 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Seasonal Climate Predictions for Demand Forecasting with Modular Neural Network
Sep 05, 2023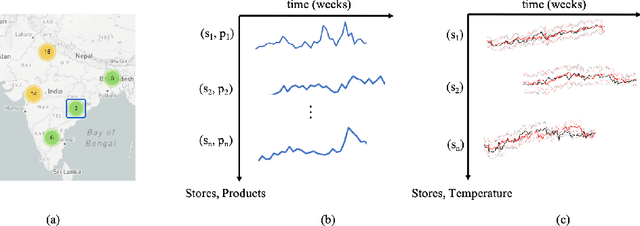
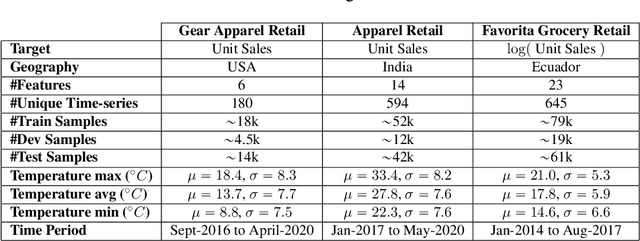
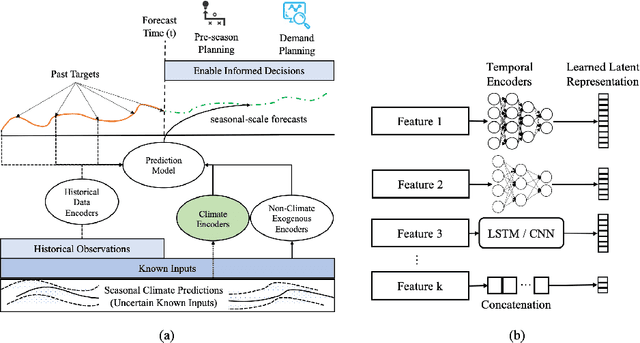
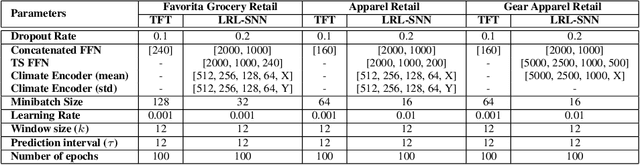
Current time-series forecasting problems use short-term weather attributes as exogenous inputs. However, in specific time-series forecasting solutions (e.g., demand prediction in the supply chain), seasonal climate predictions are crucial to improve its resilience. Representing mid to long-term seasonal climate forecasts is challenging as seasonal climate predictions are uncertain, and encoding spatio-temporal relationship of climate forecasts with demand is complex. We propose a novel modeling framework that efficiently encodes seasonal climate predictions to provide robust and reliable time-series forecasting for supply chain functions. The encoding framework enables effective learning of latent representations -- be it uncertain seasonal climate prediction or other time-series data (e.g., buyer patterns) -- via a modular neural network architecture. Our extensive experiments indicate that learning such representations to model seasonal climate forecast results in an error reduction of approximately 13\% to 17\% across multiple real-world data sets compared to existing demand forecasting methods.
Small, Sparse, but Substantial: Techniques for Segmenting Small Agricultural Fields Using Sparse Ground Data
May 05, 2020

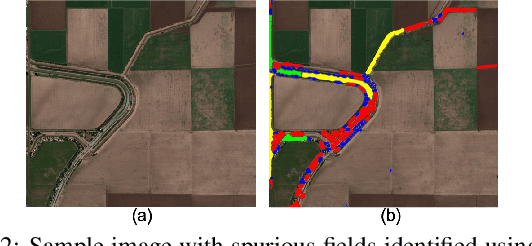

The recent thrust on digital agriculture (DA) has renewed significant research interest in the automated delineation of agricultural fields. Most prior work addressing this problem have focused on detecting medium to large fields, while there is strong evidence that around 40\% of the fields world-wide and 70% of the fields in Asia and Africa are small. The lack of adequate labeled images for small fields, huge variations in their color, texture, and shape, and faint boundary lines separating them make it difficult to develop an end-to-end learning model for detecting such fields. Hence, in this paper, we present a multi-stage approach that uses a combination of machine learning and image processing techniques. In the first stage, we leverage state-of-the-art edge detection algorithms such as holistically-nested edge detection (HED) to extract first-level contours and polygons. In the second stage, we propose image-processing techniques to identify polygons that are non-fields, over-segmentations, or noise and eliminate them. The next stage tackles under-segmentations using a combination of a novel ``cut-point'' based technique and localized second-level edge detection to obtain individual parcels. Since a few small, non-cropped but vegetated or constructed pockets can be interspersed in areas that are predominantly croplands, in the final stage, we train a classifier for identifying each parcel from the previous stage as an agricultural field or not. In an evaluation using high-resolution imagery, we show that our approach has a high F-Score of 0.84 in areas with large fields and reasonable accuracy with an F-Score of 0.73 in areas with small fields, which is encouraging.
Joint Multi-Domain Learning for Automatic Short Answer Grading
Feb 25, 2019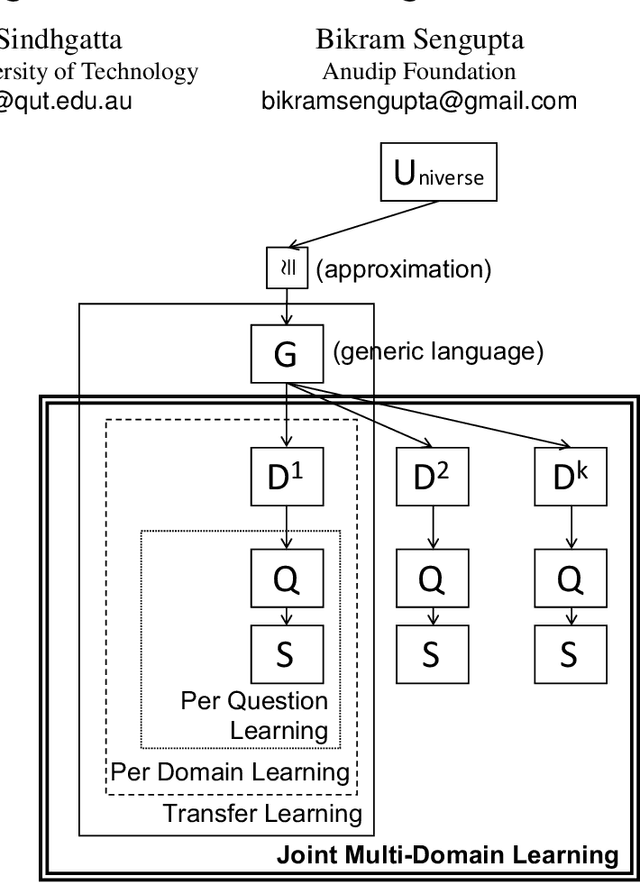


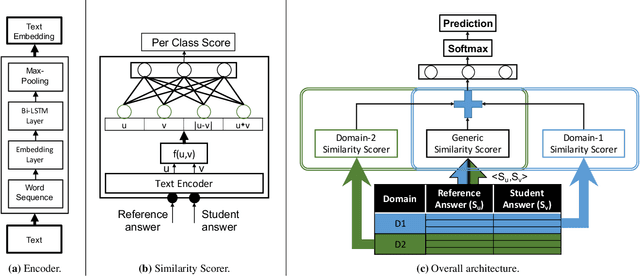
One of the fundamental challenges towards building any intelligent tutoring system is its ability to automatically grade short student answers. A typical automatic short answer grading system (ASAG) grades student answers across multiple domains (or subjects). Grading student answers requires building a supervised machine learning model that evaluates the similarity of the student answer with the reference answer(s). We observe that unlike typical textual similarity or entailment tasks, the notion of similarity is not universal here. On one hand, para-phrasal constructs of the language can indicate similarity independent of the domain. On the other hand, two words, or phrases, that are not strict synonyms of each other, might mean the same in certain domains. Building on this observation, we propose JMD-ASAG, the first joint multidomain deep learning architecture for automatic short answer grading that performs domain adaptation by learning generic and domain-specific aspects from the limited domain-wise training data. JMD-ASAG not only learns the domain-specific characteristics but also overcomes the dependence on a large corpus by learning the generic characteristics from the task-specific data itself. On a large-scale industry dataset and a benchmarking dataset, we show that our model performs significantly better than existing techniques which either learn domain-specific models or adapt a generic similarity scoring model from a large corpus. Further, on the benchmarking dataset, we report state-of-the-art results against all existing non-neural and neural models.
Adaptive Locally Affine-Invariant Shape Matching
Apr 25, 2015



Matching deformable objects using their shapes is an important problem in computer vision since shape is perhaps the most distinguishable characteristic of an object. The problem is difficult due to many factors such as intra-class variations, local deformations, articulations, viewpoint changes and missed and extraneous contour portions due to errors in shape extraction. While small local deformations has been handled in the literature by allowing some leeway in the matching of individual contour points via methods such as Chamfer distance and Hausdorff distance, handling more severe deformations and articulations has been done by applying local geometric corrections such as similarity or affine. However, determining which portions of the shape should be used for the geometric corrections is very hard, although some methods have been tried. In this paper, we address this problem by an efficient search for the group of contour segments to be clustered together for a geometric correction using Dynamic Programming by essentially searching for the segmentations of two shapes that lead to the best matching between them. At the same time, we allow portions of the contours to remain unmatched to handle missing and extraneous contour portions. Experiments indicate that our method outperforms other algorithms, especially when the shapes to be matched are more complex.