 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysInOne: Visual Physics Learning and Reasoning in One Suite
Apr 10, 2026We present PhysInOne, a large-scale synthetic dataset addressing the critical scarcity of physically-grounded training data for AI systems. Unlike existing datasets limited to merely hundreds or thousands of examples, PhysInOne provides 2 million videos across 153,810 dynamic 3D scenes, covering 71 basic physical phenomena in mechanics, optics, fluid dynamics, and magnetism. Distinct from previous works, our scenes feature multiobject interactions against complex backgrounds, with comprehensive ground-truth annotations including 3D geometry, semantics, dynamic motion, physical properties, and text descriptions. We demonstrate PhysInOne's efficacy across four emerging applications: physics-aware video generation, long-/short-term future frame prediction, physical property estimation, and motion transfer. Experiments show that fine-tuning foundation models on PhysInOne significantly enhances physical plausibility, while also exposing critical gaps in modeling complex physical dynamics and estimating intrinsic properties. As the largest dataset of its kind, orders of magnitude beyond prior works, PhysInOne establishes a new benchmark for advancing physics-grounded world models in generation, simulation, and embodied AI.
SynLeaF: A Dual-Stage Multimodal Fusion Framework for Synthetic Lethality Prediction Across Pan- and Single-Cancer Contexts
Mar 23, 2026Accurate prediction of synthetic lethality (SL) is important for guiding the development of cancer drugs and therapies. SL prediction faces significant challenges in the effective fusion of heterogeneous multi-source data. Existing multimodal methods often suffer from "modality laziness" due to disparate convergence speeds, which hinders the exploitation of complementary information. This is also one reason why most existing SL prediction models cannot perform well on both pan-cancer and single-cancer SL pair prediction. In this study, we propose SynLeaF, a dual-stage multimodal fusion framework for SL prediction across pan- and single-cancer contexts. The framework employs a VAE-based cross-encoder with a product of experts mechanism to fuse four omics data types (gene expression, mutation, methylation, and CNV), while simultaneously utilizing a relational graph convolutional network to capture structured gene representations from biomedical knowledge graphs. To mitigate modality laziness, SynLeaF introduces a dual-stage training mechanism employing featurelevel knowledge distillation with adaptive uni-modal teacher and ensemble strategies. In extensive experiments across eight specific cancer types and a pancancer dataset, SynLeaF achieves superior performance in 17 out of 19 scenarios. Ablation studies and gradient analyses further validate the critical contributions of the proposed fusion and distillation mechanisms to model robustness and generalization. To facilitate community use, a web server is available at https://synleaf.bioinformatics-lilab.cn.
Visual Spatial Tuning
Nov 07, 2025Capturing spatial relationships from visual inputs is a cornerstone of human-like general intelligence. Several previous studies have tried to enhance the spatial awareness of Vision-Language Models (VLMs) by adding extra expert encoders, which brings extra overhead and usually harms general capabilities. To enhance the spatial ability in general architectures, we introduce Visual Spatial Tuning (VST), a comprehensive framework to cultivate VLMs with human-like visuospatial abilities, from spatial perception to reasoning. We first attempt to enhance spatial perception in VLMs by constructing a large-scale dataset termed VST-P, which comprises 4.1 million samples spanning 19 skills across single views, multiple images, and videos. Then, we present VST-R, a curated dataset with 135K samples that instruct models to reason in space. In particular, we adopt a progressive training pipeline: supervised fine-tuning to build foundational spatial knowledge, followed by reinforcement learning to further improve spatial reasoning abilities. Without the side-effect to general capabilities, the proposed VST consistently achieves state-of-the-art results on several spatial benchmarks, including $34.8\%$ on MMSI-Bench and $61.2\%$ on VSIBench. It turns out that the Vision-Language-Action models can be significantly enhanced with the proposed spatial tuning paradigm, paving the way for more physically grounded AI.
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
MinD: Unified Visual Imagination and Control via Hierarchical World Models
Jun 23, 2025



Video generation models (VGMs) offer a promising pathway for unified world modeling in robotics by integrating simulation, prediction, and manipulation. However, their practical application remains limited due to (1) slowgeneration speed, which limits real-time interaction, and (2) poor consistency between imagined videos and executable actions. To address these challenges, we propose Manipulate in Dream (MinD), a hierarchical diffusion-based world model framework that employs a dual-system design for vision-language manipulation. MinD executes VGM at low frequencies to extract video prediction features, while leveraging a high-frequency diffusion policy for real-time interaction. This architecture enables low-latency, closed-loop control in manipulation with coherent visual guidance. To better coordinate the two systems, we introduce a video-action diffusion matching module (DiffMatcher), with a novel co-training strategy that uses separate schedulers for each diffusion model. Specifically, we introduce a diffusion-forcing mechanism to DiffMatcher that aligns their intermediate representations during training, helping the fast action model better understand video-based predictions. Beyond manipulation, MinD also functions as a world simulator, reliably predicting task success or failure in latent space before execution. Trustworthy analysis further shows that VGMs can preemptively evaluate task feasibility and mitigate risks. Extensive experiments across multiple benchmarks demonstrate that MinD achieves state-of-the-art manipulation (63%+) in RL-Bench, advancing the frontier of unified world modeling in robotics.
FreeGave: 3D Physics Learning from Dynamic Videos by Gaussian Velocity
Jun 09, 2025In this paper, we aim to model 3D scene geometry, appearance, and the underlying physics purely from multi-view videos. By applying various governing PDEs as PINN losses or incorporating physics simulation into neural networks, existing works often fail to learn complex physical motions at boundaries or require object priors such as masks or types. In this paper, we propose FreeGave to learn the physics of complex dynamic 3D scenes without needing any object priors. The key to our approach is to introduce a physics code followed by a carefully designed divergence-free module for estimating a per-Gaussian velocity field, without relying on the inefficient PINN losses. Extensive experiments on three public datasets and a newly collected challenging real-world dataset demonstrate the superior performance of our method for future frame extrapolation and motion segmentation. Most notably, our investigation into the learned physics codes reveals that they truly learn meaningful 3D physical motion patterns in the absence of any human labels in training.
3DFlowAction: Learning Cross-Embodiment Manipulation from 3D Flow World Model
Jun 06, 2025Manipulation has long been a challenging task for robots, while humans can effortlessly perform complex interactions with objects, such as hanging a cup on the mug rack. A key reason is the lack of a large and uniform dataset for teaching robots manipulation skills. Current robot datasets often record robot action in different action spaces within a simple scene. This hinders the robot to learn a unified and robust action representation for different robots within diverse scenes. Observing how humans understand a manipulation task, we find that understanding how the objects should move in the 3D space is a critical clue for guiding actions. This clue is embodiment-agnostic and suitable for both humans and different robots. Motivated by this, we aim to learn a 3D flow world model from both human and robot manipulation data. This model predicts the future movement of the interacting objects in 3D space, guiding action planning for manipulation. Specifically, we synthesize a large-scale 3D optical flow dataset, named ManiFlow-110k, through a moving object auto-detect pipeline. A video diffusion-based world model then learns manipulation physics from these data, generating 3D optical flow trajectories conditioned on language instructions. With the generated 3D object optical flow, we propose a flow-guided rendering mechanism, which renders the predicted final state and leverages GPT-4o to assess whether the predicted flow aligns with the task description. This equips the robot with a closed-loop planning ability. Finally, we consider the predicted 3D optical flow as constraints for an optimization policy to determine a chunk of robot actions for manipulation. Extensive experiments demonstrate strong generalization across diverse robotic manipulation tasks and reliable cross-embodiment adaptation without hardware-specific training.
Learning 3D Persistent Embodied World Models
May 05, 2025
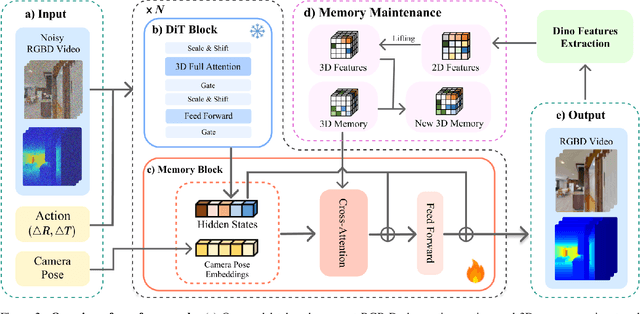
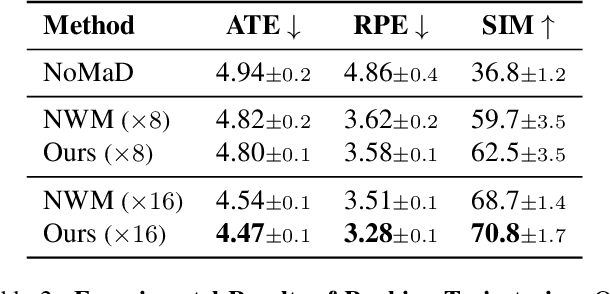
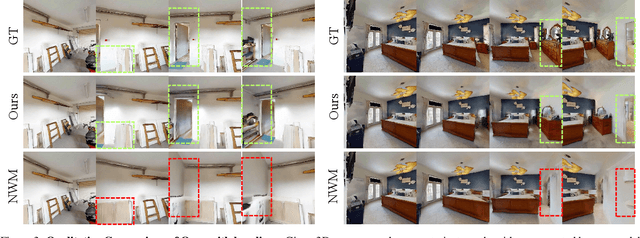
The ability to simulate the effects of future actions on the world is a crucial ability of intelligent embodied agents, enabling agents to anticipate the effects of their actions and make plans accordingly. While a large body of existing work has explored how to construct such world models using video models, they are often myopic in nature, without any memory of a scene not captured by currently observed images, preventing agents from making consistent long-horizon plans in complex environments where many parts of the scene are partially observed. We introduce a new persistent embodied world model with an explicit memory of previously generated content, enabling much more consistent long-horizon simulation. During generation time, our video diffusion model predicts RGB-D video of the future observations of the agent. This generation is then aggregated into a persistent 3D map of the environment. By conditioning the video model on this 3D spatial map, we illustrate how this enables video world models to faithfully simulate both seen and unseen parts of the world. Finally, we illustrate the efficacy of such a world model in downstream embodied applications, enabling effective planning and policy learning.
TesserAct: Learning 4D Embodied World Models
Apr 29, 2025



This paper presents an effective approach for learning novel 4D embodied world models, which predict the dynamic evolution of 3D scenes over time in response to an embodied agent's actions, providing both spatial and temporal consistency. We propose to learn a 4D world model by training on RGB-DN (RGB, Depth, and Normal) videos. This not only surpasses traditional 2D models by incorporating detailed shape, configuration, and temporal changes into their predictions, but also allows us to effectively learn accurate inverse dynamic models for an embodied agent. Specifically, we first extend existing robotic manipulation video datasets with depth and normal information leveraging off-the-shelf models. Next, we fine-tune a video generation model on this annotated dataset, which jointly predicts RGB-DN (RGB, Depth, and Normal) for each frame. We then present an algorithm to directly convert generated RGB, Depth, and Normal videos into a high-quality 4D scene of the world. Our method ensures temporal and spatial coherence in 4D scene predictions from embodied scenarios, enables novel view synthesis for embodied environments, and facilitates policy learning that significantly outperforms those derived from prior video-based world models.
AdaWorld: Learning Adaptable World Models with Latent Actions
Mar 24, 2025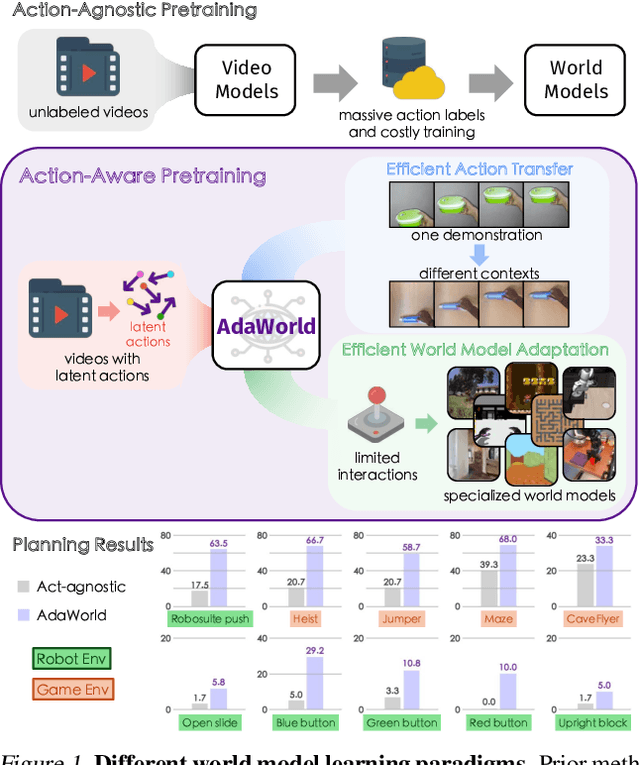
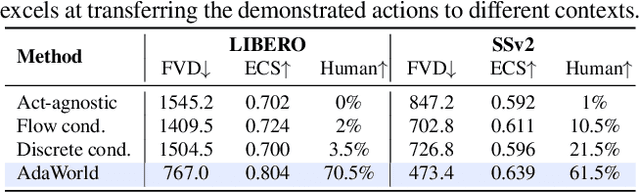
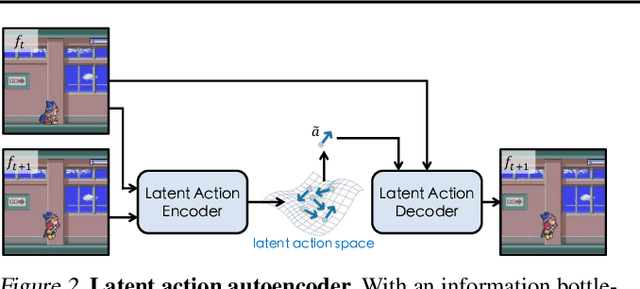
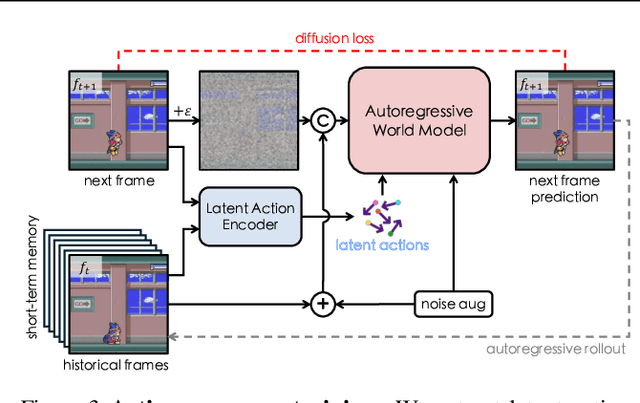
World models aim to learn action-controlled prediction models and have proven essential for the development of intelligent agents. However, most existing world models rely heavily on substantial action-labeled data and costly training, making it challenging to adapt to novel environments with heterogeneous actions through limited interactions. This limitation can hinder their applicability across broader domains. To overcome this challenge, we propose AdaWorld, an innovative world model learning approach that enables efficient adaptation. The key idea is to incorporate action information during the pretraining of world models. This is achieved by extracting latent actions from videos in a self-supervised manner, capturing the most critical transitions between frames. We then develop an autoregressive world model that conditions on these latent actions. This learning paradigm enables highly adaptable world models, facilitating efficient transfer and learning of new actions even with limited interactions and finetuning. Our comprehensive experiments across multiple environments demonstrate that AdaWorld achieves superior performance in both simulation quality and visual planning.