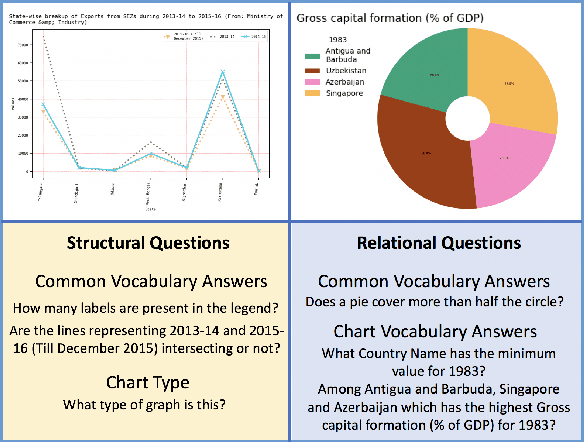
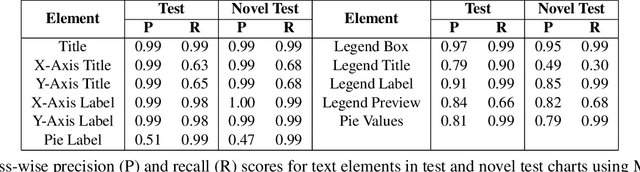
We introduce LEAF-QA, a comprehensive dataset of $250,000$ densely annotated figures/charts, constructed from real-world open data sources, along with ~2 million question-answer (QA) pairs querying the structure and semantics of these charts. LEAF-QA highlights the problem of multimodal QA, which is notably different from conventional visual QA (VQA), and has recently gained interest in the community. Furthermore, LEAF-QA is significantly more complex than previous attempts at chart QA, viz. FigureQA and DVQA, which present only limited variations in chart data. LEAF-QA being constructed from real-world sources, requires a novel architecture to enable question answering. To this end, LEAF-Net, a deep architecture involving chart element localization, question and answer encoding in terms of chart elements, and an attention network is proposed. Different experiments are conducted to demonstrate the challenges of QA on LEAF-QA. The proposed architecture, LEAF-Net also considerably advances the current state-of-the-art on FigureQA and DVQA.
Tomographic Reconstruction using Global Statistical Prior
Dec 06, 2017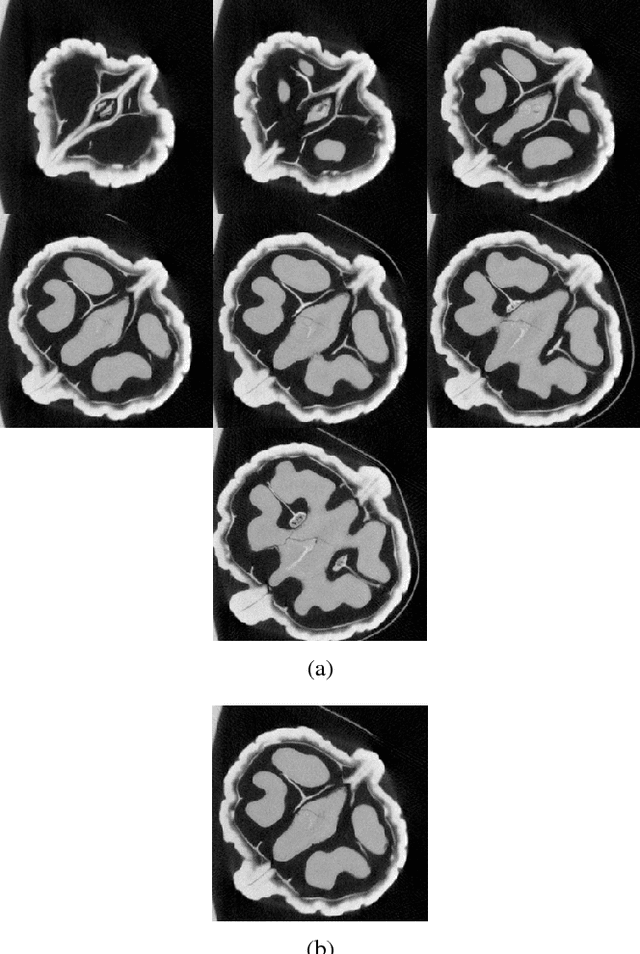



Recent research in tomographic reconstruction is motivated by the need to efficiently recover detailed anatomy from limited measurements. One of the ways to compensate for the increasingly sparse sets of measurements is to exploit the information from templates, i.e., prior data available in the form of already reconstructed, structurally similar images. Towards this, previous work has exploited using a set of global and patch based dictionary priors. In this paper, we propose a global prior to improve both the speed and quality of tomographic reconstruction within a Compressive Sensing framework. We choose a set of potential representative 2D images referred to as templates, to build an eigenspace; this is subsequently used to guide the iterative reconstruction of a similar slice from sparse acquisition data. Our experiments across a diverse range of datasets show that reconstruction using an appropriate global prior, apart from being faster, gives a much lower reconstruction error when compared to the state of the art.