 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHaSaM: Submodular Hard Sample Mining for Fair Facial Attribute Recognition
Feb 05, 2026Deep neural networks often inherit social and demographic biases from annotated data during model training, leading to unfair predictions, especially in the presence of sensitive attributes like race, age, gender etc. Existing methods fall prey to the inherent data imbalance between attribute groups and inadvertently emphasize on sensitive attributes, worsening unfairness and performance. To surmount these challenges, we propose SHaSaM (Submodular Hard Sample Mining), a novel combinatorial approach that models fairness-driven representation learning as a submodular hard-sample mining problem. Our two-stage approach comprises of SHaSaM-MINE, which introduces a submodular subset selection strategy to mine hard positives and negatives - effectively mitigating data imbalance, and SHaSaM-LEARN, which introduces a family of combinatorial loss functions based on Submodular Conditional Mutual Information to maximize the decision boundary between target classes while minimizing the influence of sensitive attributes. This unified formulation restricts the model from learning features tied to sensitive attributes, significantly enhancing fairness without sacrificing performance. Experiments on CelebA and UTKFace demonstrate that SHaSaM achieves state-of-the-art results, with up to 2.7 points improvement in model fairness (Equalized Odds) and a 3.5% gain in Accuracy, within fewer epochs as compared to existing methods.
InSQuAD: In-Context Learning for Efficient Retrieval via Submodular Mutual Information to Enforce Quality and Diversity
Aug 28, 2025In this paper, we introduce InSQuAD, designed to enhance the performance of In-Context Learning (ICL) models through Submodular Mutual Information} (SMI) enforcing Quality and Diversity among in-context exemplars. InSQuAD achieves this through two principal strategies: First, we model the ICL task as a targeted selection problem and introduce a unified selection strategy based on SMIs which mines relevant yet diverse in-context examples encapsulating the notions of quality and diversity. Secondly, we address a common pitfall in existing retrieval models which model query relevance, often overlooking diversity, critical for ICL. InSQuAD introduces a combinatorial training paradigm which learns the parameters of an SMI function to enforce both quality and diversity in the retrieval model through a novel likelihood-based loss. To further aid the learning process we augment an existing multi-hop question answering dataset with synthetically generated paraphrases. Adopting the retrieval model trained using this strategy alongside the novel targeted selection formulation for ICL on nine benchmark datasets shows significant improvements validating the efficacy of our approach.
SMILe: Leveraging Submodular Mutual Information For Robust Few-Shot Object Detection
Jul 02, 2024Confusion and forgetting of object classes have been challenges of prime interest in Few-Shot Object Detection (FSOD). To overcome these pitfalls in metric learning based FSOD techniques, we introduce a novel Submodular Mutual Information Learning (SMILe) framework which adopts combinatorial mutual information functions to enforce the creation of tighter and discriminative feature clusters in FSOD. Our proposed approach generalizes to several existing approaches in FSOD, agnostic of the backbone architecture demonstrating elevated performance gains. A paradigm shift from instance based objective functions to combinatorial objectives in SMILe naturally preserves the diversity within an object class resulting in reduced forgetting when subjected to few training examples. Furthermore, the application of mutual information between the already learnt (base) and newly added (novel) objects ensures sufficient separation between base and novel classes, minimizing the effect of class confusion. Experiments on popular FSOD benchmarks, PASCAL-VOC and MS-COCO show that our approach generalizes to State-of-the-Art (SoTA) approaches improving their novel class performance by up to 5.7% (3.3 mAP points) and 5.4% (2.6 mAP points) on the 10-shot setting of VOC (split 3) and 30-shot setting of COCO datasets respectively. Our experiments also demonstrate better retention of base class performance and up to 2x faster convergence over existing approaches agnostic of the underlying architecture.
STENCIL: Submodular Mutual Information Based Weak Supervision for Cold-Start Active Learning
Feb 21, 2024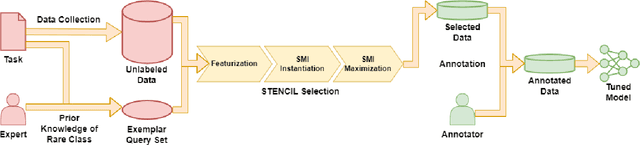

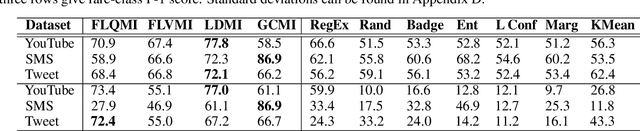
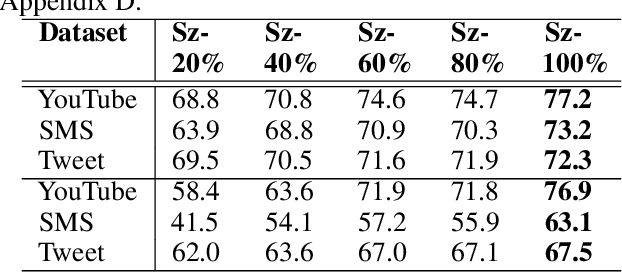
As supervised fine-tuning of pre-trained models within NLP applications increases in popularity, larger corpora of annotated data are required, especially with increasing parameter counts in large language models. Active learning, which attempts to mine and annotate unlabeled instances to improve model performance maximally fast, is a common choice for reducing the annotation cost; however, most methods typically ignore class imbalance and either assume access to initial annotated data or require multiple rounds of active learning selection before improving rare classes. We present STENCIL, which utilizes a set of text exemplars and the recently proposed submodular mutual information to select a set of weakly labeled rare-class instances that are then strongly labeled by an annotator. We show that STENCIL improves overall accuracy by $10\%-24\%$ and rare-class F-1 score by $17\%-40\%$ on multiple text classification datasets over common active learning methods within the class-imbalanced cold-start setting.
Theoretical Analysis of Submodular Information Measures for Targeted Data Subset Selection
Feb 21, 2024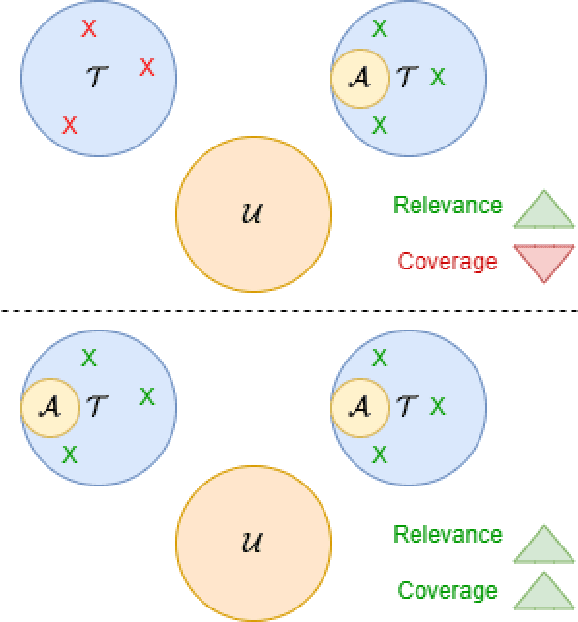
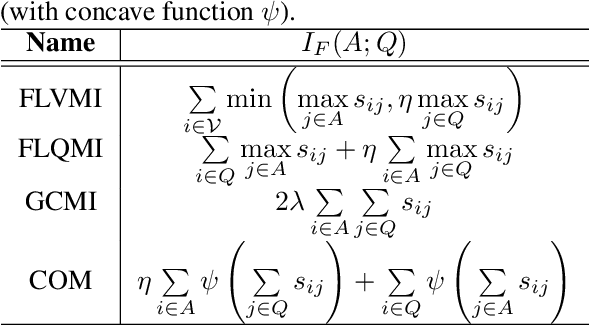
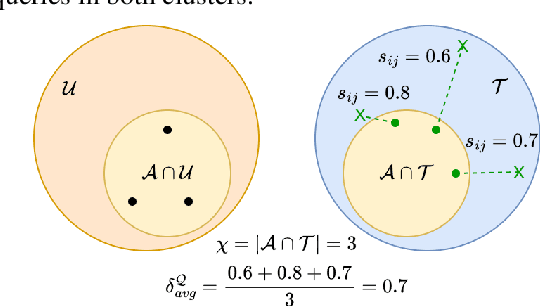
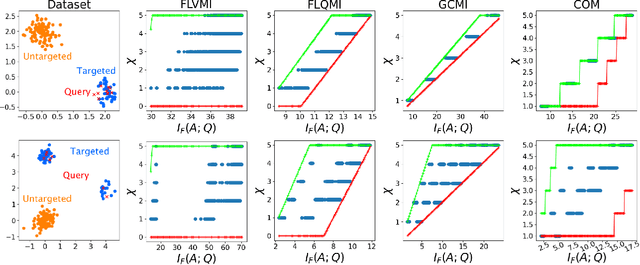
With increasing volume of data being used across machine learning tasks, the capability to target specific subsets of data becomes more important. To aid in this capability, the recently proposed Submodular Mutual Information (SMI) has been effectively applied across numerous tasks in literature to perform targeted subset selection with the aid of a exemplar query set. However, all such works are deficient in providing theoretical guarantees for SMI in terms of its sensitivity to a subset's relevance and coverage of the targeted data. For the first time, we provide such guarantees by deriving similarity-based bounds on quantities related to relevance and coverage of the targeted data. With these bounds, we show that the SMI functions, which have empirically shown success in multiple applications, are theoretically sound in achieving good query relevance and query coverage.
Gradient Coreset for Federated Learning
Jan 13, 2024Federated Learning (FL) is used to learn machine learning models with data that is partitioned across multiple clients, including resource-constrained edge devices. It is therefore important to devise solutions that are efficient in terms of compute, communication, and energy consumption, while ensuring compliance with the FL framework's privacy requirements. Conventional approaches to these problems select a weighted subset of the training dataset, known as coreset, and learn by fitting models on it. Such coreset selection approaches are also known to be robust to data noise. However, these approaches rely on the overall statistics of the training data and are not easily extendable to the FL setup. In this paper, we propose an algorithm called Gradient based Coreset for Robust and Efficient Federated Learning (GCFL) that selects a coreset at each client, only every $K$ communication rounds and derives updates only from it, assuming the availability of a small validation dataset at the server. We demonstrate that our coreset selection technique is highly effective in accounting for noise in clients' data. We conduct experiments using four real-world datasets and show that GCFL is (1) more compute and energy efficient than FL, (2) robust to various kinds of noise in both the feature space and labels, (3) preserves the privacy of the validation dataset, and (4) introduces a small communication overhead but achieves significant gains in performance, particularly in cases when the clients' data is noisy.
SCoRe: Submodular Combinatorial Representation Learning for Real-World Class-Imbalanced Settings
Sep 29, 2023



Representation Learning in real-world class-imbalanced settings has emerged as a challenging task in the evolution of deep learning. Lack of diversity in visual and structural features for rare classes restricts modern neural networks to learn discriminative feature clusters. This manifests in the form of large inter-class bias between rare object classes and elevated intra-class variance among abundant classes in the dataset. Although deep metric learning approaches have shown promise in this domain, significant improvements need to be made to overcome the challenges associated with class-imbalance in mission critical tasks like autonomous navigation and medical diagnostics. Set-based combinatorial functions like Submodular Information Measures exhibit properties that allow them to simultaneously model diversity and cooperation among feature clusters. In this paper, we introduce the SCoRe (Submodular Combinatorial Representation Learning) framework and propose a family of Submodular Combinatorial Loss functions to overcome these pitfalls in contrastive learning. We also show that existing contrastive learning approaches are either submodular or can be re-formulated to create their submodular counterparts. We conduct experiments on the newly introduced family of combinatorial objectives on two image classification benchmarks - pathologically imbalanced CIFAR-10, subsets of MedMNIST and a real-world road object detection benchmark - India Driving Dataset (IDD). Our experiments clearly show that the newly introduced objectives like Facility Location, Graph-Cut and Log Determinant outperform state-of-the-art metric learners by up to 7.6% for the imbalanced classification tasks and up to 19.4% for object detection tasks.
Beyond Active Learning: Leveraging the Full Potential of Human Interaction via Auto-Labeling, Human Correction, and Human Verification
Jun 02, 2023



Active Learning (AL) is a human-in-the-loop framework to interactively and adaptively label data instances, thereby enabling significant gains in model performance compared to random sampling. AL approaches function by selecting the hardest instances to label, often relying on notions of diversity and uncertainty. However, we believe that these current paradigms of AL do not leverage the full potential of human interaction granted by automated label suggestions. Indeed, we show that for many classification tasks and datasets, most people verifying if an automatically suggested label is correct take $3\times$ to $4\times$ less time than they do changing an incorrect suggestion to the correct label (or labeling from scratch without any suggestion). Utilizing this result, we propose CLARIFIER (aCtive LeARnIng From tIEred haRdness), an Interactive Learning framework that admits more effective use of human interaction by leveraging the reduced cost of verification. By targeting the hard (uncertain) instances with existing AL methods, the intermediate instances with a novel label suggestion scheme using submodular mutual information functions on a per-class basis, and the easy (confident) instances with highest-confidence auto-labeling, CLARIFIER can improve over the performance of existing AL approaches on multiple datasets -- particularly on those that have a large number of classes -- by almost 1.5$\times$ to 2$\times$ in terms of relative labeling cost.
STREAMLINE: Streaming Active Learning for Realistic Multi-Distributional Settings
May 18, 2023



Deep neural networks have consistently shown great performance in several real-world use cases like autonomous vehicles, satellite imaging, etc., effectively leveraging large corpora of labeled training data. However, learning unbiased models depends on building a dataset that is representative of a diverse range of realistic scenarios for a given task. This is challenging in many settings where data comes from high-volume streams, with each scenario occurring in random interleaved episodes at varying frequencies. We study realistic streaming settings where data instances arrive in and are sampled from an episodic multi-distributional data stream. Using submodular information measures, we propose STREAMLINE, a novel streaming active learning framework that mitigates scenario-driven slice imbalance in the working labeled data via a three-step procedure of slice identification, slice-aware budgeting, and data selection. We extensively evaluate STREAMLINE on real-world streaming scenarios for image classification and object detection tasks. We observe that STREAMLINE improves the performance on infrequent yet critical slices of the data over current baselines by up to $5\%$ in terms of accuracy on our image classification tasks and by up to $8\%$ in terms of mAP on our object detection tasks.
INGENIOUS: Using Informative Data Subsets for Efficient Pre-Training of Large Language Models
May 11, 2023
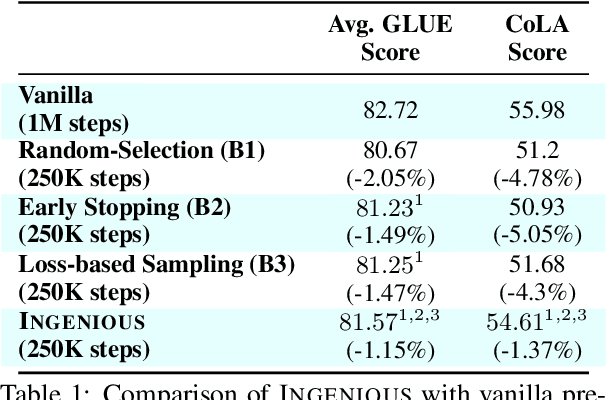

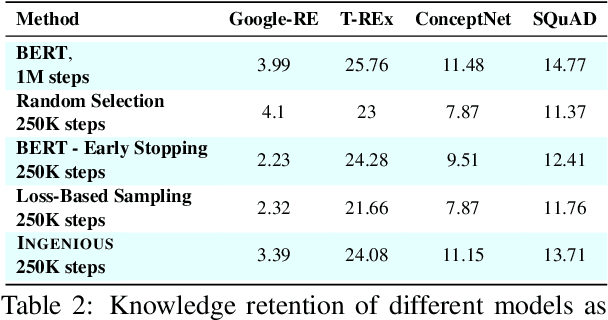
A salient characteristic of large pre-trained language models (PTLMs) is a remarkable improvement in their generalization capability and emergence of new capabilities with increasing model capacity and pre-training dataset size. Consequently, we are witnessing the development of enormous models pushing the state-of-the-art. It is, however, imperative to realize that this inevitably leads to prohibitively long training times, extortionate computing costs, and a detrimental environmental impact. Significant efforts are underway to make PTLM training more efficient through innovations in model architectures, training pipelines, and loss function design, with scant attention being paid to optimizing the utility of training data. The key question that we ask is whether it is possible to train PTLMs by employing only highly informative subsets of the training data while maintaining downstream performance? Building upon the recent progress in informative data subset selection, we show how we can employ submodular optimization to select highly representative subsets of the training corpora. Our results demonstrate that the proposed framework can be applied to efficiently train multiple PTLMs (BERT, BioBERT, GPT-2) using only a fraction of data while retaining up to $\sim99\%$ of the performance of the fully-trained models.