 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Multi-Domain Learning for Automatic Short Answer Grading
Feb 25, 2019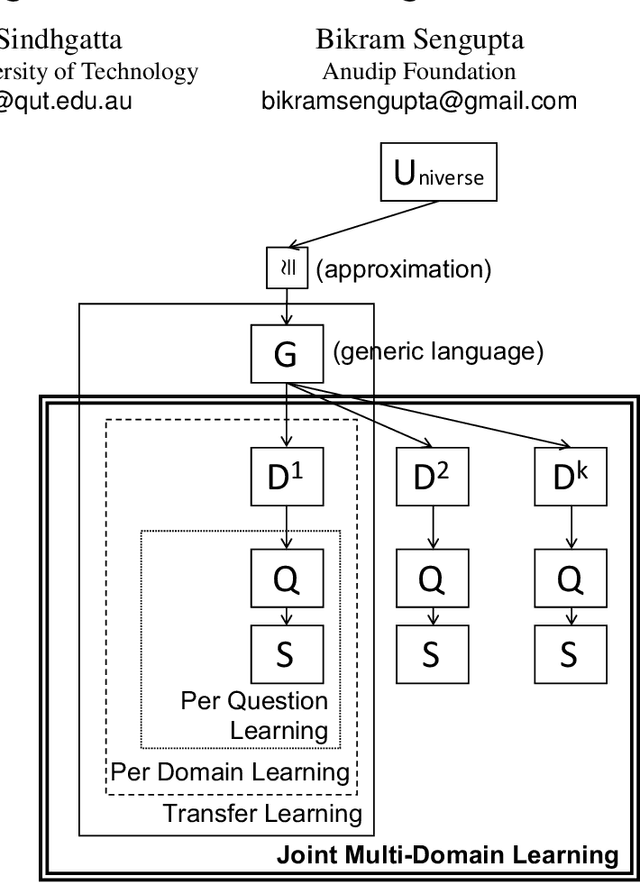


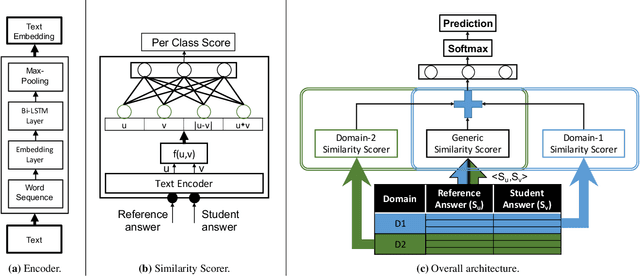
One of the fundamental challenges towards building any intelligent tutoring system is its ability to automatically grade short student answers. A typical automatic short answer grading system (ASAG) grades student answers across multiple domains (or subjects). Grading student answers requires building a supervised machine learning model that evaluates the similarity of the student answer with the reference answer(s). We observe that unlike typical textual similarity or entailment tasks, the notion of similarity is not universal here. On one hand, para-phrasal constructs of the language can indicate similarity independent of the domain. On the other hand, two words, or phrases, that are not strict synonyms of each other, might mean the same in certain domains. Building on this observation, we propose JMD-ASAG, the first joint multidomain deep learning architecture for automatic short answer grading that performs domain adaptation by learning generic and domain-specific aspects from the limited domain-wise training data. JMD-ASAG not only learns the domain-specific characteristics but also overcomes the dependence on a large corpus by learning the generic characteristics from the task-specific data itself. On a large-scale industry dataset and a benchmarking dataset, we show that our model performs significantly better than existing techniques which either learn domain-specific models or adapt a generic similarity scoring model from a large corpus. Further, on the benchmarking dataset, we report state-of-the-art results against all existing non-neural and neural models.
Document Chunking and Learning Objective Generation for Instruction Design
Aug 06, 2018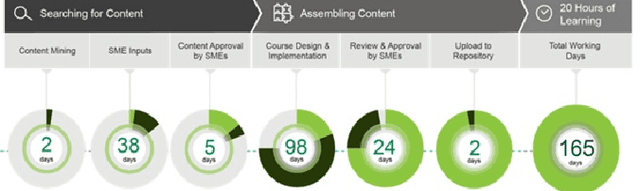
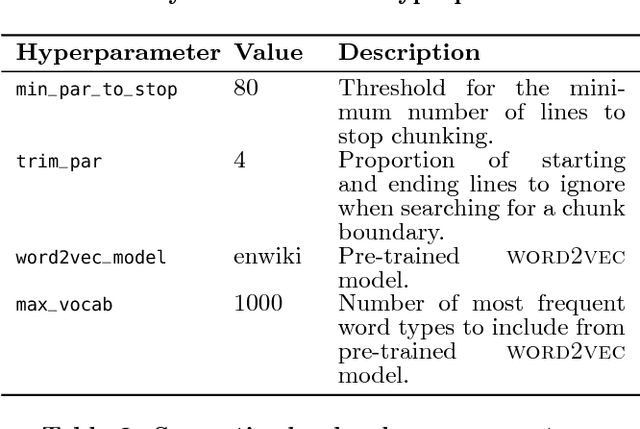
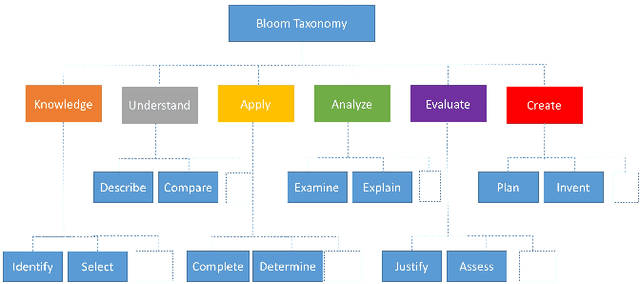
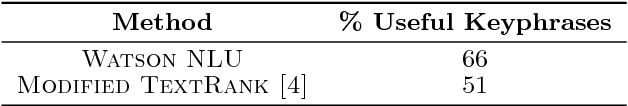
Instructional Systems Design is the practice of creating of instructional experiences that make the acquisition of knowledge and skill more efficient, effective, and appealing. Specifically in designing courses, an hour of training material can require between 30 to 500 hours of effort in sourcing and organizing reference data for use in just the preparation of course material. In this paper, we present the first system of its kind that helps reduce the effort associated with sourcing reference material and course creation. We present algorithms for document chunking and automatic generation of learning objectives from content, creating descriptive content metadata to improve content-discoverability. Unlike existing methods, the learning objectives generated by our system incorporate pedagogically motivated Bloom's verbs. We demonstrate the usefulness of our methods using real world data from the banking industry and through a live deployment at a large pharmaceutical company.