 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Search To Sampling: Generative Models For Robust Algorithmic Recourse
May 12, 2025



Algorithmic Recourse provides recommendations to individuals who are adversely impacted by automated model decisions, on how to alter their profiles to achieve a favorable outcome. Effective recourse methods must balance three conflicting goals: proximity to the original profile to minimize cost, plausibility for realistic recourse, and validity to ensure the desired outcome. We show that existing methods train for these objectives separately and then search for recourse through a joint optimization over the recourse goals during inference, leading to poor recourse recommendations. We introduce GenRe, a generative recourse model designed to train the three recourse objectives jointly. Training such generative models is non-trivial due to lack of direct recourse supervision. We propose efficient ways to synthesize such supervision and further show that GenRe's training leads to a consistent estimator. Unlike most prior methods, that employ non-robust gradient descent based search during inference, GenRe simply performs a forward sampling over the generative model to produce minimum cost recourse, leading to superior performance across multiple metrics. We also demonstrate GenRe provides the best trade-off between cost, plausibility and validity, compared to state-of-art baselines. Our code is available at: https://github.com/prateekgargx/genre.
Robust Root Cause Diagnosis using In-Distribution Interventions
May 02, 2025



Diagnosing the root cause of an anomaly in a complex interconnected system is a pressing problem in today's cloud services and industrial operations. We propose In-Distribution Interventions (IDI), a novel algorithm that predicts root cause as nodes that meet two criteria: 1) **Anomaly:** root cause nodes should take on anomalous values; 2) **Fix:** had the root cause nodes assumed usual values, the target node would not have been anomalous. Prior methods of assessing the fix condition rely on counterfactuals inferred from a Structural Causal Model (SCM) trained on historical data. But since anomalies are rare and fall outside the training distribution, the fitted SCMs yield unreliable counterfactual estimates. IDI overcomes this by relying on interventional estimates obtained by solely probing the fitted SCM at in-distribution inputs. We present a theoretical analysis comparing and bounding the errors in assessing the fix condition using interventional and counterfactual estimates. We then conduct experiments by systematically varying the SCM's complexity to demonstrate the cases where IDI's interventional approach outperforms the counterfactual approach and vice versa. Experiments on both synthetic and PetShop RCD benchmark datasets demonstrate that \our\ consistently identifies true root causes more accurately and robustly than nine existing state-of-the-art RCD baselines. Code is released at https://github.com/nlokeshiisc/IDI_release.
Leveraging a Simulator for Learning Causal Representations from Post-Treatment Covariates for CATE
Feb 07, 2025Treatment effect estimation involves assessing the impact of different treatments on individual outcomes. Current methods estimate Conditional Average Treatment Effect (CATE) using observational datasets where covariates are collected before treatment assignment and outcomes are observed afterward, under assumptions like positivity and unconfoundedness. In this paper, we address a scenario where both covariates and outcomes are gathered after treatment. We show that post-treatment covariates render CATE unidentifiable, and recovering CATE requires learning treatment-independent causal representations. Prior work shows that such representations can be learned through contrastive learning if counterfactual supervision is available in observational data. However, since counterfactuals are rare, other works have explored using simulators that offer synthetic counterfactual supervision. Our goal in this paper is to systematically analyze the role of simulators in estimating CATE. We analyze the CATE error of several baselines and highlight their limitations. We then establish a generalization bound that characterizes the CATE error from jointly training on real and simulated distributions, as a function of the real-simulator mismatch. Finally, we introduce SimPONet, a novel method whose loss function is inspired from our generalization bound. We further show how SimPONet adjusts the simulator's influence on the learning objective based on the simulator's relevance to the CATE task. We experiment with various DGPs, by systematically varying the real-simulator distribution gap to evaluate SimPONet's efficacy against state-of-the-art CATE baselines.
Tab-Shapley: Identifying Top-k Tabular Data Quality Insights
Jan 12, 2025



We present an unsupervised method for aggregating anomalies in tabular datasets by identifying the top-k tabular data quality insights. Each insight consists of a set of anomalous attributes and the corresponding subsets of records that serve as evidence to the user. The process of identifying these insight blocks is challenging due to (i) the absence of labeled anomalies, (ii) the exponential size of the subset search space, and (iii) the complex dependencies among attributes, which obscure the true sources of anomalies. Simple frequency-based methods fail to capture these dependencies, leading to inaccurate results. To address this, we introduce Tab-Shapley, a cooperative game theory based framework that uses Shapley values to quantify the contribution of each attribute to the data's anomalous nature. While calculating Shapley values typically requires exponential time, we show that our game admits a closed-form solution, making the computation efficient. We validate the effectiveness of our approach through empirical analysis on real-world tabular datasets with ground-truth anomaly labels.
PairNet: Training with Observed Pairs to Estimate Individual Treatment Effect
Jun 06, 2024



Given a dataset of individuals each described by a covariate vector, a treatment, and an observed outcome on the treatment, the goal of the individual treatment effect (ITE) estimation task is to predict outcome changes resulting from a change in treatment. A fundamental challenge is that in the observational data, a covariate's outcome is observed only under one treatment, whereas we need to infer the difference in outcomes under two different treatments. Several existing approaches address this issue through training with inferred pseudo-outcomes, but their success relies on the quality of these pseudo-outcomes. We propose PairNet, a novel ITE estimation training strategy that minimizes losses over pairs of examples based on their factual observed outcomes. Theoretical analysis for binary treatments reveals that PairNet is a consistent estimator of ITE risk, and achieves smaller generalization error than baseline models. Empirical comparison with thirteen existing methods across eight benchmarks, covering both discrete and continuous treatments, shows that PairNet achieves significantly lower ITE error compared to the baselines. Also, it is model-agnostic and easy to implement.
Continuous Treatment Effect Estimation Using Gradient Interpolation and Kernel Smoothing
Jan 27, 2024



We address the Individualized continuous treatment effect (ICTE) estimation problem where we predict the effect of any continuous-valued treatment on an individual using observational data. The main challenge in this estimation task is the potential confounding of treatment assignment with an individual's covariates in the training data, whereas during inference ICTE requires prediction on independently sampled treatments. In contrast to prior work that relied on regularizers or unstable GAN training, we advocate the direct approach of augmenting training individuals with independently sampled treatments and inferred counterfactual outcomes. We infer counterfactual outcomes using a two-pronged strategy: a Gradient Interpolation for close-to-observed treatments, and a Gaussian Process based Kernel Smoothing which allows us to downweigh high variance inferences. We evaluate our method on five benchmarks and show that our method outperforms six state-of-the-art methods on the counterfactual estimation error. We analyze the superior performance of our method by showing that (1) our inferred counterfactual responses are more accurate, and (2) adding them to the training data reduces the distributional distance between the confounded training distribution and test distribution where treatment is independent of covariates. Our proposed method is model-agnostic and we show that it improves ICTE accuracy of several existing models.
Gradient Coreset for Federated Learning
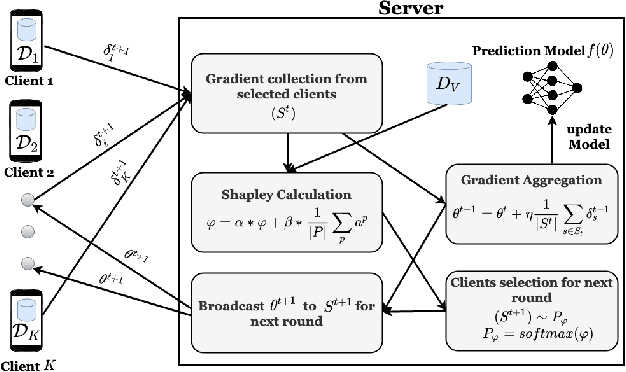
Jan 13, 2024Federated Learning (FL) is used to learn machine learning models with data that is partitioned across multiple clients, including resource-constrained edge devices. It is therefore important to devise solutions that are efficient in terms of compute, communication, and energy consumption, while ensuring compliance with the FL framework's privacy requirements. Conventional approaches to these problems select a weighted subset of the training dataset, known as coreset, and learn by fitting models on it. Such coreset selection approaches are also known to be robust to data noise. However, these approaches rely on the overall statistics of the training data and are not easily extendable to the FL setup. In this paper, we propose an algorithm called Gradient based Coreset for Robust and Efficient Federated Learning (GCFL) that selects a coreset at each client, only every $K$ communication rounds and derives updates only from it, assuming the availability of a small validation dataset at the server. We demonstrate that our coreset selection technique is highly effective in accounting for noise in clients' data. We conduct experiments using four real-world datasets and show that GCFL is (1) more compute and energy efficient than FL, (2) robust to various kinds of noise in both the feature space and labels, (3) preserves the privacy of the validation dataset, and (4) introduces a small communication overhead but achieves significant gains in performance, particularly in cases when the clients' data is noisy.
Game of Gradients: Mitigating Irrelevant Clients in Federated Learning
Oct 23, 2021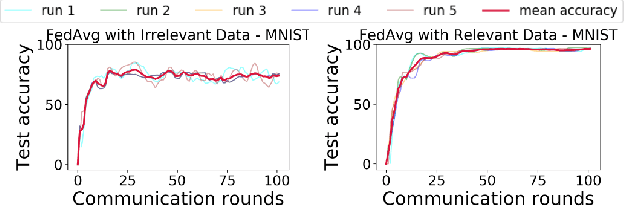
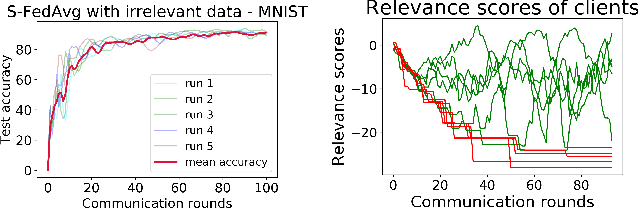
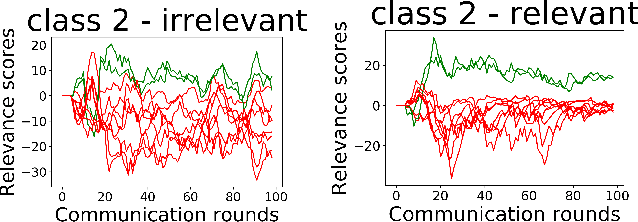
The paradigm of Federated learning (FL) deals with multiple clients participating in collaborative training of a machine learning model under the orchestration of a central server. In this setup, each client's data is private to itself and is not transferable to other clients or the server. Though FL paradigm has received significant interest recently from the research community, the problem of selecting the relevant clients w.r.t. the central server's learning objective is under-explored. We refer to these problems as Federated Relevant Client Selection (FRCS). Because the server doesn't have explicit control over the nature of data possessed by each client, the problem of selecting relevant clients is significantly complex in FL settings. In this paper, we resolve important and related FRCS problems viz., selecting clients with relevant data, detecting clients that possess data relevant to a particular target label, and rectifying corrupted data samples of individual clients. We follow a principled approach to address the above FRCS problems and develop a new federated learning method using the Shapley value concept from cooperative game theory. Towards this end, we propose a cooperative game involving the gradients shared by the clients. Using this game, we compute Shapley values of clients and then present Shapley value based Federated Averaging (S-FedAvg) algorithm that empowers the server to select relevant clients with high probability. S-FedAvg turns out to be critical in designing specific algorithms to address the FRCS problems. We finally conduct a thorough empirical analysis on image classification and speech recognition tasks to show the superior performance of S-FedAvg than the baselines in the context of supervised federated learning settings.
Data Quality Toolkit: Automatic assessment of data quality and remediation for machine learning datasets
Sep 05, 2021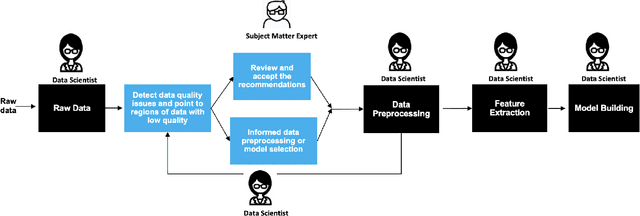

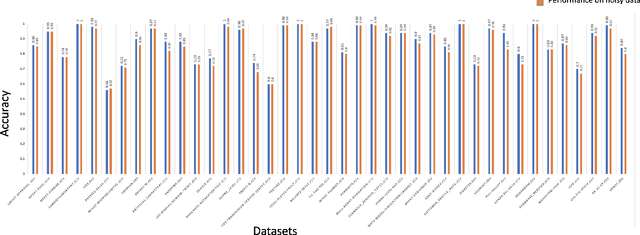
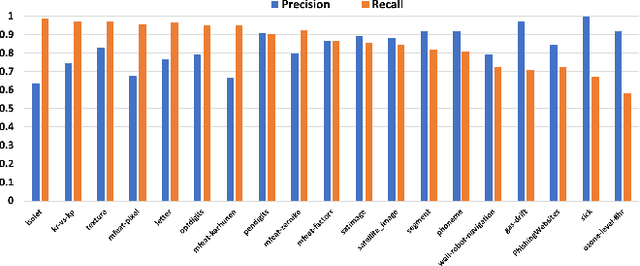
The quality of training data has a huge impact on the efficiency, accuracy and complexity of machine learning tasks. Various tools and techniques are available that assess data quality with respect to general cleaning and profiling checks. However these techniques are not applicable to detect data issues in the context of machine learning tasks, like noisy labels, existence of overlapping classes etc. We attempt to re-look at the data quality issues in the context of building a machine learning pipeline and build a tool that can detect, explain and remediate issues in the data, and systematically and automatically capture all the changes applied to the data. We introduce the Data Quality Toolkit for machine learning as a library of some key quality metrics and relevant remediation techniques to analyze and enhance the readiness of structured training datasets for machine learning projects. The toolkit can reduce the turn-around times of data preparation pipelines and streamline the data quality assessment process. Our toolkit is publicly available via IBM API Hub [1] platform, any developer can assess the data quality using the IBM's Data Quality for AI apis [2]. Detailed tutorials are also available on IBM Learning Path [3].
Data Augmentation for Personal Knowledge Graph Population
Feb 23, 2020


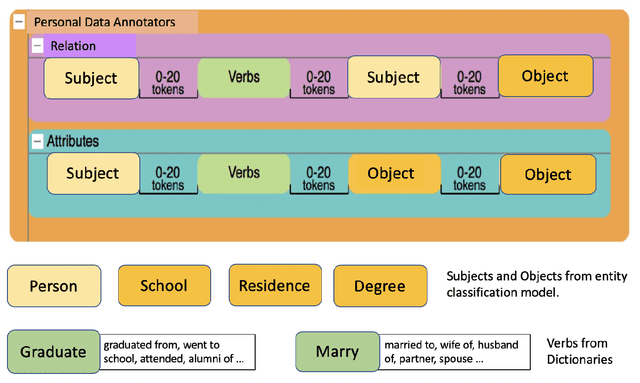
A personal knowledge graph comprising people as nodes, their personal data as node attributes, and their relationships as edges has a number of applications in de-identification, master data management, and fraud prevention. While artificial neural networks have led to significant improvements in different tasks in cold start knowledge graph population, the overall F1 of the system remains quite low. This problem is more acute in personal knowledge graph population which presents additional challenges with regard to data protection, fairness and privacy. In this work, we present a system that uses rule based annotators to augment training data for neural models, and for slot filling to increase the diversity of the populated knowledge graph. We also propose a representative set sampling method to use the populated knowledge graph data for downstream applications. We introduce new resources and discuss our results.