 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCR: Gradient Coreset Based Replay Buffer Selection For Continual Learning
Paper and Code
Nov 18, 2021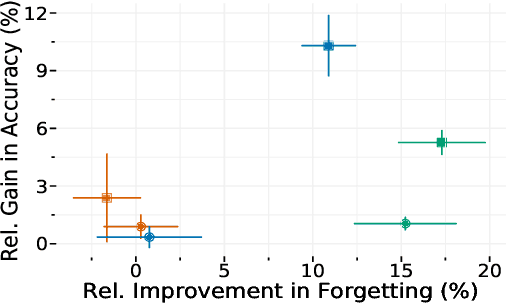
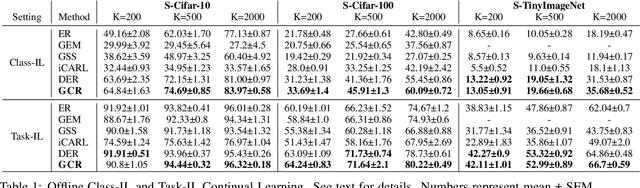
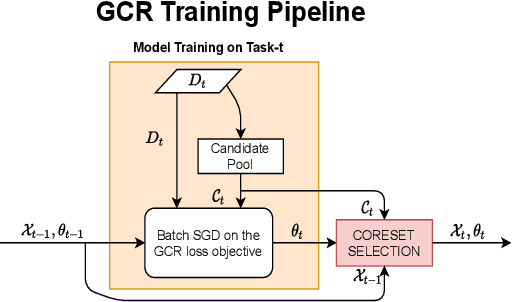

Continual learning (CL) aims to develop techniques by which a single model adapts to an increasing number of tasks encountered sequentially, thereby potentially leveraging learnings across tasks in a resource-efficient manner. A major challenge for CL systems is catastrophic forgetting, where earlier tasks are forgotten while learning a new task. To address this, replay-based CL approaches maintain and repeatedly retrain on a small buffer of data selected across encountered tasks. We propose Gradient Coreset Replay (GCR), a novel strategy for replay buffer selection and update using a carefully designed optimization criterion. Specifically, we select and maintain a "coreset" that closely approximates the gradient of all the data seen so far with respect to current model parameters, and discuss key strategies needed for its effective application to the continual learning setting. We show significant gains (2%-4% absolute) over the state-of-the-art in the well-studied offline continual learning setting. Our findings also effectively transfer to online / streaming CL settings, showing upto 5% gains over existing approaches. Finally, we demonstrate the value of supervised contrastive loss for continual learning, which yields a cumulative gain of up to 5% accuracy when combined with our subset selection strategy.