 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Sample-Efficient Generalized Planning via Learned Transition Models
Feb 26, 2026Generalized planning studies the construction of solution strategies that generalize across families of planning problems sharing a common domain model, formally defined by a transition function $γ: S \times A \rightarrow S$. Classical approaches achieve such generalization through symbolic abstractions and explicit reasoning over $γ$. In contrast, recent Transformer-based planners, such as PlanGPT and Plansformer, largely cast generalized planning as direct action-sequence prediction, bypassing explicit transition modeling. While effective on in-distribution instances, these approaches typically require large datasets and model sizes, and often suffer from state drift in long-horizon settings due to the absence of explicit world-state evolution. In this work, we formulate generalized planning as a transition-model learning problem, in which a neural model explicitly approximates the successor-state function $\hatγ \approx γ$ and generates plans by rolling out symbolic state trajectories. Instead of predicting actions directly, the model autoregressively predicts intermediate world states, thereby learning the domain dynamics as an implicit world model. To study size-invariant generalization and sample efficiency, we systematically evaluate multiple state representations and neural architectures, including relational graph encodings. Our results show that learning explicit transition models yields higher out-of-distribution satisficing-plan success than direct action-sequence prediction in multiple domains, while achieving these gains with significantly fewer training instances and smaller models. This is an extended version of a short paper accepted at ICAPS 2026 under the same title.
FABLE: A Novel Data-Flow Analysis Benchmark on Procedural Text for Large Language Model Evaluation
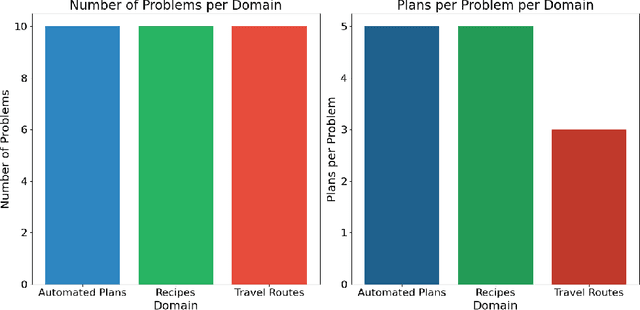
May 30, 2025Understanding how data moves, transforms, and persists, known as data flow, is fundamental to reasoning in procedural tasks. Despite their fluency in natural and programming languages, large language models (LLMs), although increasingly being applied to decisions with procedural tasks, have not been systematically evaluated for their ability to perform data-flow reasoning. We introduce FABLE, an extensible benchmark designed to assess LLMs' understanding of data flow using structured, procedural text. FABLE adapts eight classical data-flow analyses from software engineering: reaching definitions, very busy expressions, available expressions, live variable analysis, interval analysis, type-state analysis, taint analysis, and concurrency analysis. These analyses are instantiated across three real-world domains: cooking recipes, travel routes, and automated plans. The benchmark includes 2,400 question-answer pairs, with 100 examples for each domain-analysis combination. We evaluate three types of LLMs: a reasoning-focused model (DeepSeek-R1 8B), a general-purpose model (LLaMA 3.1 8B), and a code-specific model (Granite Code 8B). Each model is tested using majority voting over five sampled completions per prompt. Results show that the reasoning model achieves higher accuracy, but at the cost of over 20 times slower inference compared to the other models. In contrast, the general-purpose and code-specific models perform close to random chance. FABLE provides the first diagnostic benchmark to systematically evaluate data-flow reasoning and offers insights for developing models with stronger procedural understanding.
Enhancing Explainability and Reliable Decision-Making in Particle Swarm Optimization through Communication Topologies
Apr 17, 2025

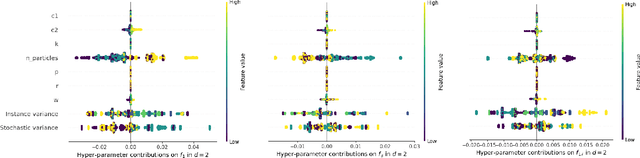

Swarm intelligence effectively optimizes complex systems across fields like engineering and healthcare, yet algorithm solutions often suffer from low reliability due to unclear configurations and hyperparameters. This study analyzes Particle Swarm Optimization (PSO), focusing on how different communication topologies Ring, Star, and Von Neumann affect convergence and search behaviors. Using an adapted IOHxplainer , an explainable benchmarking tool, we investigate how these topologies influence information flow, diversity, and convergence speed, clarifying the balance between exploration and exploitation. Through visualization and statistical analysis, the research enhances interpretability of PSO's decisions and provides practical guidelines for choosing suitable topologies for specific optimization tasks. Ultimately, this contributes to making swarm based optimization more transparent, robust, and trustworthy.
SafeChat: A Framework for Building Trustworthy Collaborative Assistants and a Case Study of its Usefulness
Apr 15, 2025



Collaborative assistants, or chatbots, are data-driven decision support systems that enable natural interaction for task completion. While they can meet critical needs in modern society, concerns about their reliability and trustworthiness persist. In particular, Large Language Model (LLM)-based chatbots like ChatGPT, Gemini, and DeepSeek are becoming more accessible. However, such chatbots have limitations, including their inability to explain response generation, the risk of generating problematic content, the lack of standardized testing for reliability, and the need for deep AI expertise and extended development times. These issues make chatbots unsuitable for trust-sensitive applications like elections or healthcare. To address these concerns, we introduce SafeChat, a general architecture for building safe and trustworthy chatbots, with a focus on information retrieval use cases. Key features of SafeChat include: (a) safety, with a domain-agnostic design where responses are grounded and traceable to approved sources (provenance), and 'do-not-respond' strategies to prevent harmful answers; (b) usability, with automatic extractive summarization of long responses, traceable to their sources, and automated trust assessments to communicate expected chatbot behavior, such as sentiment; and (c) fast, scalable development, including a CSV-driven workflow, automated testing, and integration with various devices. We implemented SafeChat in an executable framework using the open-source chatbot platform Rasa. A case study demonstrates its application in building ElectionBot-SC, a chatbot designed to safely disseminate official election information. SafeChat is being used in many domains, validating its potential, and is available at: https://github.com/ai4society/trustworthy-chatbot.
An Explainable Reconfiguration-Based Optimization Algorithm for Industrial and Reliability-Redundancy Allocation Problems
Apr 02, 2025



Industrial and reliability optimization problems often involve complex constraints and require efficient, interpretable solutions. This paper presents AI-AEFA, an advanced parameter reconfiguration-based metaheuristic algorithm designed to address large-scale industrial and reliability-redundancy allocation problems. AI-AEFA enhances search space exploration and convergence efficiency through a novel log-sigmoid-based parameter adaptation and chaotic mapping mechanism. The algorithm is validated across twenty-eight IEEE CEC 2017 constrained benchmark problems, fifteen large-scale industrial optimization problems, and seven reliability-redundancy allocation problems, consistently outperforming state-of-the-art optimization techniques in terms of feasibility, computational efficiency, and convergence speed. The additional key contribution of this work is the integration of SHAP (Shapley Additive Explanations) to enhance the interpretability of AI-AEFA, providing insights into the impact of key parameters such as Coulomb's constant, charge, acceleration, and electrostatic force. This explainability feature enables a deeper understanding of decision-making within the AI-AEFA framework during the optimization processes. The findings confirm AI-AEFA as a robust, scalable, and interpretable optimization tool with significant real-world applications.
A Novel Approach to Balance Convenience and Nutrition in Meals With Long-Term Group Recommendations and Reasoning on Multimodal Recipes and its Implementation in BEACON
Dec 23, 2024



"A common decision made by people, whether healthy or with health conditions, is choosing meals like breakfast, lunch, and dinner, comprising combinations of foods for appetizer, main course, side dishes, desserts, and beverages. Often, this decision involves tradeoffs between nutritious choices (e.g., salt and sugar levels, nutrition content) and convenience (e.g., cost and accessibility, cuisine type, food source type). We present a data-driven solution for meal recommendations that considers customizable meal configurations and time horizons. This solution balances user preferences while accounting for food constituents and cooking processes. Our contributions include introducing goodness measures, a recipe conversion method from text to the recently introduced multimodal rich recipe representation (R3) format, learning methods using contextual bandits that show promising preliminary results, and the prototype, usage-inspired, BEACON system."
PLANTS: A Novel Problem and Dataset for Summarization of Planning-Like (PL) Tasks
Jul 18, 2024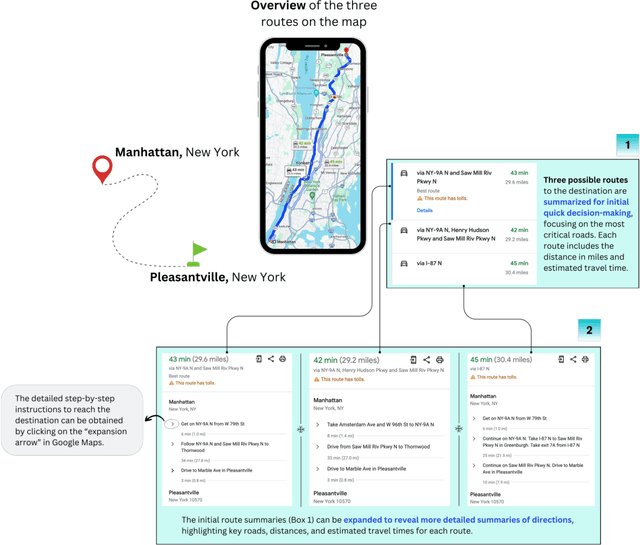
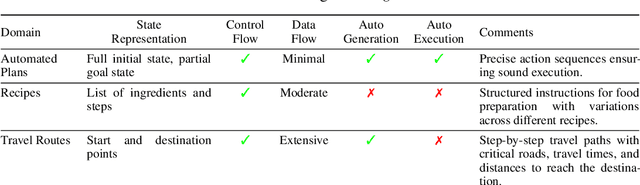

Text summarization is a well-studied problem that deals with deriving insights from unstructured text consumed by humans, and it has found extensive business applications. However, many real-life tasks involve generating a series of actions to achieve specific goals, such as workflows, recipes, dialogs, and travel plans. We refer to them as planning-like (PL) tasks noting that the main commonality they share is control flow information. which may be partially specified. Their structure presents an opportunity to create more practical summaries to help users make quick decisions. We investigate this observation by introducing a novel plan summarization problem, presenting a dataset, and providing a baseline method for generating PL summaries. Using quantitative metrics and qualitative user studies to establish baselines, we evaluate the plan summaries from our method and large language models. We believe the novel problem and dataset can reinvigorate research in summarization, which some consider as a solved problem.
Multi-Intent Detection in User Provided Annotations for Programming by Examples Systems
Jul 08, 2023



In mapping enterprise applications, data mapping remains a fundamental part of integration development, but its time consuming. An increasing number of applications lack naming standards, and nested field structures further add complexity for the integration developers. Once the mapping is done, data transformation is the next challenge for the users since each application expects data to be in a certain format. Also, while building integration flow, developers need to understand the format of the source and target data field and come up with transformation program that can change data from source to target format. The problem of automatic generation of a transformation program through program synthesis paradigm from some specifications has been studied since the early days of Artificial Intelligence (AI). Programming by Example (PBE) is one such kind of technique that targets automatic inferencing of a computer program to accomplish a format or string conversion task from user-provided input and output samples. To learn the correct intent, a diverse set of samples from the user is required. However, there is a possibility that the user fails to provide a diverse set of samples. This can lead to multiple intents or ambiguity in the input and output samples. Hence, PBE systems can get confused in generating the correct intent program. In this paper, we propose a deep neural network based ambiguity prediction model, which analyzes the input-output strings and maps them to a different set of properties responsible for multiple intent. Users can analyze these properties and accordingly can provide new samples or modify existing samples which can help in building a better PBE system for mapping enterprise applications.
Data Quality Toolkit: Automatic assessment of data quality and remediation for machine learning datasets
Sep 05, 2021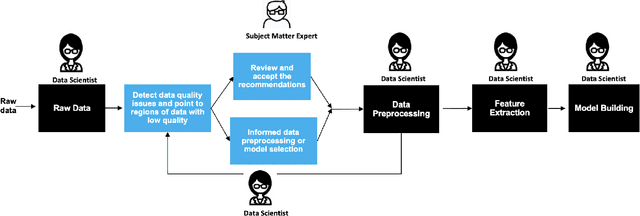

The quality of training data has a huge impact on the efficiency, accuracy and complexity of machine learning tasks. Various tools and techniques are available that assess data quality with respect to general cleaning and profiling checks. However these techniques are not applicable to detect data issues in the context of machine learning tasks, like noisy labels, existence of overlapping classes etc. We attempt to re-look at the data quality issues in the context of building a machine learning pipeline and build a tool that can detect, explain and remediate issues in the data, and systematically and automatically capture all the changes applied to the data. We introduce the Data Quality Toolkit for machine learning as a library of some key quality metrics and relevant remediation techniques to analyze and enhance the readiness of structured training datasets for machine learning projects. The toolkit can reduce the turn-around times of data preparation pipelines and streamline the data quality assessment process. Our toolkit is publicly available via IBM API Hub [1] platform, any developer can assess the data quality using the IBM's Data Quality for AI apis [2]. Detailed tutorials are also available on IBM Learning Path [3].
Comparison of Outlier Detection Techniques for Structured Data
Jun 16, 2021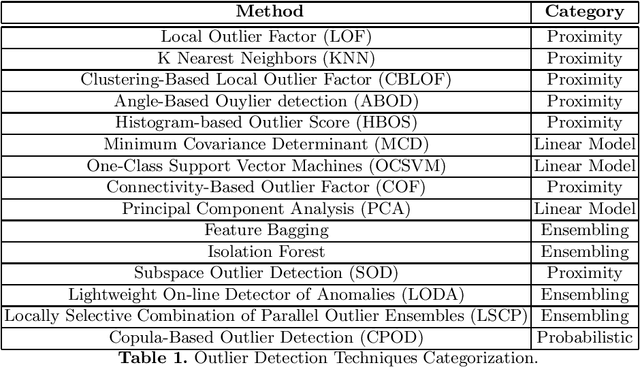
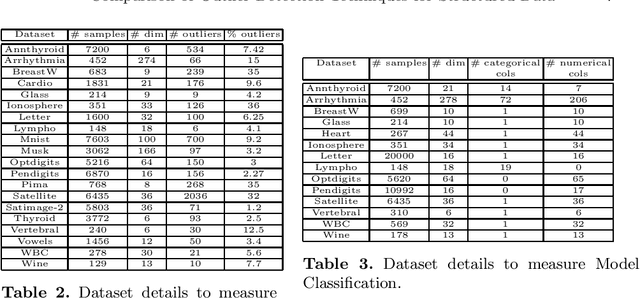
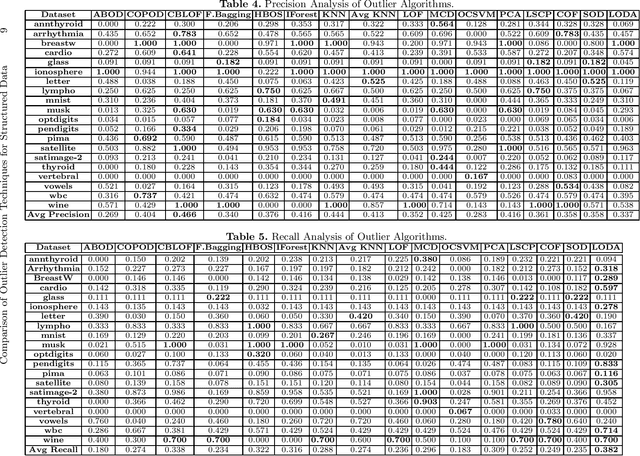

An outlier is an observation or a data point that is far from rest of the data points in a given dataset or we can be said that an outlier is away from the center of mass of observations. Presence of outliers can skew statistical measures and data distributions which can lead to misleading representation of the underlying data and relationships. It is seen that the removal of outliers from the training dataset before modeling can give better predictions. With the advancement of machine learning, the outlier detection models are also advancing at a good pace. The goal of this work is to highlight and compare some of the existing outlier detection techniques for the data scientists to use that information for outlier algorithm selection while building a machine learning model.