 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Library of LLM Intrinsics for Retrieval-Augmented Generation
Apr 16, 2025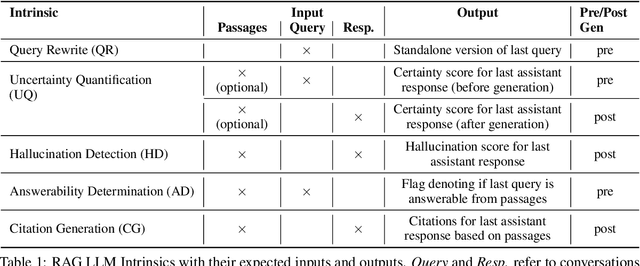
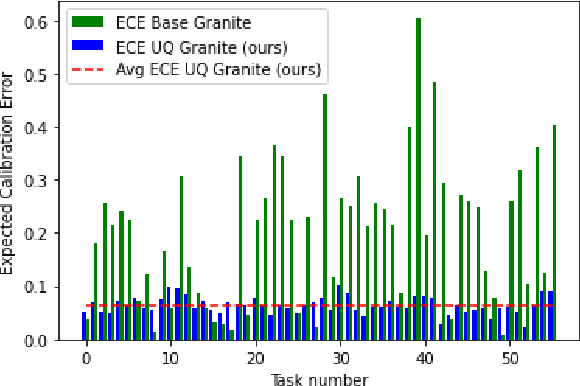

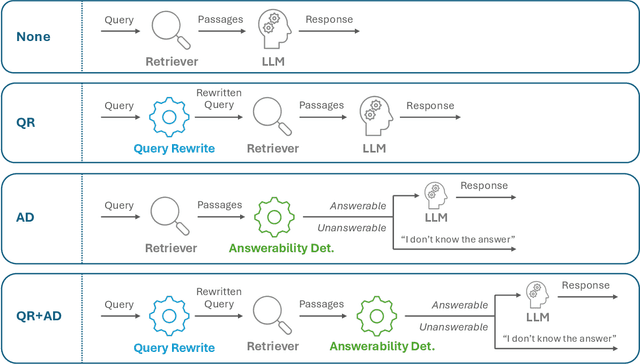
In the developer community for large language models (LLMs), there is not yet a clean pattern analogous to a software library, to support very large scale collaboration. Even for the commonplace use case of Retrieval-Augmented Generation (RAG), it is not currently possible to write a RAG application against a well-defined set of APIs that are agreed upon by different LLM providers. Inspired by the idea of compiler intrinsics, we propose some elements of such a concept through introducing a library of LLM Intrinsics for RAG. An LLM intrinsic is defined as a capability that can be invoked through a well-defined API that is reasonably stable and independent of how the LLM intrinsic itself is implemented. The intrinsics in our library are released as LoRA adapters on HuggingFace, and through a software interface with clear structured input/output characteristics on top of vLLM as an inference platform, accompanied in both places with documentation and code. This article describes the intended usage, training details, and evaluations for each intrinsic, as well as compositions of multiple intrinsics.
Sculpting Subspaces: Constrained Full Fine-Tuning in LLMs for Continual Learning
Apr 09, 2025Continual learning in large language models (LLMs) is prone to catastrophic forgetting, where adapting to new tasks significantly degrades performance on previously learned ones. Existing methods typically rely on low-rank, parameter-efficient updates that limit the model's expressivity and introduce additional parameters per task, leading to scalability issues. To address these limitations, we propose a novel continual full fine-tuning approach leveraging adaptive singular value decomposition (SVD). Our method dynamically identifies task-specific low-rank parameter subspaces and constrains updates to be orthogonal to critical directions associated with prior tasks, thus effectively minimizing interference without additional parameter overhead or storing previous task gradients. We evaluate our approach extensively on standard continual learning benchmarks using both encoder-decoder (T5-Large) and decoder-only (LLaMA-2 7B) models, spanning diverse tasks including classification, generation, and reasoning. Empirically, our method achieves state-of-the-art results, up to 7% higher average accuracy than recent baselines like O-LoRA, and notably maintains the model's general linguistic capabilities, instruction-following accuracy, and safety throughout the continual learning process by reducing forgetting to near-negligible levels. Our adaptive SVD framework effectively balances model plasticity and knowledge retention, providing a practical, theoretically grounded, and computationally scalable solution for continual learning scenarios in large language models.
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
Dec 17, 2024The rise of large language models (LLMs) has created a significant disparity: industrial research labs with their computational resources, expert teams, and advanced infrastructures, can effectively fine-tune LLMs, while individual developers and small organizations face barriers due to limited resources. In this paper, we aim to bridge this gap by presenting a comprehensive study on supervised fine-tuning of LLMs using instruction-tuning datasets spanning diverse knowledge domains and skills. We focus on small-sized LLMs (3B to 7B parameters) for their cost-efficiency and accessibility. We explore various training configurations and strategies across four open-source pre-trained models. We provide detailed documentation of these configurations, revealing findings that challenge several common training practices, including hyperparameter recommendations from TULU and phased training recommended by Orca. Key insights from our work include: (i) larger batch sizes paired with lower learning rates lead to improved model performance on benchmarks such as MMLU, MTBench, and Open LLM Leaderboard; (ii) early-stage training dynamics, such as lower gradient norms and higher loss values, are strong indicators of better final model performance, enabling early termination of sub-optimal runs and significant computational savings; (iii) through a thorough exploration of hyperparameters like warmup steps and learning rate schedules, we provide guidance for practitioners and find that certain simplifications do not compromise performance; and (iv) we observed no significant difference in performance between phased and stacked training strategies, but stacked training is simpler and more sample efficient. With these findings holding robustly across datasets and models, we hope this study serves as a guide for practitioners fine-tuning small LLMs and promotes a more inclusive environment for LLM research.
Beyond Active Learning: Leveraging the Full Potential of Human Interaction via Auto-Labeling, Human Correction, and Human Verification
Jun 02, 2023



Active Learning (AL) is a human-in-the-loop framework to interactively and adaptively label data instances, thereby enabling significant gains in model performance compared to random sampling. AL approaches function by selecting the hardest instances to label, often relying on notions of diversity and uncertainty. However, we believe that these current paradigms of AL do not leverage the full potential of human interaction granted by automated label suggestions. Indeed, we show that for many classification tasks and datasets, most people verifying if an automatically suggested label is correct take $3\times$ to $4\times$ less time than they do changing an incorrect suggestion to the correct label (or labeling from scratch without any suggestion). Utilizing this result, we propose CLARIFIER (aCtive LeARnIng From tIEred haRdness), an Interactive Learning framework that admits more effective use of human interaction by leveraging the reduced cost of verification. By targeting the hard (uncertain) instances with existing AL methods, the intermediate instances with a novel label suggestion scheme using submodular mutual information functions on a per-class basis, and the easy (confident) instances with highest-confidence auto-labeling, CLARIFIER can improve over the performance of existing AL approaches on multiple datasets -- particularly on those that have a large number of classes -- by almost 1.5$\times$ to 2$\times$ in terms of relative labeling cost.
INGENIOUS: Using Informative Data Subsets for Efficient Pre-Training of Large Language Models
May 11, 2023
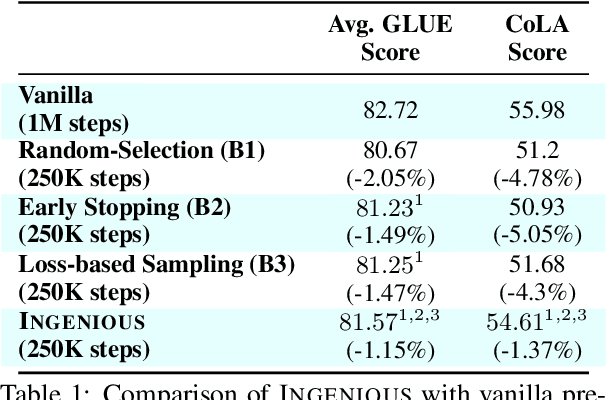

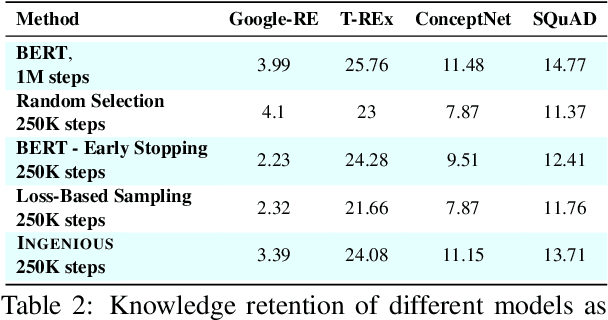
A salient characteristic of large pre-trained language models (PTLMs) is a remarkable improvement in their generalization capability and emergence of new capabilities with increasing model capacity and pre-training dataset size. Consequently, we are witnessing the development of enormous models pushing the state-of-the-art. It is, however, imperative to realize that this inevitably leads to prohibitively long training times, extortionate computing costs, and a detrimental environmental impact. Significant efforts are underway to make PTLM training more efficient through innovations in model architectures, training pipelines, and loss function design, with scant attention being paid to optimizing the utility of training data. The key question that we ask is whether it is possible to train PTLMs by employing only highly informative subsets of the training data while maintaining downstream performance? Building upon the recent progress in informative data subset selection, we show how we can employ submodular optimization to select highly representative subsets of the training corpora. Our results demonstrate that the proposed framework can be applied to efficiently train multiple PTLMs (BERT, BioBERT, GPT-2) using only a fraction of data while retaining up to $\sim99\%$ of the performance of the fully-trained models.
MILO: Model-Agnostic Subset Selection Framework for Efficient Model Training and Tuning
Feb 05, 2023



Training deep networks and tuning hyperparameters on large datasets is computationally intensive. One of the primary research directions for efficient training is to reduce training costs by selecting well-generalizable subsets of training data. Compared to simple adaptive random subset selection baselines, existing intelligent subset selection approaches are not competitive due to the time-consuming subset selection step, which involves computing model-dependent gradients and feature embeddings and applies greedy maximization of submodular objectives. Our key insight is that removing the reliance on downstream model parameters enables subset selection as a pre-processing step and enables one to train multiple models at no additional cost. In this work, we propose MILO, a model-agnostic subset selection framework that decouples the subset selection from model training while enabling superior model convergence and performance by using an easy-to-hard curriculum. Our empirical results indicate that MILO can train models $3\times - 10 \times$ faster and tune hyperparameters $20\times - 75 \times$ faster than full-dataset training or tuning without compromising performance.
AUTOMATA: Gradient Based Data Subset Selection for Compute-Efficient Hyper-parameter Tuning
Mar 15, 2022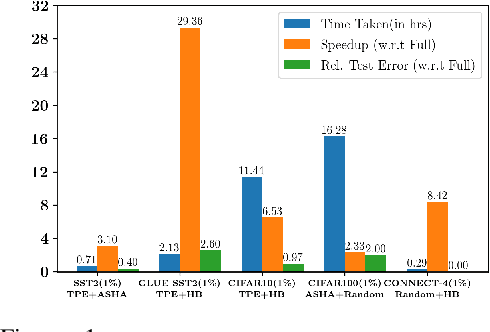
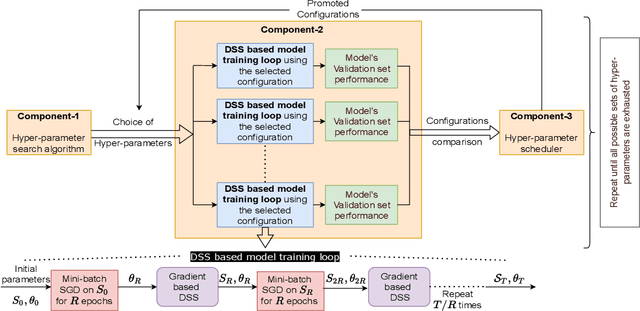

Deep neural networks have seen great success in recent years; however, training a deep model is often challenging as its performance heavily depends on the hyper-parameters used. In addition, finding the optimal hyper-parameter configuration, even with state-of-the-art (SOTA) hyper-parameter optimization (HPO) algorithms, can be time-consuming, requiring multiple training runs over the entire dataset for different possible sets of hyper-parameters. Our central insight is that using an informative subset of the dataset for model training runs involved in hyper-parameter optimization, allows us to find the optimal hyper-parameter configuration significantly faster. In this work, we propose AUTOMATA, a gradient-based subset selection framework for hyper-parameter tuning. We empirically evaluate the effectiveness of AUTOMATA in hyper-parameter tuning through several experiments on real-world datasets in the text, vision, and tabular domains. Our experiments show that using gradient-based data subsets for hyper-parameter tuning achieves significantly faster turnaround times and speedups of 3$\times$-30$\times$ while achieving comparable performance to the hyper-parameters found using the entire dataset.
GCR: Gradient Coreset Based Replay Buffer Selection For Continual Learning
Nov 18, 2021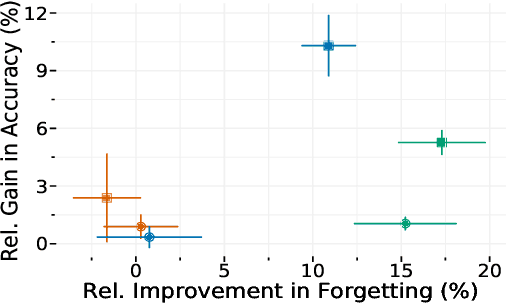
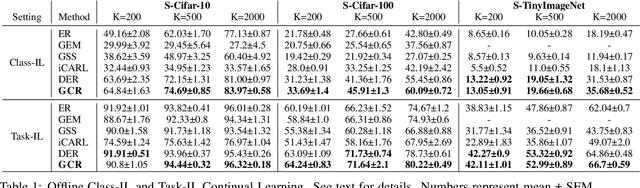
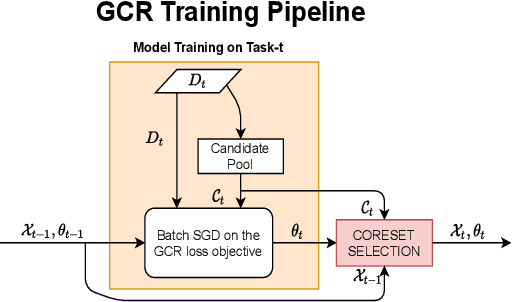

Continual learning (CL) aims to develop techniques by which a single model adapts to an increasing number of tasks encountered sequentially, thereby potentially leveraging learnings across tasks in a resource-efficient manner. A major challenge for CL systems is catastrophic forgetting, where earlier tasks are forgotten while learning a new task. To address this, replay-based CL approaches maintain and repeatedly retrain on a small buffer of data selected across encountered tasks. We propose Gradient Coreset Replay (GCR), a novel strategy for replay buffer selection and update using a carefully designed optimization criterion. Specifically, we select and maintain a "coreset" that closely approximates the gradient of all the data seen so far with respect to current model parameters, and discuss key strategies needed for its effective application to the continual learning setting. We show significant gains (2%-4% absolute) over the state-of-the-art in the well-studied offline continual learning setting. Our findings also effectively transfer to online / streaming CL settings, showing upto 5% gains over existing approaches. Finally, we demonstrate the value of supervised contrastive loss for continual learning, which yields a cumulative gain of up to 5% accuracy when combined with our subset selection strategy.
Learning to Robustly Aggregate Labeling Functions for Semi-supervised Data Programming
Sep 23, 2021
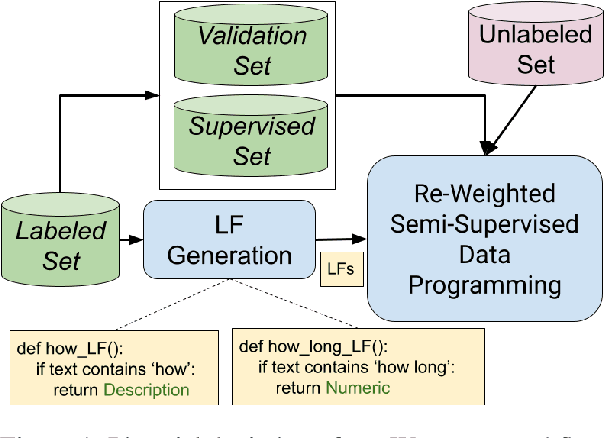
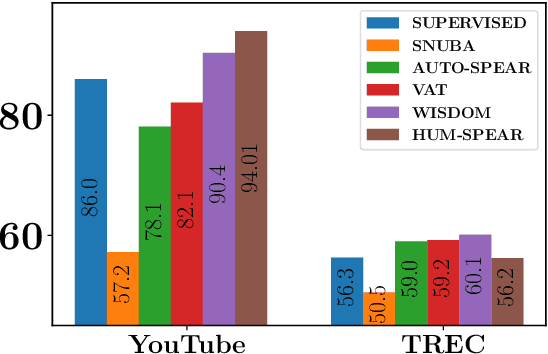
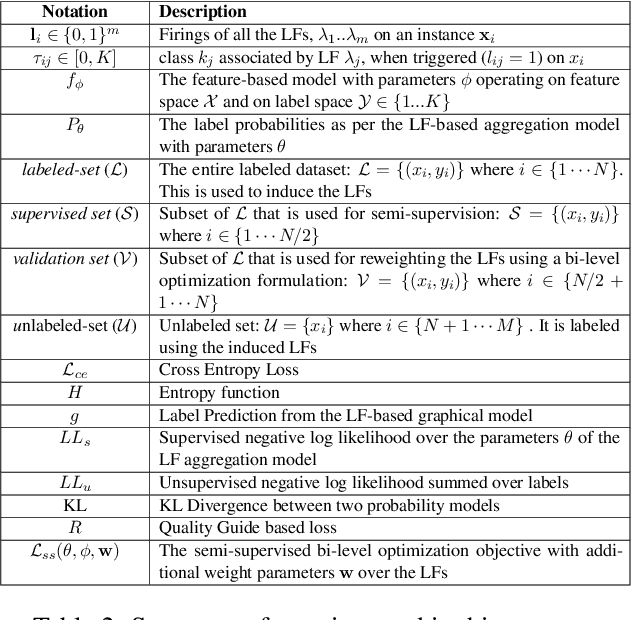
A critical bottleneck in supervised machine learning is the need for large amounts of labeled data which is expensive and time consuming to obtain. However, it has been shown that a small amount of labeled data, while insufficient to re-train a model, can be effectively used to generate human-interpretable labeling functions (LFs). These LFs, in turn, have been used to generate a large amount of additional noisy labeled data, in a paradigm that is now commonly referred to as data programming. However, previous approaches to automatically generate LFs make no attempt to further use the given labeled data for model training, thus giving up opportunities for improved performance. Moreover, since the LFs are generated from a relatively small labeled dataset, they are prone to being noisy, and naively aggregating these LFs can lead to very poor performance in practice. In this work, we propose an LF based reweighting framework \ouralgo{} to solve these two critical limitations. Our algorithm learns a joint model on the (same) labeled dataset used for LF induction along with any unlabeled data in a semi-supervised manner, and more critically, reweighs each LF according to its goodness, influencing its contribution to the semi-supervised loss using a robust bi-level optimization algorithm. We show that our algorithm significantly outperforms prior approaches on several text classification datasets.
SIMILAR: Submodular Information Measures Based Active Learning In Realistic Scenarios
Jul 01, 2021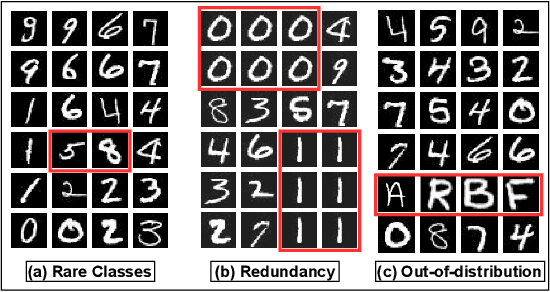

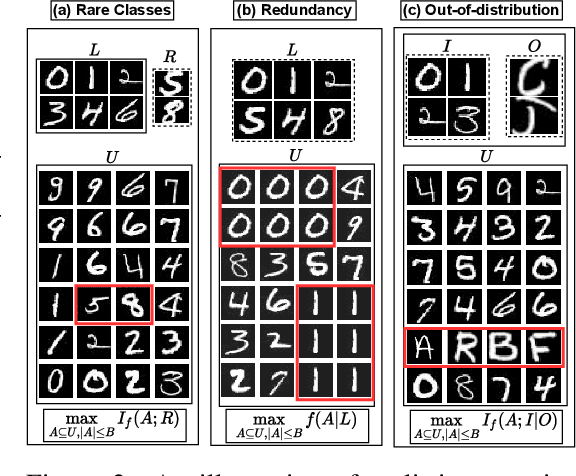
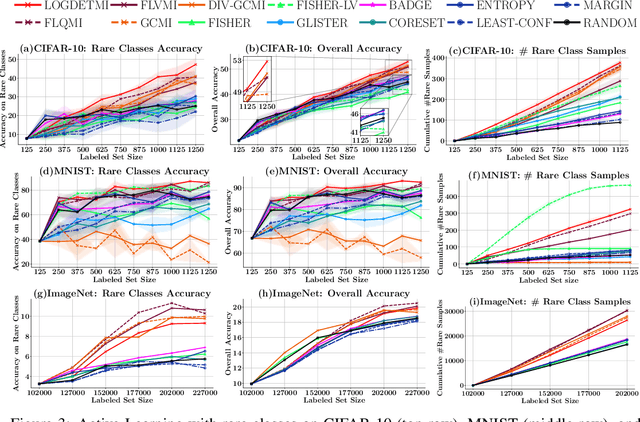
Active learning has proven to be useful for minimizing labeling costs by selecting the most informative samples. However, existing active learning methods do not work well in realistic scenarios such as imbalance or rare classes, out-of-distribution data in the unlabeled set, and redundancy. In this work, we propose SIMILAR (Submodular Information Measures based actIve LeARning), a unified active learning framework using recently proposed submodular information measures (SIM) as acquisition functions. We argue that SIMILAR not only works in standard active learning, but also easily extends to the realistic settings considered above and acts as a one-stop solution for active learning that is scalable to large real-world datasets. Empirically, we show that SIMILAR significantly outperforms existing active learning algorithms by as much as ~5% - 18% in the case of rare classes and ~5% - 10% in the case of out-of-distribution data on several image classification tasks like CIFAR-10, MNIST, and ImageNet.