 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPAR: Dynamic Patchification for Efficient Autoregressive Visual Generation
Dec 26, 2025Decoder-only autoregressive image generation typically relies on fixed-length tokenization schemes whose token counts grow quadratically with resolution, substantially increasing the computational and memory demands of attention. We present DPAR, a novel decoder-only autoregressive model that dynamically aggregates image tokens into a variable number of patches for efficient image generation. Our work is the first to demonstrate that next-token prediction entropy from a lightweight and unsupervised autoregressive model provides a reliable criterion for merging tokens into larger patches based on information content. DPAR makes minimal modifications to the standard decoder architecture, ensuring compatibility with multimodal generation frameworks and allocating more compute to generation of high-information image regions. Further, we demonstrate that training with dynamically sized patches yields representations that are robust to patch boundaries, allowing DPAR to scale to larger patch sizes at inference. DPAR reduces token count by 1.81x and 2.06x on Imagenet 256 and 384 generation resolution respectively, leading to a reduction of up to 40% FLOPs in training costs. Further, our method exhibits faster convergence and improves FID by up to 27.1% relative to baseline models.
A Generic Framework for Conformal Fairness
May 22, 2025



Conformal Prediction (CP) is a popular method for uncertainty quantification with machine learning models. While conformal prediction provides probabilistic guarantees regarding the coverage of the true label, these guarantees are agnostic to the presence of sensitive attributes within the dataset. In this work, we formalize \textit{Conformal Fairness}, a notion of fairness using conformal predictors, and provide a theoretically well-founded algorithm and associated framework to control for the gaps in coverage between different sensitive groups. Our framework leverages the exchangeability assumption (implicit to CP) rather than the typical IID assumption, allowing us to apply the notion of Conformal Fairness to data types and tasks that are not IID, such as graph data. Experiments were conducted on graph and tabular datasets to demonstrate that the algorithm can control fairness-related gaps in addition to coverage aligned with theoretical expectations.
Graph Sparsification for Enhanced Conformal Prediction in Graph Neural Networks
Oct 28, 2024Conformal Prediction is a robust framework that ensures reliable coverage across machine learning tasks. Although recent studies have applied conformal prediction to graph neural networks, they have largely emphasized post-hoc prediction set generation. Improving conformal prediction during the training stage remains unaddressed. In this work, we tackle this challenge from a denoising perspective by introducing SparGCP, which incorporates graph sparsification and a conformal prediction-specific objective into GNN training. SparGCP employs a parameterized graph sparsification module to filter out task-irrelevant edges, thereby improving conformal prediction efficiency. Extensive experiments on real-world graph datasets demonstrate that SparGCP outperforms existing methods, reducing prediction set sizes by an average of 32\% and scaling seamlessly to large networks on commodity GPUs.
Benchmarking Graph Conformal Prediction: Empirical Analysis, Scalability, and Theoretical Insights
Sep 26, 2024Conformal prediction has become increasingly popular for quantifying the uncertainty associated with machine learning models. Recent work in graph uncertainty quantification has built upon this approach for conformal graph prediction. The nascent nature of these explorations has led to conflicting choices for implementations, baselines, and method evaluation. In this work, we analyze the design choices made in the literature and discuss the tradeoffs associated with existing methods. Building on the existing implementations for existing methods, we introduce techniques to scale existing methods to large-scale graph datasets without sacrificing performance. Our theoretical and empirical results justify our recommendations for future scholarship in graph conformal prediction.
StyleML: Stylometry with Structure and Multitask Learning for Darkweb Markets
Apr 01, 2021
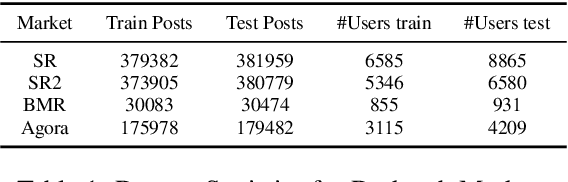
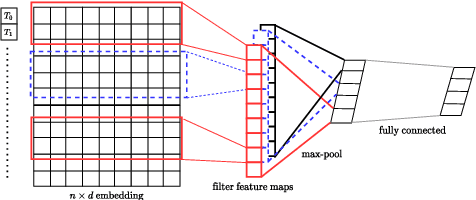

Darknet market forums are frequently used to exchange illegal goods and services between parties who use encryption to conceal their identities. The Tor network is used to host these markets, which guarantees additional anonymization from IP and location tracking, making it challenging to link across malicious users using multiple accounts (sybils). Additionally, users migrate to new forums when one is closed, making it difficult to link users across multiple forums. We develop a novel stylometry-based multitask learning approach for natural language and interaction modeling using graph embeddings to construct low-dimensional representations of short episodes of user activity for authorship attribution. We provide a comprehensive evaluation of our methods across four different darknet forums demonstrating its efficacy over the state-of-the-art, with a lift of up to 2.5X on Mean Retrieval Rank and 2X on Recall@10.
Understanding Knowledge Gaps in Visual Question Answering: Implications for Gap Identification and Testing
Apr 08, 2020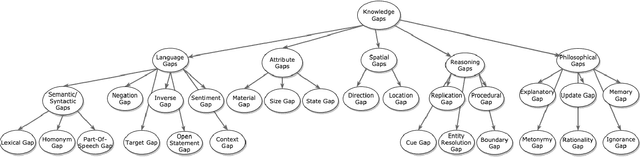
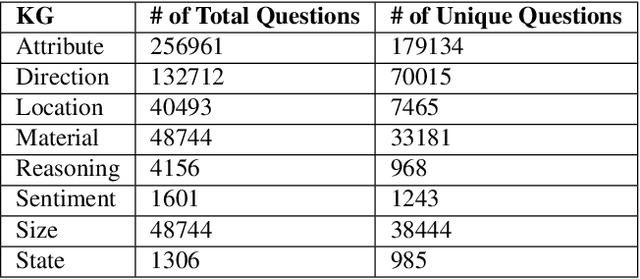

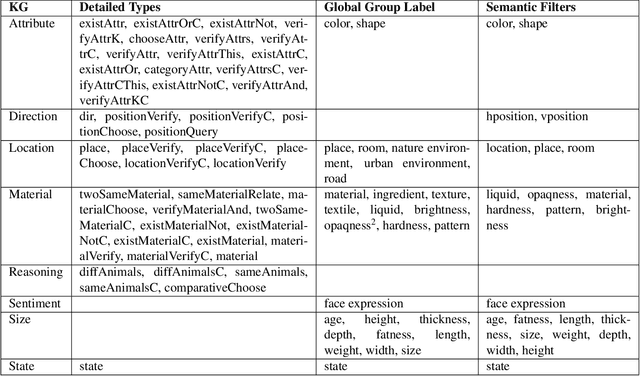
Visual Question Answering (VQA) systems are tasked with answering natural language questions corresponding to a presented image. Current VQA datasets typically contain questions related to the spatial information of objects, object attributes, or general scene questions. Recently, researchers have recognized the need for improving the balance of such datasets to reduce the system's dependency on memorized linguistic features and statistical biases and to allow for improved visual understanding. However, it is unclear as to whether there are any latent patterns that can be used to quantify and explain these failures. To better quantify our understanding of the performance of VQA models, we use a taxonomy of Knowledge Gaps (KGs) to identify/tag questions with one or more types of KGs. Each KG describes the reasoning abilities needed to arrive at a resolution, and failure to resolve gaps indicate an absence of the required reasoning ability. After identifying KGs for each question, we examine the skew in the distribution of the number of questions for each KG. In order to reduce the skew in the distribution of questions across KGs, we introduce a targeted question generation model. This model allows us to generate new types of questions for an image.
LEAF-QA: Locate, Encode & Attend for Figure Question Answering
Jul 30, 2019
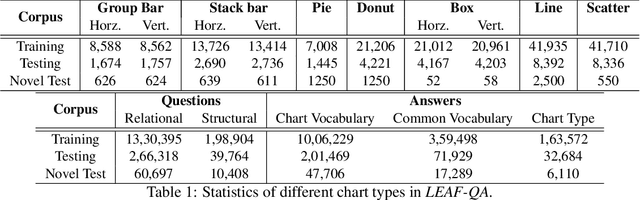
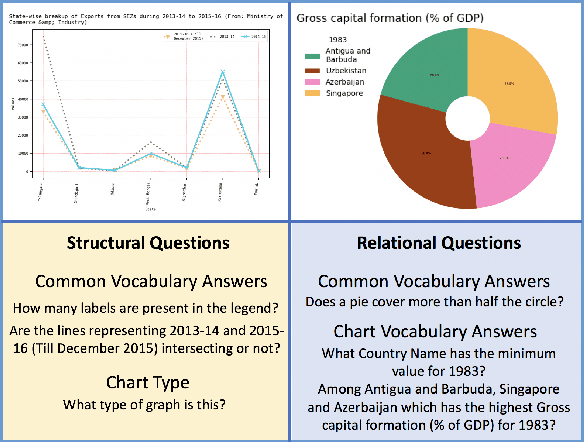
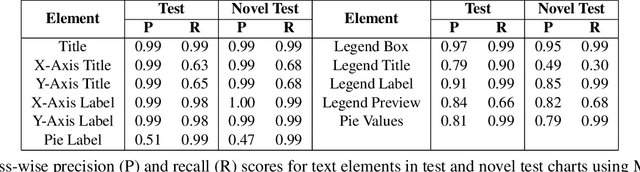
We introduce LEAF-QA, a comprehensive dataset of $250,000$ densely annotated figures/charts, constructed from real-world open data sources, along with ~2 million question-answer (QA) pairs querying the structure and semantics of these charts. LEAF-QA highlights the problem of multimodal QA, which is notably different from conventional visual QA (VQA), and has recently gained interest in the community. Furthermore, LEAF-QA is significantly more complex than previous attempts at chart QA, viz. FigureQA and DVQA, which present only limited variations in chart data. LEAF-QA being constructed from real-world sources, requires a novel architecture to enable question answering. To this end, LEAF-Net, a deep architecture involving chart element localization, question and answer encoding in terms of chart elements, and an attention network is proposed. Different experiments are conducted to demonstrate the challenges of QA on LEAF-QA. The proposed architecture, LEAF-Net also considerably advances the current state-of-the-art on FigureQA and DVQA.
Network Representation Learning: Consolidation and Renewed Bearing
May 02, 2019
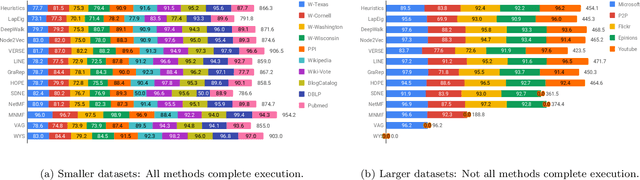
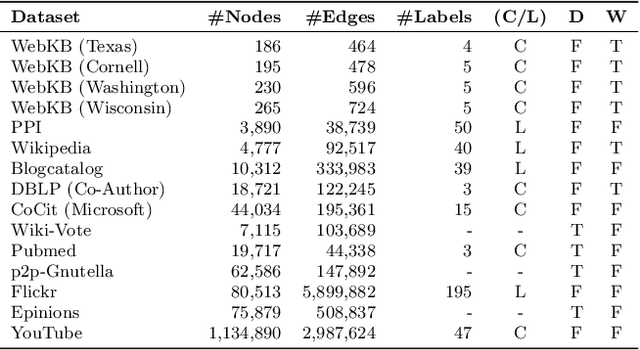
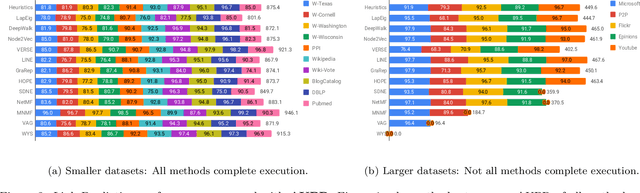
Graphs are a natural abstraction for many problems where nodes represent entities and edges represent a relationship across entities. An important area of research that has emerged over the last decade is the use of graphs as a vehicle for non-linear dimensionality reduction in a manner akin to previous efforts based on manifold learning with uses for downstream database processing, machine learning and visualization. In this systematic yet comprehensive experimental survey, we benchmark several popular network representation learning methods operating on two key tasks: link prediction and node classification. We examine the performance of 12 unsupervised embedding methods on 15 datasets. To the best of our knowledge, the scale of our study -- both in terms of the number of methods and number of datasets -- is the largest to date. Our results reveal several key insights about work-to-date in this space. First, we find that certain baseline methods (task-specific heuristics, as well as classic manifold methods) that have often been dismissed or are not considered by previous efforts can compete on certain types of datasets if they are tuned appropriately. Second, we find that recent methods based on matrix factorization offer a small but relatively consistent advantage over alternative methods (e.g., random-walk based methods) from a qualitative standpoint. Specifically, we find that MNMF, a community preserving embedding method, is the most competitive method for the link prediction task. While NetMF is the most competitive baseline for node classification. Third, no single method completely outperforms other embedding methods on both node classification and link prediction tasks. We also present several drill-down analysis that reveals settings under which certain algorithms perform well (e.g., the role of neighborhood context on performance) -- guiding the end-user.
Towards Open Intent Discovery for Conversational Text
Apr 17, 2019
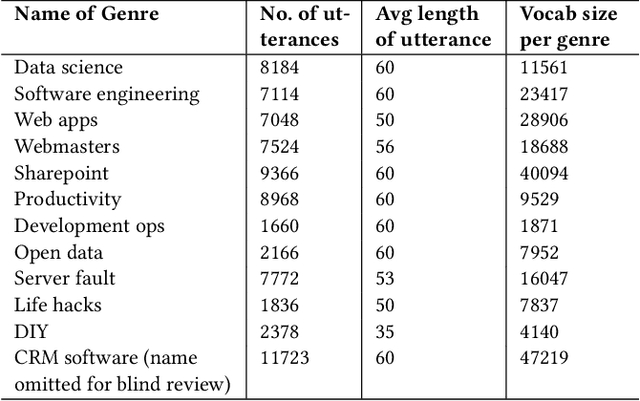
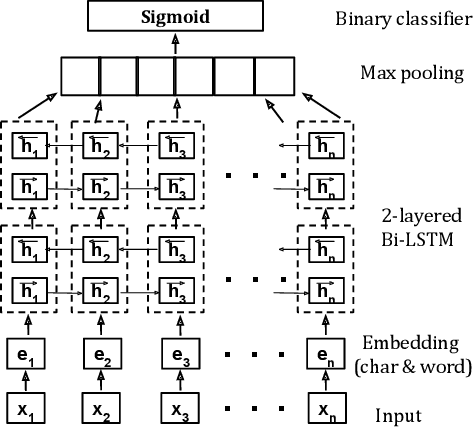

Detecting and identifying user intent from text, both written and spoken, plays an important role in modelling and understand dialogs. Existing research for intent discovery model it as a classification task with a predefined set of known categories. To generailze beyond these preexisting classes, we define a new task of \textit{open intent discovery}. We investigate how intent can be generalized to those not seen during training. To this end, we propose a two-stage approach to this task - predicting whether an utterance contains an intent, and then tagging the intent in the input utterance. Our model consists of a bidirectional LSTM with a CRF on top to capture contextual semantics, subject to some constraints. Self-attention is used to learn long distance dependencies. Further, we adapt an adversarial training approach to improve robustness and perforamce across domains. We also present a dataset of 25k real-life utterances that have been labelled via crowd sourcing. Our experiments across different domains and real-world datasets show the effectiveness of our approach, with less than 100 annotated examples needed per unique domain to recognize diverse intents. The approach outperforms state-of-the-art baselines by 5-15% F1 score points.
Forecasting Granular Audience Size for Online Advertising
Jan 08, 2019
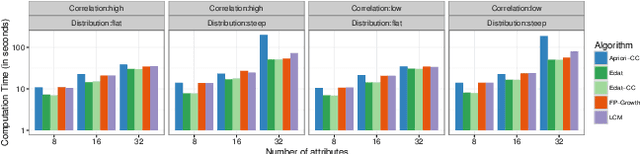
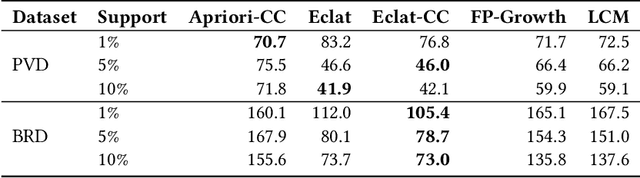
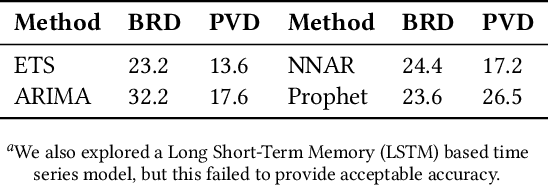
Orchestration of campaigns for online display advertising requires marketers to forecast audience size at the granularity of specific attributes of web traffic, characterized by the categorical nature of all attributes (e.g. {US, Chrome, Mobile}). With each attribute taking many values, the very large attribute combination set makes estimating audience size for any specific attribute combination challenging. We modify Eclat, a frequent itemset mining (FIM) algorithm, to accommodate categorical variables. For consequent frequent and infrequent itemsets, we then provide forecasts using time series analysis with conditional probabilities to aid approximation. An extensive simulation, based on typical characteristics of audience data, is built to stress test our modified-FIM approach. In two real datasets, comparison with baselines including neural network models, shows that our method lowers computation time of FIM for categorical data. On hold out samples we show that the proposed forecasting method outperforms these baselines.