 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSculpting Subspaces: Constrained Full Fine-Tuning in LLMs for Continual Learning
Apr 09, 2025Continual learning in large language models (LLMs) is prone to catastrophic forgetting, where adapting to new tasks significantly degrades performance on previously learned ones. Existing methods typically rely on low-rank, parameter-efficient updates that limit the model's expressivity and introduce additional parameters per task, leading to scalability issues. To address these limitations, we propose a novel continual full fine-tuning approach leveraging adaptive singular value decomposition (SVD). Our method dynamically identifies task-specific low-rank parameter subspaces and constrains updates to be orthogonal to critical directions associated with prior tasks, thus effectively minimizing interference without additional parameter overhead or storing previous task gradients. We evaluate our approach extensively on standard continual learning benchmarks using both encoder-decoder (T5-Large) and decoder-only (LLaMA-2 7B) models, spanning diverse tasks including classification, generation, and reasoning. Empirically, our method achieves state-of-the-art results, up to 7% higher average accuracy than recent baselines like O-LoRA, and notably maintains the model's general linguistic capabilities, instruction-following accuracy, and safety throughout the continual learning process by reducing forgetting to near-negligible levels. Our adaptive SVD framework effectively balances model plasticity and knowledge retention, providing a practical, theoretically grounded, and computationally scalable solution for continual learning scenarios in large language models.
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
Dec 17, 2024The rise of large language models (LLMs) has created a significant disparity: industrial research labs with their computational resources, expert teams, and advanced infrastructures, can effectively fine-tune LLMs, while individual developers and small organizations face barriers due to limited resources. In this paper, we aim to bridge this gap by presenting a comprehensive study on supervised fine-tuning of LLMs using instruction-tuning datasets spanning diverse knowledge domains and skills. We focus on small-sized LLMs (3B to 7B parameters) for their cost-efficiency and accessibility. We explore various training configurations and strategies across four open-source pre-trained models. We provide detailed documentation of these configurations, revealing findings that challenge several common training practices, including hyperparameter recommendations from TULU and phased training recommended by Orca. Key insights from our work include: (i) larger batch sizes paired with lower learning rates lead to improved model performance on benchmarks such as MMLU, MTBench, and Open LLM Leaderboard; (ii) early-stage training dynamics, such as lower gradient norms and higher loss values, are strong indicators of better final model performance, enabling early termination of sub-optimal runs and significant computational savings; (iii) through a thorough exploration of hyperparameters like warmup steps and learning rate schedules, we provide guidance for practitioners and find that certain simplifications do not compromise performance; and (iv) we observed no significant difference in performance between phased and stacked training strategies, but stacked training is simpler and more sample efficient. With these findings holding robustly across datasets and models, we hope this study serves as a guide for practitioners fine-tuning small LLMs and promotes a more inclusive environment for LLM research.
LAB: Large-Scale Alignment for ChatBots
Mar 06, 2024



This work introduces LAB (Large-scale Alignment for chatBots), a novel methodology designed to overcome the scalability challenges in the instruction-tuning phase of large language model (LLM) training. Leveraging a taxonomy-guided synthetic data generation process and a multi-phase tuning framework, LAB significantly reduces reliance on expensive human annotations and proprietary models like GPT-4. We demonstrate that LAB-trained models can achieve competitive performance across several benchmarks compared to models trained with traditional human-annotated or GPT-4 generated synthetic data. Thus offering a scalable, cost-effective solution for enhancing LLM capabilities and instruction-following behaviors without the drawbacks of catastrophic forgetting, marking a step forward in the efficient training of LLMs for a wide range of applications.
Beyond Uniform Sampling: Offline Reinforcement Learning with Imbalanced Datasets
Oct 12, 2023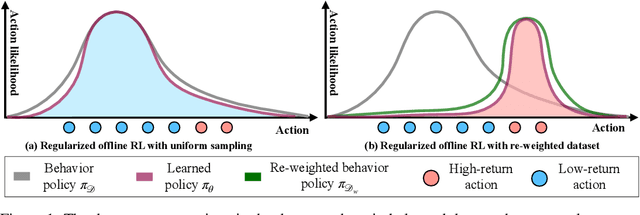

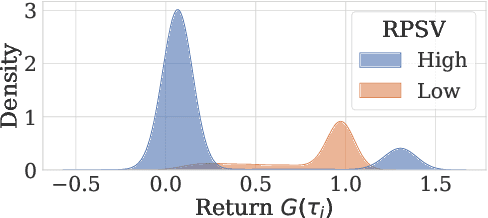
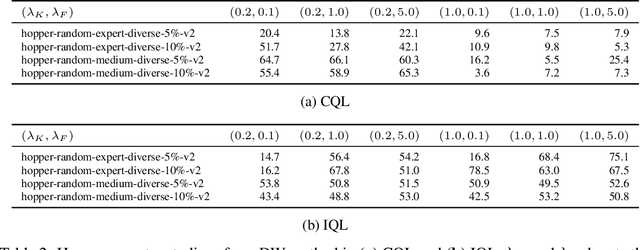
Offline policy learning is aimed at learning decision-making policies using existing datasets of trajectories without collecting additional data. The primary motivation for using reinforcement learning (RL) instead of supervised learning techniques such as behavior cloning is to find a policy that achieves a higher average return than the trajectories constituting the dataset. However, we empirically find that when a dataset is dominated by suboptimal trajectories, state-of-the-art offline RL algorithms do not substantially improve over the average return of trajectories in the dataset. We argue this is due to an assumption made by current offline RL algorithms of staying close to the trajectories in the dataset. If the dataset primarily consists of sub-optimal trajectories, this assumption forces the policy to mimic the suboptimal actions. We overcome this issue by proposing a sampling strategy that enables the policy to only be constrained to ``good data" rather than all actions in the dataset (i.e., uniform sampling). We present a realization of the sampling strategy and an algorithm that can be used as a plug-and-play module in standard offline RL algorithms. Our evaluation demonstrates significant performance gains in 72 imbalanced datasets, D4RL dataset, and across three different offline RL algorithms. Code is available at https://github.com/Improbable-AI/dw-offline-rl.
* Accepted NeurIPS 2023
OPEn: An Open-ended Physics Environment for Learning Without a Task
Oct 13, 2021
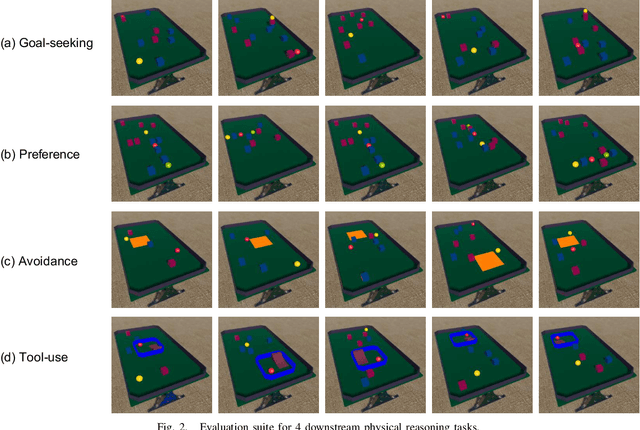

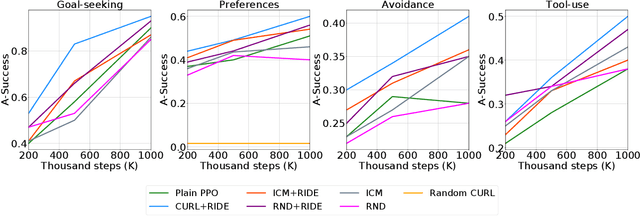
Humans have mental models that allow them to plan, experiment, and reason in the physical world. How should an intelligent agent go about learning such models? In this paper, we will study if models of the world learned in an open-ended physics environment, without any specific tasks, can be reused for downstream physics reasoning tasks. To this end, we build a benchmark Open-ended Physics ENvironment (OPEn) and also design several tasks to test learning representations in this environment explicitly. This setting reflects the conditions in which real agents (i.e. rolling robots) find themselves, where they may be placed in a new kind of environment and must adapt without any teacher to tell them how this environment works. This setting is challenging because it requires solving an exploration problem in addition to a model building and representation learning problem. We test several existing RL-based exploration methods on this benchmark and find that an agent using unsupervised contrastive learning for representation learning, and impact-driven learning for exploration, achieved the best results. However, all models still fall short in sample efficiency when transferring to the downstream tasks. We expect that OPEn will encourage the development of novel rolling robot agents that can build reusable mental models of the world that facilitate many tasks.
The ThreeDWorld Transport Challenge: A Visually Guided Task-and-Motion Planning Benchmark for Physically Realistic Embodied AI
Mar 25, 2021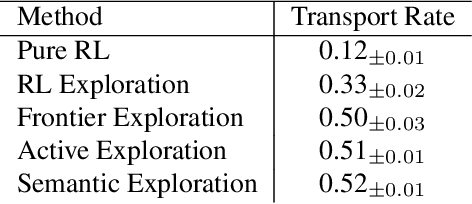

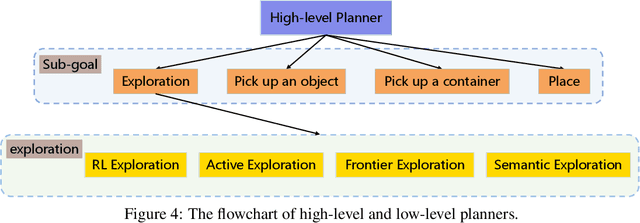
We introduce a visually-guided and physics-driven task-and-motion planning benchmark, which we call the ThreeDWorld Transport Challenge. In this challenge, an embodied agent equipped with two 9-DOF articulated arms is spawned randomly in a simulated physical home environment. The agent is required to find a small set of objects scattered around the house, pick them up, and transport them to a desired final location. We also position containers around the house that can be used as tools to assist with transporting objects efficiently. To complete the task, an embodied agent must plan a sequence of actions to change the state of a large number of objects in the face of realistic physical constraints. We build this benchmark challenge using the ThreeDWorld simulation: a virtual 3D environment where all objects respond to physics, and where can be controlled using fully physics-driven navigation and interaction API. We evaluate several existing agents on this benchmark. Experimental results suggest that: 1) a pure RL model struggles on this challenge; 2) hierarchical planning-based agents can transport some objects but still far from solving this task. We anticipate that this benchmark will empower researchers to develop more intelligent physics-driven robots for the physical world.
AGENT: A Benchmark for Core Psychological Reasoning
Feb 25, 2021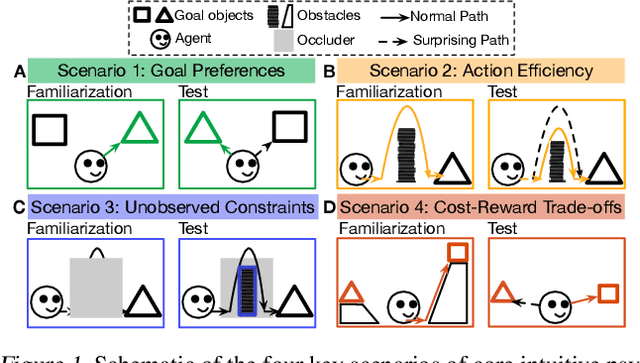
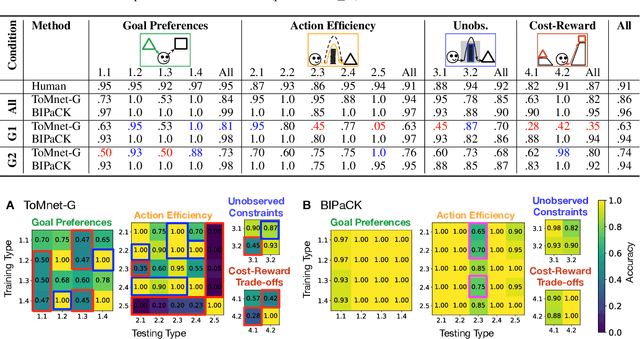
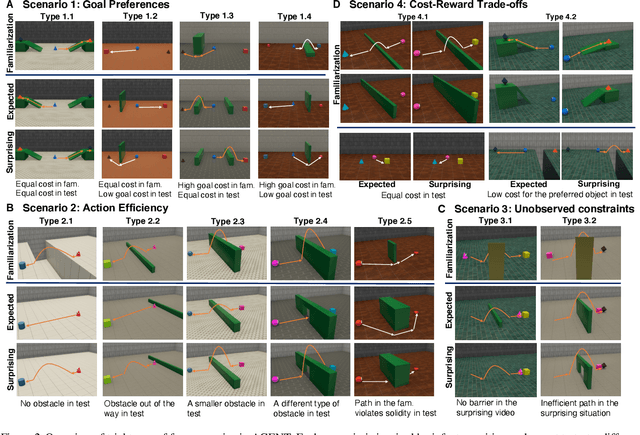
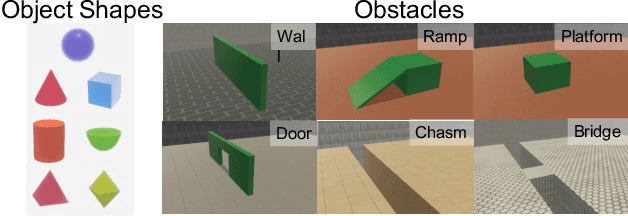
For machine agents to successfully interact with humans in real-world settings, they will need to develop an understanding of human mental life. Intuitive psychology, the ability to reason about hidden mental variables that drive observable actions, comes naturally to people: even pre-verbal infants can tell agents from objects, expecting agents to act efficiently to achieve goals given constraints. Despite recent interest in machine agents that reason about other agents, it is not clear if such agents learn or hold the core psychology principles that drive human reasoning. Inspired by cognitive development studies on intuitive psychology, we present a benchmark consisting of a large dataset of procedurally generated 3D animations, AGENT (Action, Goal, Efficiency, coNstraint, uTility), structured around four scenarios (goal preferences, action efficiency, unobserved constraints, and cost-reward trade-offs) that probe key concepts of core intuitive psychology. We validate AGENT with human-ratings, propose an evaluation protocol emphasizing generalization, and compare two strong baselines built on Bayesian inverse planning and a Theory of Mind neural network. Our results suggest that to pass the designed tests of core intuitive psychology at human levels, a model must acquire or have built-in representations of how agents plan, combining utility computations and core knowledge of objects and physics.
ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
Jul 09, 2020
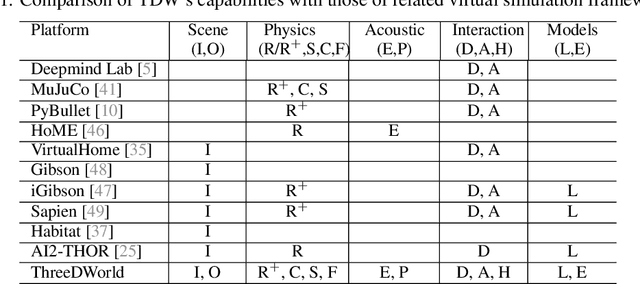

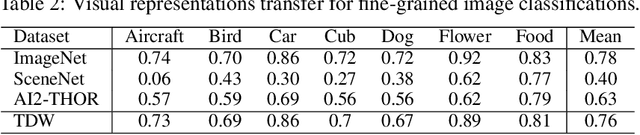
We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. With TDW, users can simulate high-fidelity sensory data and physical interactions between mobile agents and objects in a wide variety of rich 3D environments. TDW has several unique properties: 1) realtime near photo-realistic image rendering quality; 2) a library of objects and environments with materials for high-quality rendering, and routines enabling user customization of the asset library; 3) generative procedures for efficiently building classes of new environments 4) high-fidelity audio rendering; 5) believable and realistic physical interactions for a wide variety of material types, including cloths, liquid, and deformable objects; 6) a range of "avatar" types that serve as embodiments of AI agents, with the option for user avatar customization; and 7) support for human interactions with VR devices. TDW also provides a rich API enabling multiple agents to interact within a simulation and return a range of sensor and physics data representing the state of the world. We present initial experiments enabled by the platform around emerging research directions in computer vision, machine learning, and cognitive science, including multi-modal physical scene understanding, multi-agent interactions, models that "learn like a child", and attention studies in humans and neural networks. The simulation platform will be made publicly available.