 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's (not) just put things in Context: Test-Time Training for Long-Context LLMs
Dec 15, 2025Progress on training and architecture strategies has enabled LLMs with millions of tokens in context length. However, empirical evidence suggests that such long-context LLMs can consume far more text than they can reliably use. On the other hand, it has been shown that inference-time compute can be used to scale performance of LLMs, often by generating thinking tokens, on challenging tasks involving multi-step reasoning. Through controlled experiments on sandbox long-context tasks, we find that such inference-time strategies show rapidly diminishing returns and fail at long context. We attribute these failures to score dilution, a phenomenon inherent to static self-attention. Further, we show that current inference-time strategies cannot retrieve relevant long-context signals under certain conditions. We propose a simple method that, through targeted gradient updates on the given context, provably overcomes limitations of static self-attention. We find that this shift in how inference-time compute is spent leads to consistently large performance improvements across models and long-context benchmarks. Our method leads to large 12.6 and 14.1 percentage point improvements for Qwen3-4B on average across subsets of LongBench-v2 and ZeroScrolls benchmarks. The takeaway is practical: for long context, a small amount of context-specific training is a better use of inference compute than current inference-time scaling strategies like producing more thinking tokens.
XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization
Aug 14, 2025Although LLM inference has emerged as a critical workload for many downstream applications, efficiently inferring LLMs is challenging due to the substantial memory footprint and bandwidth requirements. In parallel, compute capabilities have steadily outpaced both memory capacity and bandwidth over the last few decades, a trend that remains evident in modern GPU hardware and exacerbates the challenge of LLM inference. As such, new algorithms are emerging that trade increased computation for reduced memory operations. To that end, we present XQuant, which takes advantage of this trend, enabling an order-of-magnitude reduction in memory consumption through low-bit quantization with substantial accuracy benefits relative to state-of-the-art KV cache quantization methods. We accomplish this by quantizing and caching the layer input activations X, instead of using standard KV caching, and then rematerializing the Keys and Values on-the-fly during inference. This results in an immediate 2$\times$ memory savings compared to KV caching. By applying XQuant, we achieve up to $\sim 7.7\times$ memory savings with $<0.1$ perplexity degradation compared to the FP16 baseline. Furthermore, our approach leverages the fact that X values are similar across layers. Building on this observation, we introduce XQuant-CL, which exploits the cross-layer similarity in the X embeddings for extreme compression. Across different models, XQuant-CL attains up to 10$\times$ memory savings relative to the FP16 baseline with only 0.01 perplexity degradation, and 12.5$\times$ memory savings with only $0.1$ perplexity degradation. XQuant exploits the rapidly increasing compute capabilities of hardware platforms to eliminate the memory bottleneck, while surpassing state-of-the-art KV cache quantization methods and achieving near-FP16 accuracy across a wide range of models.
Why Do Multi-Agent LLM Systems Fail?
Mar 17, 2025Despite growing enthusiasm for Multi-Agent Systems (MAS), where multiple LLM agents collaborate to accomplish tasks, their performance gains across popular benchmarks remain minimal compared to single-agent frameworks. This gap highlights the need to analyze the challenges hindering MAS effectiveness. In this paper, we present the first comprehensive study of MAS challenges. We analyze five popular MAS frameworks across over 150 tasks, involving six expert human annotators. We identify 14 unique failure modes and propose a comprehensive taxonomy applicable to various MAS frameworks. This taxonomy emerges iteratively from agreements among three expert annotators per study, achieving a Cohen's Kappa score of 0.88. These fine-grained failure modes are organized into 3 categories, (i) specification and system design failures, (ii) inter-agent misalignment, and (iii) task verification and termination. To support scalable evaluation, we integrate MASFT with LLM-as-a-Judge. We also explore if identified failures could be easily prevented by proposing two interventions: improved specification of agent roles and enhanced orchestration strategies. Our findings reveal that identified failures require more complex solutions, highlighting a clear roadmap for future research. We open-source our dataset and LLM annotator.
Using Early Readouts to Mediate Featural Bias in Distillation
Oct 28, 2023Deep networks tend to learn spurious feature-label correlations in real-world supervised learning tasks. This vulnerability is aggravated in distillation, where a student model may have lesser representational capacity than the corresponding teacher model. Often, knowledge of specific spurious correlations is used to reweight instances & rebalance the learning process. We propose a novel early readout mechanism whereby we attempt to predict the label using representations from earlier network layers. We show that these early readouts automatically identify problem instances or groups in the form of confident, incorrect predictions. Leveraging these signals to modulate the distillation loss on an instance level allows us to substantially improve not only group fairness measures across benchmark datasets, but also overall accuracy of the student model. We also provide secondary analyses that bring insight into the role of feature learning in supervision and distillation.
An adversarial feature learning strategy for debiasing neural networks
Feb 02, 2023



Simplicity bias is the concerning tendency of deep networks to over-depend on simple, weakly predictive features, to the exclusion of stronger, more complex features. This causes biased, incorrect model predictions in many real-world applications, exacerbated by incomplete training data containing spurious feature-label correlations. We propose a direct, interventional method for addressing simplicity bias in DNNs, which we call the feature sieve. We aim to automatically identify and suppress easily-computable spurious features in lower layers of the network, thereby allowing the higher network levels to extract and utilize richer, more meaningful representations. We provide concrete evidence of this differential suppression & enhancement of relevant features on both controlled datasets and real-world images, and report substantial gains on many real-world debiasing benchmarks (11.4% relative gain on Imagenet-A; 3.2% on BAR, etc). Crucially, we outperform many baselines that incorporate knowledge about known spurious or biased attributes, despite our method not using any such information. We believe that our feature sieve work opens up exciting new research directions in automated adversarial feature extraction & representation learning for deep networks.
Interactive Concept Bottleneck Models
Dec 26, 2022



Concept bottleneck models (CBMs) (Koh et al. 2020) are interpretable neural networks that first predict labels for human-interpretable concepts relevant to the prediction task, and then predict the final label based on the concept label predictions.We extend CBMs to interactive prediction settings where the model can query a human collaborator for the label to some concepts. We develop an interaction policy that, at prediction time, chooses which concepts to request a label for so as to maximally improve the final prediction. We demonstrate thata simple policy combining concept prediction uncertainty and influence of the concept on the final prediction achieves strong performance and outperforms a static approach proposed in Koh et al. (2020) as well as active feature acquisition methods proposed in the literature. We show that the interactiveCBM can achieve accuracy gains of 5-10% with only 5 interactions over competitive baselines on the Caltech-UCSDBirds, CheXpert and OAI datasets.
On designing light-weight object trackers through network pruning: Use CNNs or transformers?
Nov 24, 2022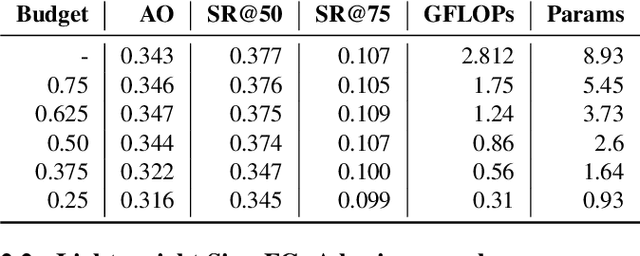
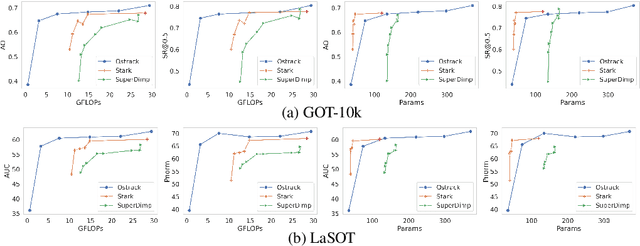


Object trackers deployed on low-power devices need to be light-weight, however, most of the current state-of-the-art (SOTA) methods rely on using compute-heavy backbones built using CNNs or transformers. Large sizes of such models do not allow their deployment in low-power conditions and designing compressed variants of large tracking models is of great importance. This paper demonstrates how highly compressed light-weight object trackers can be designed using neural architectural pruning of large CNN and transformer based trackers. Further, a comparative study on architectural choices best suited to design light-weight trackers is provided. A comparison between SOTA trackers using CNNs, transformers as well as the combination of the two is presented to study their stability at various compression ratios. Finally results for extreme pruning scenarios going as low as 1% in some cases are shown to study the limits of network pruning in object tracking. This work provides deeper insights into designing highly efficient trackers from existing SOTA methods.
Dynamic Kernel Selection for Improved Generalization and Memory Efficiency in Meta-learning
Jun 03, 2022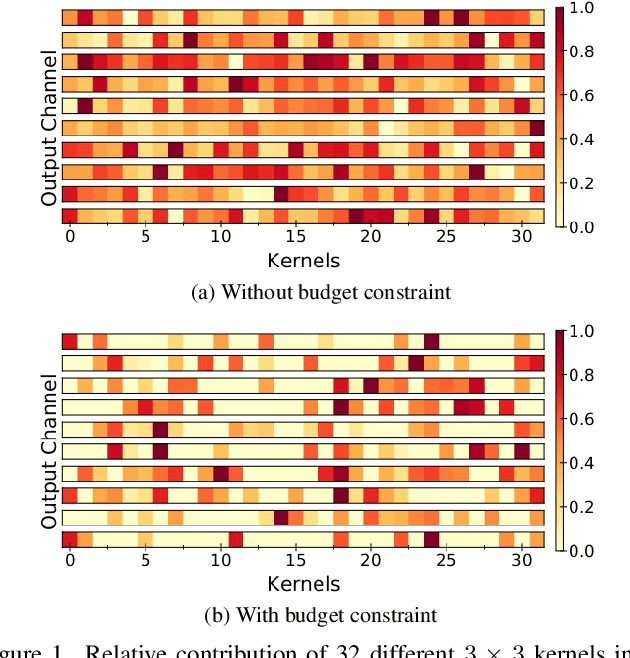
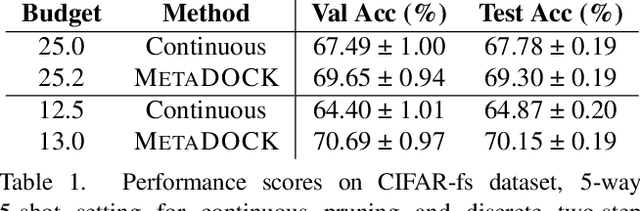
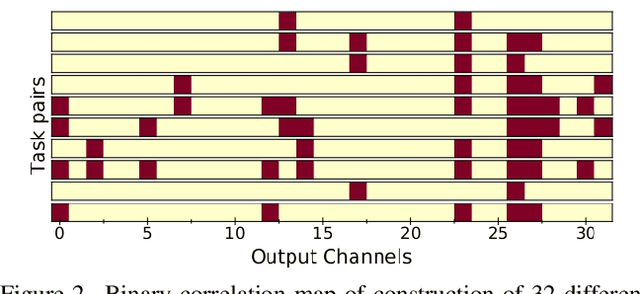
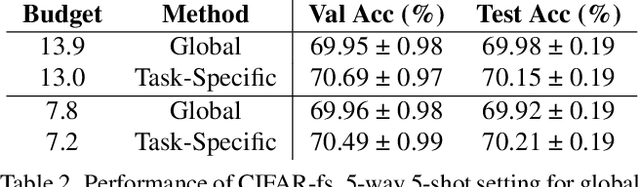
Gradient based meta-learning methods are prone to overfit on the meta-training set, and this behaviour is more prominent with large and complex networks. Moreover, large networks restrict the application of meta-learning models on low-power edge devices. While choosing smaller networks avoid these issues to a certain extent, it affects the overall generalization leading to reduced performance. Clearly, there is an approximately optimal choice of network architecture that is best suited for every meta-learning problem, however, identifying it beforehand is not straightforward. In this paper, we present MetaDOCK, a task-specific dynamic kernel selection strategy for designing compressed CNN models that generalize well on unseen tasks in meta-learning. Our method is based on the hypothesis that for a given set of similar tasks, not all kernels of the network are needed by each individual task. Rather, each task uses only a fraction of the kernels, and the selection of the kernels per task can be learnt dynamically as a part of the inner update steps. MetaDOCK compresses the meta-model as well as the task-specific inner models, thus providing significant reduction in model size for each task, and through constraining the number of active kernels for every task, it implicitly mitigates the issue of meta-overfitting. We show that for the same inference budget, pruned versions of large CNN models obtained using our approach consistently outperform the conventional choices of CNN models. MetaDOCK couples well with popular meta-learning approaches such as iMAML. The efficacy of our method is validated on CIFAR-fs and mini-ImageNet datasets, and we have observed that our approach can provide improvements in model accuracy of up to 2% on standard meta-learning benchmark, while reducing the model size by more than 75%.
GCR: Gradient Coreset Based Replay Buffer Selection For Continual Learning
Nov 18, 2021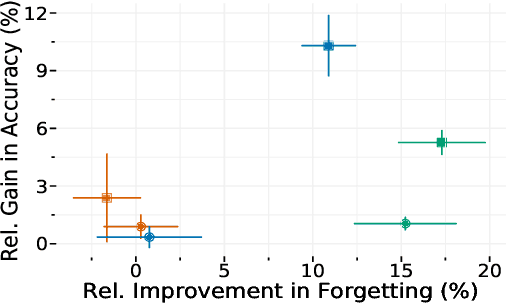
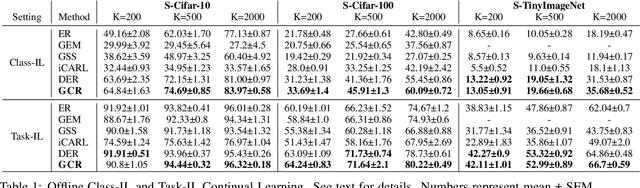
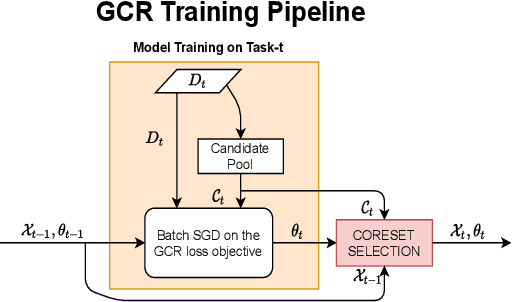

Continual learning (CL) aims to develop techniques by which a single model adapts to an increasing number of tasks encountered sequentially, thereby potentially leveraging learnings across tasks in a resource-efficient manner. A major challenge for CL systems is catastrophic forgetting, where earlier tasks are forgotten while learning a new task. To address this, replay-based CL approaches maintain and repeatedly retrain on a small buffer of data selected across encountered tasks. We propose Gradient Coreset Replay (GCR), a novel strategy for replay buffer selection and update using a carefully designed optimization criterion. Specifically, we select and maintain a "coreset" that closely approximates the gradient of all the data seen so far with respect to current model parameters, and discuss key strategies needed for its effective application to the continual learning setting. We show significant gains (2%-4% absolute) over the state-of-the-art in the well-studied offline continual learning setting. Our findings also effectively transfer to online / streaming CL settings, showing upto 5% gains over existing approaches. Finally, we demonstrate the value of supervised contrastive loss for continual learning, which yields a cumulative gain of up to 5% accuracy when combined with our subset selection strategy.
ChipNet: Budget-Aware Pruning with Heaviside Continuous Approximations
Feb 14, 2021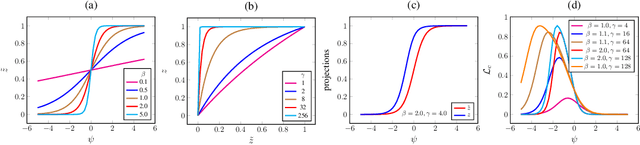
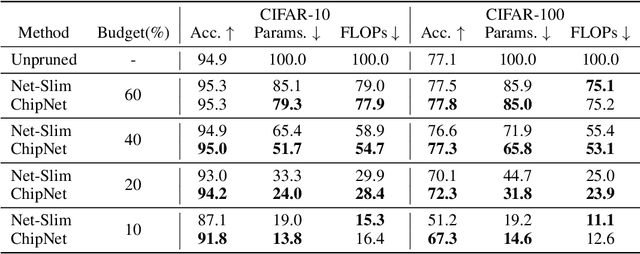
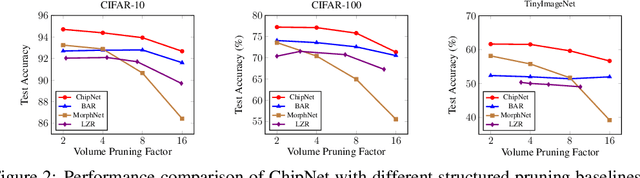
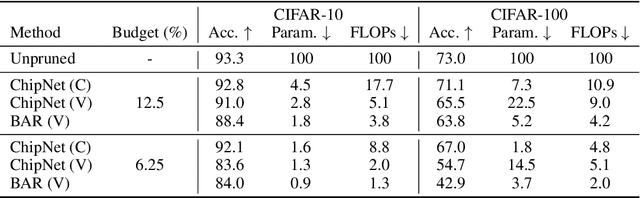
Structured pruning methods are among the effective strategies for extracting small resource-efficient convolutional neural networks from their dense counterparts with minimal loss in accuracy. However, most existing methods still suffer from one or more limitations, that include 1) the need for training the dense model from scratch with pruning-related parameters embedded in the architecture, 2) requiring model-specific hyperparameter settings, 3) inability to include budget-related constraint in the training process, and 4) instability under scenarios of extreme pruning. In this paper, we present ChipNet, a deterministic pruning strategy that employs continuous Heaviside function and a novel crispness loss to identify a highly sparse network out of an existing dense network. Our choice of continuous Heaviside function is inspired by the field of design optimization, where the material distribution task is posed as a continuous optimization problem, but only discrete values (0 or 1) are practically feasible and expected as final outcomes. Our approach's flexible design facilitates its use with different choices of budget constraints while maintaining stability for very low target budgets. Experimental results show that ChipNet outperforms state-of-the-art structured pruning methods by remarkable margins of up to 16.1% in terms of accuracy. Further, we show that the masks obtained with ChipNet are transferable across datasets. For certain cases, it was observed that masks transferred from a model trained on feature-rich teacher dataset provide better performance on the student dataset than those obtained by directly pruning on the student data itself.