 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpinverse: Differentiable Physics for Permeability-Aware Microstructure Reconstruction from Diffusion MRI
Mar 04, 2026Diffusion MRI (dMRI) is sensitive to microstructural barriers, yet most existing methods either assume impermeable boundaries or estimate voxel-level parameters without recovering explicit interfaces. We present Spinverse, a permeability-aware reconstruction method that inverts dMRI measurements through a fully differentiable Bloch-Torrey simulator. Spinverse represents tissue on a fixed tetrahedral grid and treats each interior face permeability as a learnable parameter; low-permeability faces act as diffusion barriers, so microstructural boundaries whose topology is not fixed a priori (up to the resolution of the ambient mesh) emerge without changing mesh connectivity or vertex positions. Given a target signal, we optimize face permeabilities by backpropagating a signal-matching loss through the PDE forward model, and recover an interface by thresholding the learned permeability field. To mitigate the ill-posedness of permeability inversion, we use mesh-based geometric priors; to avoid local minima, we use a staged multi-sequence optimization curriculum. Across a collection of synthetic voxel meshes, Spinverse reconstructs diverse geometries and demonstrates that sequence scheduling and regularization are critical to avoid outline-only solutions while improving both boundary accuracy and structural validity.
ReMiDi: Reconstruction of Microstructure Using a Differentiable Diffusion MRI Simulator
Feb 04, 2025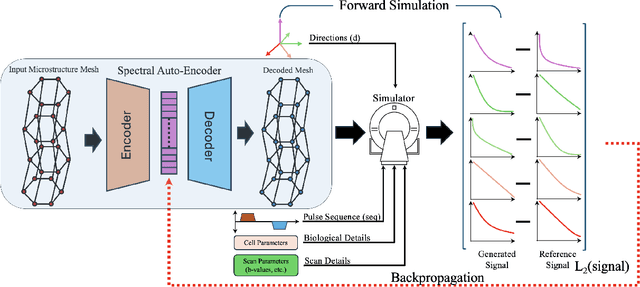

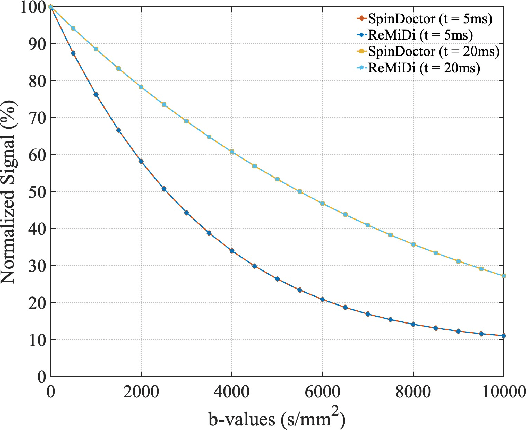
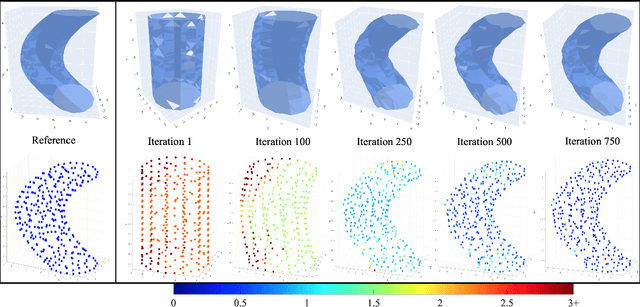
We propose ReMiDi, a novel method for inferring neuronal microstructure as arbitrary 3D meshes using a differentiable diffusion Magnetic Resonance Imaging (dMRI) simulator. We first implemented in PyTorch a differentiable dMRI simulator that simulates the forward diffusion process using a finite-element method on an input 3D microstructure mesh. To achieve significantly faster simulations, we solve the differential equation semi-analytically using a matrix formalism approach. Given a reference dMRI signal $S_{ref}$, we use the differentiable simulator to iteratively update the input mesh such that it matches $S_{ref}$ using gradient-based learning. Since directly optimizing the 3D coordinates of the vertices is challenging, particularly due to ill-posedness of the inverse problem, we instead optimize a lower-dimensional latent space representation of the mesh. The mesh is first encoded into spectral coefficients, which are further encoded into a latent $\textbf{z}$ using an auto-encoder, and are then decoded back into the true mesh. We present an end-to-end differentiable pipeline that simulates signals that can be tuned to match a reference signal by iteratively updating the latent representation $\textbf{z}$. We demonstrate the ability to reconstruct microstructures of arbitrary shapes represented by finite-element meshes, with a focus on axonal geometries found in the brain white matter, including bending, fanning and beading fibers. Our source code will be made available online.
BMapOpt: Optimization of Brain Tissue Probability Maps using a Differentiable MRI Simulator
Apr 23, 2024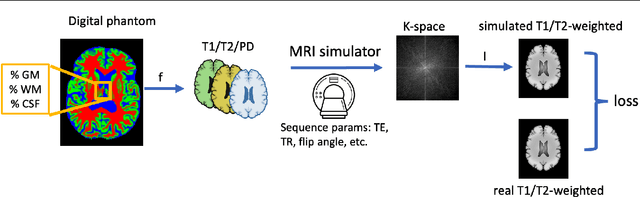
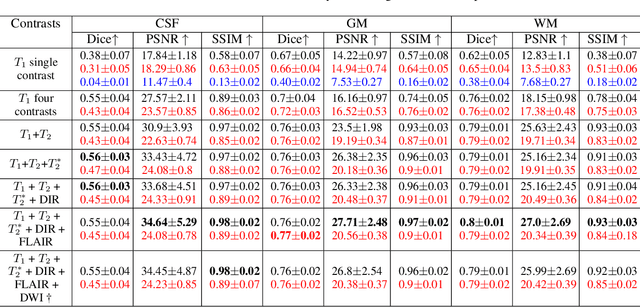
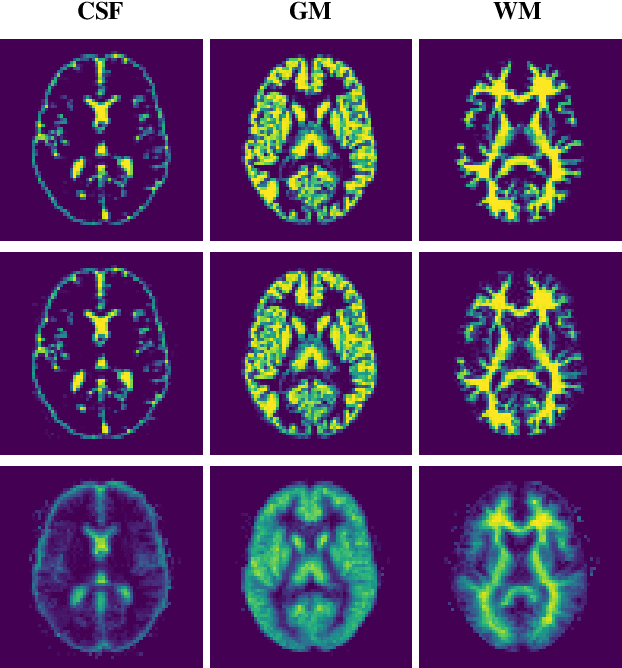
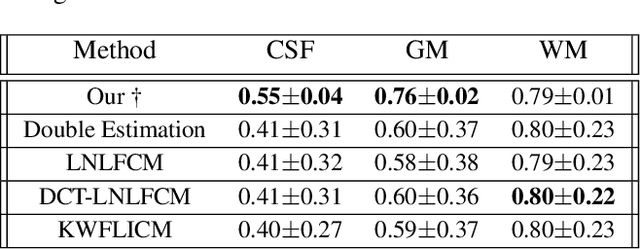
Reconstructing digital brain phantoms in the form of multi-channeled brain tissue probability maps for individual subjects is essential for capturing brain anatomical variability, understanding neurological diseases, as well as for testing image processing methods. We demonstrate the first framework that optimizes brain tissue probability maps (Gray Matter - GM, White Matter - WM, and Cerebrospinal fluid - CSF) with the help of a Physics-based differentiable MRI simulator that models the magnetization signal at each voxel in the image. Given an observed $T_1$/$T_2$-weighted MRI scan, the corresponding clinical MRI sequence, and the MRI differentiable simulator, we optimize the simulator's input probability maps by back-propagating the L2 loss between the simulator's output and the $T_1$/$T_2$-weighted scan. This approach has the significant advantage of not relying on any training data, and instead uses the strong inductive bias of the MRI simulator. We tested the model on 20 scans from the BrainWeb database and demonstrate a highly accurate reconstruction of GM, WM, and CSF.
GaSpCT: Gaussian Splatting for Novel CT Projection View Synthesis
Apr 04, 2024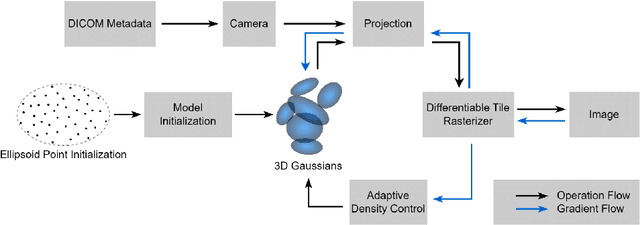



We present GaSpCT, a novel view synthesis and 3D scene representation method used to generate novel projection views for Computer Tomography (CT) scans. We adapt the Gaussian Splatting framework to enable novel view synthesis in CT based on limited sets of 2D image projections and without the need for Structure from Motion (SfM) methodologies. Therefore, we reduce the total scanning duration and the amount of radiation dose the patient receives during the scan. We adapted the loss function to our use-case by encouraging a stronger background and foreground distinction using two sparsity promoting regularizers: a beta loss and a total variation (TV) loss. Finally, we initialize the Gaussian locations across the 3D space using a uniform prior distribution of where the brain's positioning would be expected to be within the field of view. We evaluate the performance of our model using brain CT scans from the Parkinson's Progression Markers Initiative (PPMI) dataset and demonstrate that the rendered novel views closely match the original projection views of the simulated scan, and have better performance than other implicit 3D scene representations methodologies. Furthermore, we empirically observe reduced training time compared to neural network based image synthesis for sparse-view CT image reconstruction. Finally, the memory requirements of the Gaussian Splatting representations are reduced by 17% compared to the equivalent voxel grid image representations.
ScripTONES: Sentiment-Conditioned Music Generation for Movie Scripts
Jan 13, 2024



Film scores are considered an essential part of the film cinematic experience, but the process of film score generation is often expensive and infeasible for small-scale creators. Automating the process of film score composition would provide useful starting points for music in small projects. In this paper, we propose a two-stage pipeline for generating music from a movie script. The first phase is the Sentiment Analysis phase where the sentiment of a scene from the film script is encoded into the valence-arousal continuous space. The second phase is the Conditional Music Generation phase which takes as input the valence-arousal vector and conditionally generates piano MIDI music to match the sentiment. We study the efficacy of various music generation architectures by performing a qualitative user survey and propose methods to improve sentiment-conditioning in VAE architectures.
Modified LAB Algorithm with Clustering-based Search Space Reduction Method for solving Engineering Design Problems
Oct 04, 2023



A modified LAB algorithm is introduced in this paper. It builds upon the original LAB algorithm (Reddy et al. 2023), which is a socio-inspired algorithm that models competitive and learning behaviours within a group, establishing hierarchical roles. The proposed algorithm incorporates the roulette wheel approach and a reduction factor introducing inter-group competition and iteratively narrowing down the sample space. The algorithm is validated by solving the benchmark test problems from CEC 2005 and CEC 2017. The solutions are validated using standard statistical tests such as two-sided and pairwise signed rank Wilcoxon test and Friedman rank test. The algorithm exhibited improved and superior robustness as well as search space exploration capabilities. Furthermore, a Clustering-Based Search Space Reduction (C-SSR) method is proposed, making the algorithm capable to solve constrained problems. The C-SSR method enables the algorithm to identify clusters of feasible regions, satisfying the constraints and contributing to achieve the optimal solution. This method demonstrates its effectiveness as a potential alternative to traditional constraint handling techniques. The results obtained using the Modified LAB algorithm are then compared with those achieved by other recent metaheuristic algorithms.
LEAF-QA: Locate, Encode & Attend for Figure Question Answering
Jul 30, 2019
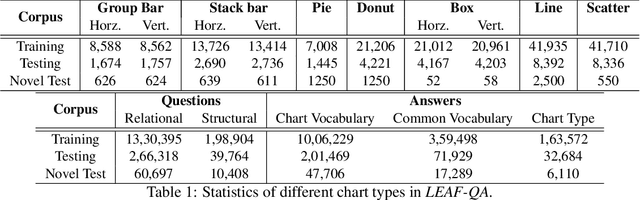
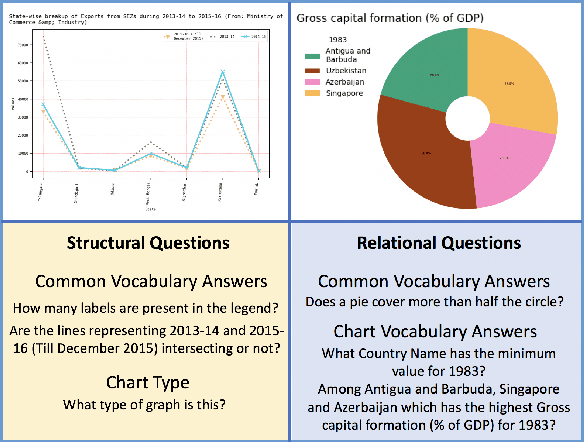
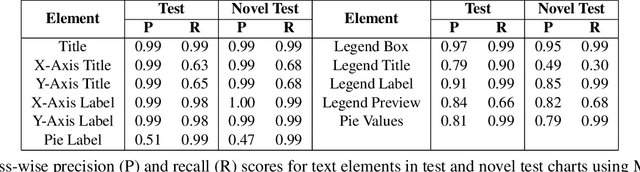
We introduce LEAF-QA, a comprehensive dataset of $250,000$ densely annotated figures/charts, constructed from real-world open data sources, along with ~2 million question-answer (QA) pairs querying the structure and semantics of these charts. LEAF-QA highlights the problem of multimodal QA, which is notably different from conventional visual QA (VQA), and has recently gained interest in the community. Furthermore, LEAF-QA is significantly more complex than previous attempts at chart QA, viz. FigureQA and DVQA, which present only limited variations in chart data. LEAF-QA being constructed from real-world sources, requires a novel architecture to enable question answering. To this end, LEAF-Net, a deep architecture involving chart element localization, question and answer encoding in terms of chart elements, and an attention network is proposed. Different experiments are conducted to demonstrate the challenges of QA on LEAF-QA. The proposed architecture, LEAF-Net also considerably advances the current state-of-the-art on FigureQA and DVQA.
Document Chunking and Learning Objective Generation for Instruction Design
Aug 06, 2018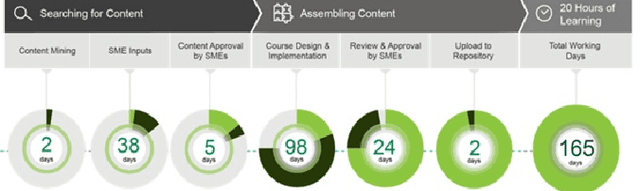
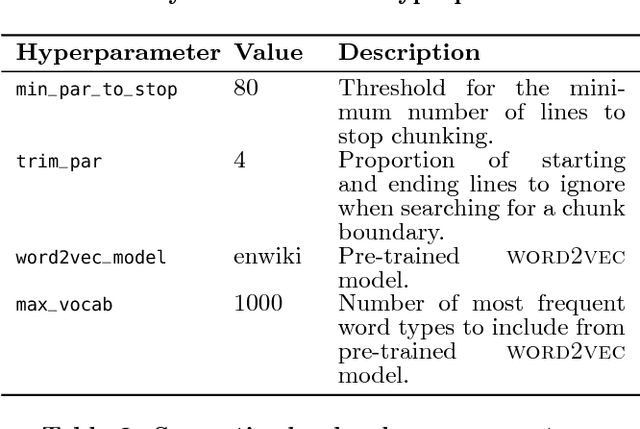
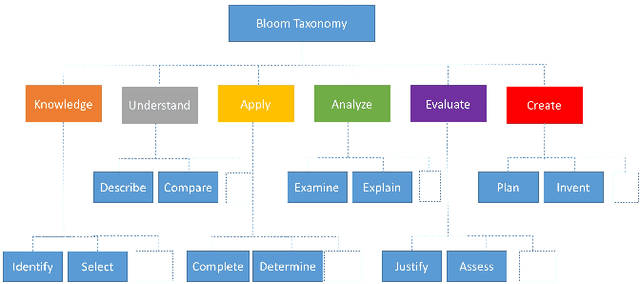
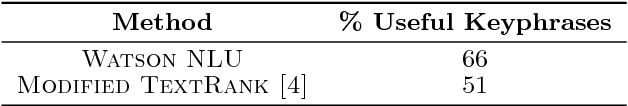
Instructional Systems Design is the practice of creating of instructional experiences that make the acquisition of knowledge and skill more efficient, effective, and appealing. Specifically in designing courses, an hour of training material can require between 30 to 500 hours of effort in sourcing and organizing reference data for use in just the preparation of course material. In this paper, we present the first system of its kind that helps reduce the effort associated with sourcing reference material and course creation. We present algorithms for document chunking and automatic generation of learning objectives from content, creating descriptive content metadata to improve content-discoverability. Unlike existing methods, the learning objectives generated by our system incorporate pedagogically motivated Bloom's verbs. We demonstrate the usefulness of our methods using real world data from the banking industry and through a live deployment at a large pharmaceutical company.