 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Model Routing for Efficient LLM Inference
Feb 12, 2025



Large language models' significant advances in capabilities are accompanied by significant increases in inference costs. Model routing is a simple technique for reducing inference cost, wherein one maintains a pool of candidate LLMs, and learns to route each prompt to the smallest feasible LLM. Existing works focus on learning a router for a fixed pool of LLMs. In this paper, we consider the problem of dynamic routing, where new, previously unobserved LLMs are available at test time. We propose a new approach to this problem that relies on representing each LLM as a feature vector, derived based on predictions on a set of representative prompts. Based on this, we detail two effective strategies, relying on cluster-based routing and a learned cluster map respectively. We prove that these strategies are estimates of a theoretically optimal routing rule, and provide an excess risk bound to quantify their errors. Experiments on a range of public benchmarks show the effectiveness of the proposed strategies in routing amongst more than 30 unseen LLMs.
OLAF: A Plug-and-Play Framework for Enhanced Multi-object Multi-part Scene Parsing
Nov 05, 2024Multi-object multi-part scene segmentation is a challenging task whose complexity scales exponentially with part granularity and number of scene objects. To address the task, we propose a plug-and-play approach termed OLAF. First, we augment the input (RGB) with channels containing object-based structural cues (fg/bg mask, boundary edge mask). We propose a weight adaptation technique which enables regular (RGB) pre-trained models to process the augmented (5-channel) input in a stable manner during optimization. In addition, we introduce an encoder module termed LDF to provide low-level dense feature guidance. This assists segmentation, particularly for smaller parts. OLAF enables significant mIoU gains of $\mathbf{3.3}$ (Pascal-Parts-58), $\mathbf{3.5}$ (Pascal-Parts-108) over the SOTA model. On the most challenging variant (Pascal-Parts-201), the gain is $\mathbf{4.0}$. Experimentally, we show that OLAF's broad applicability enables gains across multiple architectures (CNN, U-Net, Transformer) and datasets. The code is available at olafseg.github.io
Improving Generalization via Meta-Learning on Hard Samples
Mar 29, 2024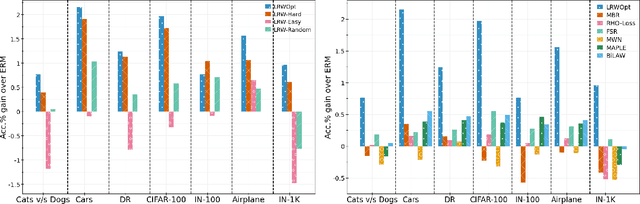

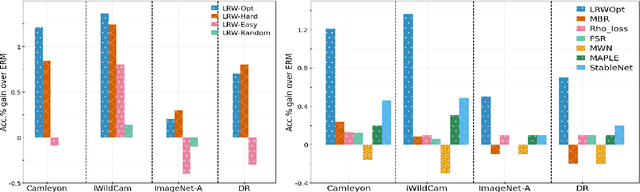
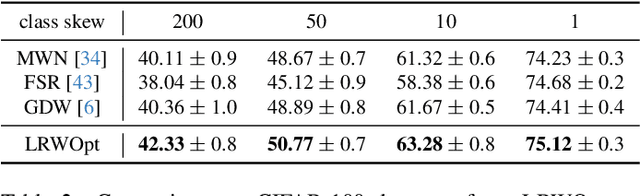
Learned reweighting (LRW) approaches to supervised learning use an optimization criterion to assign weights for training instances, in order to maximize performance on a representative validation dataset. We pose and formalize the problem of optimized selection of the validation set used in LRW training, to improve classifier generalization. In particular, we show that using hard-to-classify instances in the validation set has both a theoretical connection to, and strong empirical evidence of generalization. We provide an efficient algorithm for training this meta-optimized model, as well as a simple train-twice heuristic for careful comparative study. We demonstrate that LRW with easy validation data performs consistently worse than LRW with hard validation data, establishing the validity of our meta-optimization problem. Our proposed algorithm outperforms a wide range of baselines on a range of datasets and domain shift challenges (Imagenet-1K, CIFAR-100, Clothing-1M, CAMELYON, WILDS, etc.), with ~1% gains using VIT-B on Imagenet. We also show that using naturally hard examples for validation (Imagenet-R / Imagenet-A) in LRW training for Imagenet improves performance on both clean and naturally hard test instances by 1-2%. Secondary analyses show that using hard validation data in an LRW framework improves margins on test data, hinting at the mechanism underlying our empirical gains. We believe this work opens up new research directions for the meta-optimization of meta-learning in a supervised learning context.
Rescuing referral failures during automated diagnosis of domain-shifted medical images
Nov 28, 2023



The success of deep learning models deployed in the real world depends critically on their ability to generalize well across diverse data domains. Here, we address a fundamental challenge with selective classification during automated diagnosis with domain-shifted medical images. In this scenario, models must learn to avoid making predictions when label confidence is low, especially when tested with samples far removed from the training set (covariate shift). Such uncertain cases are typically referred to the clinician for further analysis and evaluation. Yet, we show that even state-of-the-art domain generalization approaches fail severely during referral when tested on medical images acquired from a different demographic or using a different technology. We examine two benchmark diagnostic medical imaging datasets exhibiting strong covariate shifts: i) diabetic retinopathy prediction with retinal fundus images and ii) multilabel disease prediction with chest X-ray images. We show that predictive uncertainty estimates do not generalize well under covariate shifts leading to non-monotonic referral curves, and severe drops in performance (up to 50%) at high referral rates (>70%). We evaluate novel combinations of robust generalization and post hoc referral approaches, that rescue these failures and achieve significant performance improvements, typically >10%, over baseline methods. Our study identifies a critical challenge with referral in domain-shifted medical images and finds key applications in reliable, automated disease diagnosis.
Using Early Readouts to Mediate Featural Bias in Distillation
Oct 28, 2023Deep networks tend to learn spurious feature-label correlations in real-world supervised learning tasks. This vulnerability is aggravated in distillation, where a student model may have lesser representational capacity than the corresponding teacher model. Often, knowledge of specific spurious correlations is used to reweight instances & rebalance the learning process. We propose a novel early readout mechanism whereby we attempt to predict the label using representations from earlier network layers. We show that these early readouts automatically identify problem instances or groups in the form of confident, incorrect predictions. Leveraging these signals to modulate the distillation loss on an instance level allows us to substantially improve not only group fairness measures across benchmark datasets, but also overall accuracy of the student model. We also provide secondary analyses that bring insight into the role of feature learning in supervision and distillation.
STREAMLINE: Streaming Active Learning for Realistic Multi-Distributional Settings
May 18, 2023



Deep neural networks have consistently shown great performance in several real-world use cases like autonomous vehicles, satellite imaging, etc., effectively leveraging large corpora of labeled training data. However, learning unbiased models depends on building a dataset that is representative of a diverse range of realistic scenarios for a given task. This is challenging in many settings where data comes from high-volume streams, with each scenario occurring in random interleaved episodes at varying frequencies. We study realistic streaming settings where data instances arrive in and are sampled from an episodic multi-distributional data stream. Using submodular information measures, we propose STREAMLINE, a novel streaming active learning framework that mitigates scenario-driven slice imbalance in the working labeled data via a three-step procedure of slice identification, slice-aware budgeting, and data selection. We extensively evaluate STREAMLINE on real-world streaming scenarios for image classification and object detection tasks. We observe that STREAMLINE improves the performance on infrequent yet critical slices of the data over current baselines by up to $5\%$ in terms of accuracy on our image classification tasks and by up to $8\%$ in terms of mAP on our object detection tasks.
An adversarial feature learning strategy for debiasing neural networks
Feb 02, 2023



Simplicity bias is the concerning tendency of deep networks to over-depend on simple, weakly predictive features, to the exclusion of stronger, more complex features. This causes biased, incorrect model predictions in many real-world applications, exacerbated by incomplete training data containing spurious feature-label correlations. We propose a direct, interventional method for addressing simplicity bias in DNNs, which we call the feature sieve. We aim to automatically identify and suppress easily-computable spurious features in lower layers of the network, thereby allowing the higher network levels to extract and utilize richer, more meaningful representations. We provide concrete evidence of this differential suppression & enhancement of relevant features on both controlled datasets and real-world images, and report substantial gains on many real-world debiasing benchmarks (11.4% relative gain on Imagenet-A; 3.2% on BAR, etc). Crucially, we outperform many baselines that incorporate knowledge about known spurious or biased attributes, despite our method not using any such information. We believe that our feature sieve work opens up exciting new research directions in automated adversarial feature extraction & representation learning for deep networks.
Interactive Concept Bottleneck Models
Dec 26, 2022



Concept bottleneck models (CBMs) (Koh et al. 2020) are interpretable neural networks that first predict labels for human-interpretable concepts relevant to the prediction task, and then predict the final label based on the concept label predictions.We extend CBMs to interactive prediction settings where the model can query a human collaborator for the label to some concepts. We develop an interaction policy that, at prediction time, chooses which concepts to request a label for so as to maximally improve the final prediction. We demonstrate thata simple policy combining concept prediction uncertainty and influence of the concept on the final prediction achieves strong performance and outperforms a static approach proposed in Koh et al. (2020) as well as active feature acquisition methods proposed in the literature. We show that the interactiveCBM can achieve accuracy gains of 5-10% with only 5 interactions over competitive baselines on the Caltech-UCSDBirds, CheXpert and OAI datasets.
Selective classification using a robust meta-learning approach
Dec 12, 2022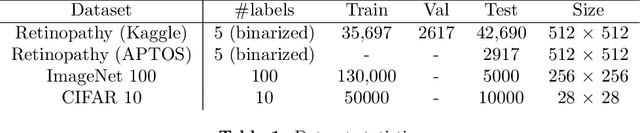
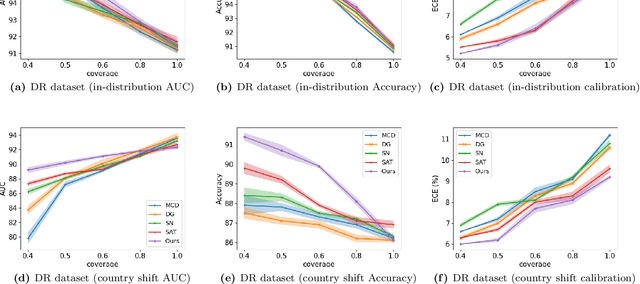
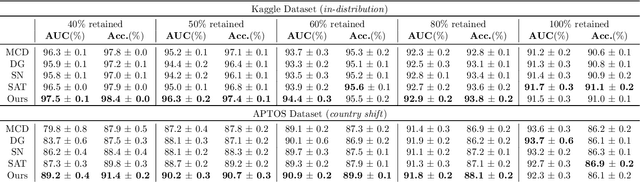
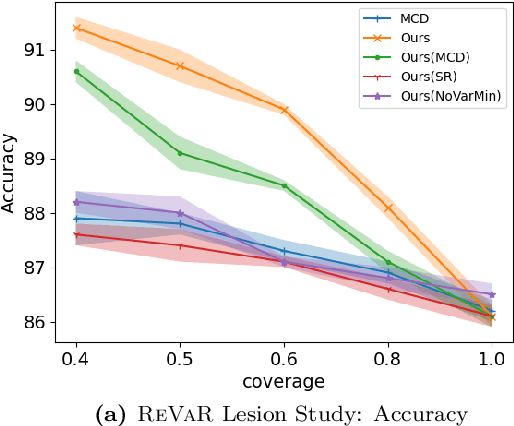
Selective classification involves identifying the subset of test samples that a model can classify with high accuracy, and is important for applications such as automated medical diagnosis. We argue that this capability of identifying uncertain samples is valuable for training classifiers as well, with the aim of building more accurate classifiers. We unify these dual roles by training a single auxiliary meta-network to output an importance weight as a function of the instance. This measure is used at train time to reweight training data, and at test-time to rank test instances for selective classification. A second, key component of our proposal is the meta-objective of minimizing dropout variance (the variance of classifier output when subjected to random weight dropout) for training the metanetwork. We train the classifier together with its metanetwork using a nested objective of minimizing classifier loss on training data and meta-loss on a separate meta-training dataset. We outperform current state-of-the-art on selective classification by substantial margins--for instance, upto 1.9% AUC and 2% accuracy on a real-world diabetic retinopathy dataset. Finally, our meta-learning framework extends naturally to unsupervised domain adaptation, given our unsupervised variance minimization meta-objective. We show cumulative absolute gains of 3.4% / 3.3% accuracy and AUC over the other baselines in domain shift settings on the Retinopathy dataset using unsupervised domain adaptation.
Learning on non-stationary data with re-weighting
Dec 12, 2022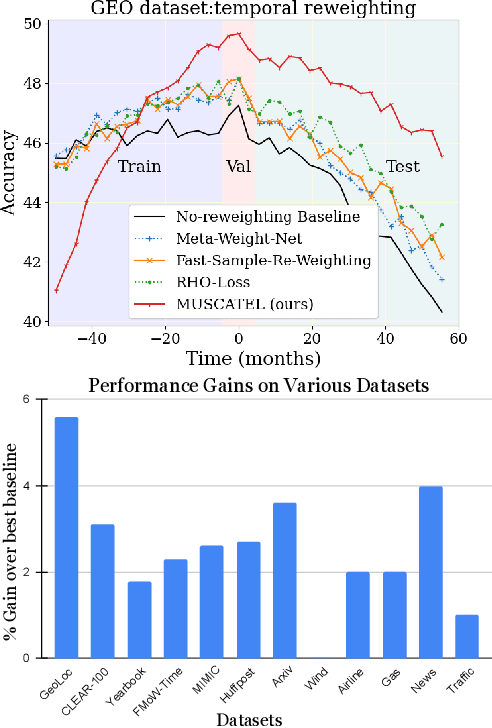
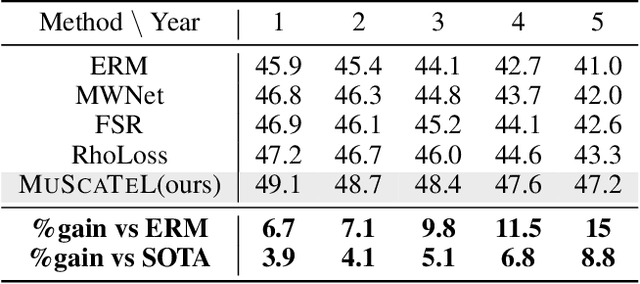
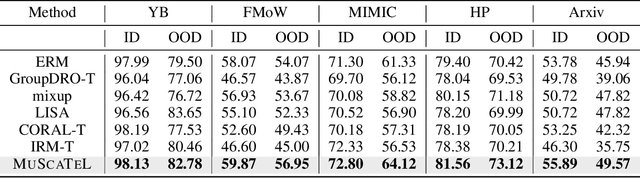
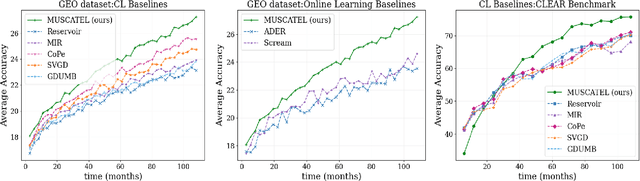
Many real-world learning scenarios face the challenge of slow concept drift, where data distributions change gradually over time. In this setting, we pose the problem of learning temporally sensitive importance weights for training data, in order to optimize predictive accuracy. We propose a class of temporal reweighting functions that can capture multiple timescales of change in the data, as well as instance-specific characteristics. We formulate a bi-level optimization criterion, and an associated meta-learning algorithm, by which these weights can be learned. In particular, our formulation trains an auxiliary network to output weights as a function of training instances, thereby compactly representing the instance weights. We validate our temporal reweighting scheme on a large real-world dataset of 39M images spread over a 9 year period. Our extensive experiments demonstrate the necessity of instance-based temporal reweighting in the dataset, and achieve significant improvements to classical batch-learning approaches. Further, our proposal easily generalizes to a streaming setting and shows significant gains compared to recent continual learning methods.