 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewpoint Matters: Dynamically Optimizing Viewpoints with Masked Autoencoder for Visual Manipulation
Feb 04, 2026Robotic manipulation continues to be a challenge, and imitation learning (IL) enables robots to learn tasks from expert demonstrations. Current IL methods typically rely on fixed camera setups, where cameras are manually positioned in static locations, imposing significant limitations on adaptability and coverage. Inspired by human active perception, where humans dynamically adjust their viewpoint to capture the most relevant and least noisy information, we propose MAE-Select, a novel framework for active viewpoint selection in single-camera robotic systems. MAE-Select fully leverages pre-trained multi-view masked autoencoder representations and dynamically selects the next most informative viewpoint at each time chunk without requiring labeled viewpoints. Extensive experiments demonstrate that MAE-Select improves the capabilities of single-camera systems and, in some cases, even surpasses multi-camera setups. The project will be available at https://mae-select.github.io.
FSAG: Enhancing Human-to-Dexterous-Hand Finger-Specific Affordance Grounding via Diffusion Models
Jan 13, 2026Dexterous grasp synthesis remains a central challenge: the high dimensionality and kinematic diversity of multi-fingered hands prevent direct transfer of algorithms developed for parallel-jaw grippers. Existing approaches typically depend on large, hardware-specific grasp datasets collected in simulation or through costly real-world trials, hindering scalability as new dexterous hand designs emerge. To this end, we propose a data-efficient framework, which is designed to bypass robot grasp data collection by exploiting the rich, object-centric semantic priors latent in pretrained generative diffusion models. Temporally aligned and fine-grained grasp affordances are extracted from raw human video demonstrations and fused with 3D scene geometry from depth images to infer semantically grounded contact targets. A kinematics-aware retargeting module then maps these affordance representations to diverse dexterous hands without per-hand retraining. The resulting system produces stable, functionally appropriate multi-contact grasps that remain reliably successful across common objects and tools, while exhibiting strong generalization across previously unseen object instances within a category, pose variations, and multiple hand embodiments. This work (i) introduces a semantic affordance extraction pipeline leveraging vision-language generative priors for dexterous grasping, (ii) demonstrates cross-hand generalization without constructing hardware-specific grasp datasets, and (iii) establishes that a single depth modality suffices for high-performance grasp synthesis when coupled with foundation-model semantics. Our results highlight a path toward scalable, hardware-agnostic dexterous manipulation driven by human demonstrations and pretrained generative models.
Addressing the ID-Matching Challenge in Long Video Captioning
Oct 08, 2025Generating captions for long and complex videos is both critical and challenging, with significant implications for the growing fields of text-to-video generation and multi-modal understanding. One key challenge in long video captioning is accurately recognizing the same individuals who appear in different frames, which we refer to as the ID-Matching problem. Few prior works have focused on this important issue. Those that have, usually suffer from limited generalization and depend on point-wise matching, which limits their overall effectiveness. In this paper, unlike previous approaches, we build upon LVLMs to leverage their powerful priors. We aim to unlock the inherent ID-Matching capabilities within LVLMs themselves to enhance the ID-Matching performance of captions. Specifically, we first introduce a new benchmark for assessing the ID-Matching capabilities of video captions. Using this benchmark, we investigate LVLMs containing GPT-4o, revealing key insights that the performance of ID-Matching can be improved through two methods: 1) enhancing the usage of image information and 2) increasing the quantity of information of individual descriptions. Based on these insights, we propose a novel video captioning method called Recognizing Identities for Captioning Effectively (RICE). Extensive experiments including assessments of caption quality and ID-Matching performance, demonstrate the superiority of our approach. Notably, when implemented on GPT-4o, our RICE improves the precision of ID-Matching from 50% to 90% and improves the recall of ID-Matching from 15% to 80% compared to baseline. RICE makes it possible to continuously track different individuals in the captions of long videos.
Two-Way Garment Transfer: Unified Diffusion Framework for Dressing and Undressing Synthesis
Aug 06, 2025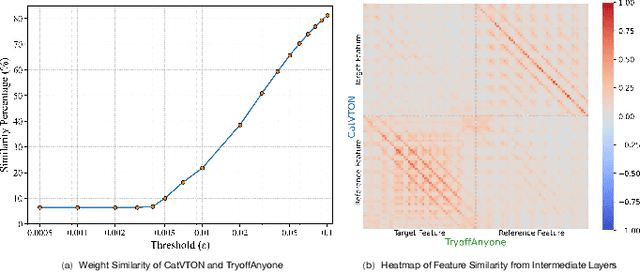
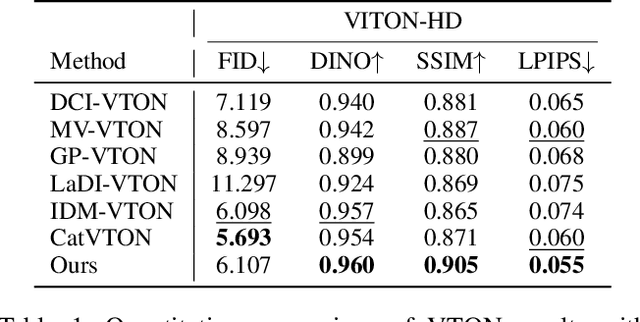
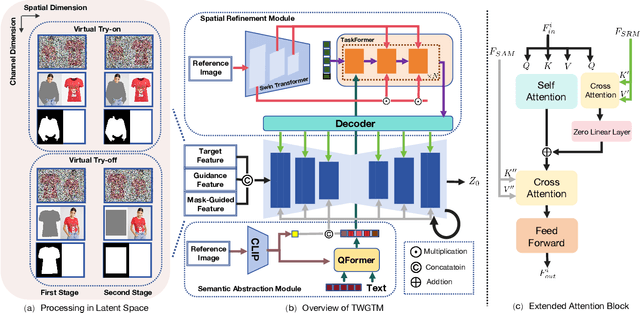

While recent advances in virtual try-on (VTON) have achieved realistic garment transfer to human subjects, its inverse task, virtual try-off (VTOFF), which aims to reconstruct canonical garment templates from dressed humans, remains critically underexplored and lacks systematic investigation. Existing works predominantly treat them as isolated tasks: VTON focuses on garment dressing while VTOFF addresses garment extraction, thereby neglecting their complementary symmetry. To bridge this fundamental gap, we propose the Two-Way Garment Transfer Model (TWGTM), to the best of our knowledge, the first unified framework for joint clothing-centric image synthesis that simultaneously resolves both mask-guided VTON and mask-free VTOFF through bidirectional feature disentanglement. Specifically, our framework employs dual-conditioned guidance from both latent and pixel spaces of reference images to seamlessly bridge the dual tasks. On the other hand, to resolve the inherent mask dependency asymmetry between mask-guided VTON and mask-free VTOFF, we devise a phased training paradigm that progressively bridges this modality gap. Extensive qualitative and quantitative experiments conducted across the DressCode and VITON-HD datasets validate the efficacy and competitive edge of our proposed approach.
CommVQ: Commutative Vector Quantization for KV Cache Compression
Jun 23, 2025Large Language Models (LLMs) are increasingly used in applications requiring long context lengths, but the key-value (KV) cache often becomes a memory bottleneck on GPUs as context grows. To address this, we propose Commutative Vector Quantization (CommVQ) to significantly reduce memory usage for long-context LLM inference. We first introduce additive quantization with a lightweight encoder and codebook to compress the KV cache, which can be decoded via simple matrix multiplication. To further reduce computational costs during decoding, we design the codebook to be commutative with Rotary Position Embedding (RoPE) and train it using an Expectation-Maximization (EM) algorithm. This enables efficient integration of decoding into the self-attention mechanism. Our approach achieves high accuracy with additive quantization and low overhead via the RoPE-commutative codebook. Experiments on long-context benchmarks and GSM8K show that our method reduces FP16 KV cache size by 87.5% with 2-bit quantization, while outperforming state-of-the-art KV cache quantization methods. Notably, it enables 1-bit KV cache quantization with minimal accuracy loss, allowing a LLaMA-3.1 8B model to run with a 128K context length on a single RTX 4090 GPU. The source code is available at: https://github.com/UMass-Embodied-AGI/CommVQ.
Steering LLM Thinking with Budget Guidance
Jun 16, 2025Recent deep-thinking large language models often reason extensively to improve performance, but such lengthy reasoning is not always desirable, as it incurs excessive inference costs with disproportionate performance gains. Controlling reasoning length without sacrificing performance is therefore important, but remains challenging, especially under tight thinking budgets. We propose budget guidance, a simple yet effective method for steering the reasoning process of LLMs toward a target budget without requiring any LLM fine-tuning. Our approach introduces a lightweight predictor that models a Gamma distribution over the remaining thinking length during next-token generation. This signal is then used to guide generation in a soft, token-level manner, ensuring that the overall reasoning trace adheres to the specified thinking budget. Budget guidance enables natural control of the thinking length, along with significant token efficiency improvements over baseline methods on challenging math benchmarks. For instance, it achieves up to a 26% accuracy gain on the MATH-500 benchmark under tight budgets compared to baseline methods, while maintaining competitive accuracy with only 63% of the thinking tokens used by the full-thinking model. Budget guidance also generalizes to broader task domains and exhibits emergent capabilities, such as estimating question difficulty. The source code is available at: https://github.com/UMass-Embodied-AGI/BudgetGuidance.
TesserAct: Learning 4D Embodied World Models
Apr 29, 2025



This paper presents an effective approach for learning novel 4D embodied world models, which predict the dynamic evolution of 3D scenes over time in response to an embodied agent's actions, providing both spatial and temporal consistency. We propose to learn a 4D world model by training on RGB-DN (RGB, Depth, and Normal) videos. This not only surpasses traditional 2D models by incorporating detailed shape, configuration, and temporal changes into their predictions, but also allows us to effectively learn accurate inverse dynamic models for an embodied agent. Specifically, we first extend existing robotic manipulation video datasets with depth and normal information leveraging off-the-shelf models. Next, we fine-tune a video generation model on this annotated dataset, which jointly predicts RGB-DN (RGB, Depth, and Normal) for each frame. We then present an algorithm to directly convert generated RGB, Depth, and Normal videos into a high-quality 4D scene of the world. Our method ensures temporal and spatial coherence in 4D scene predictions from embodied scenarios, enables novel view synthesis for embodied environments, and facilitates policy learning that significantly outperforms those derived from prior video-based world models.
ISAM-MTL: Cross-subject multi-task learning model with identifiable spikes and associative memory networks
Jan 30, 2025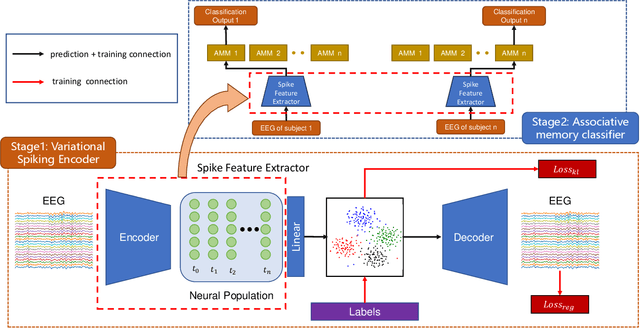
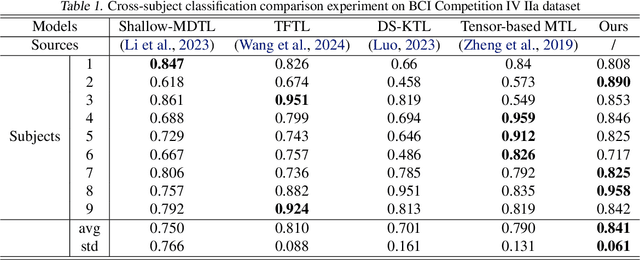
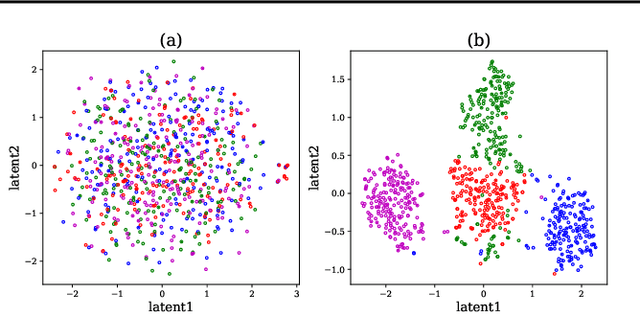
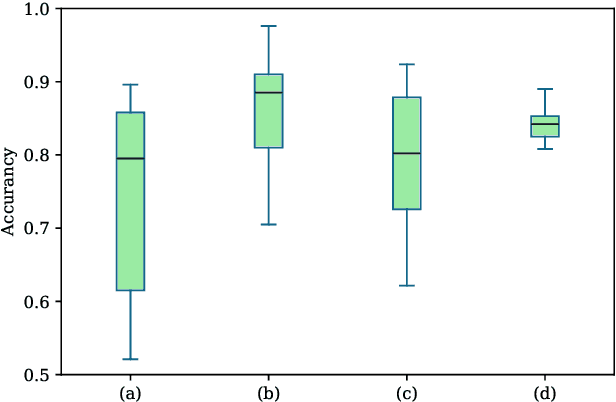
Cross-subject variability in EEG degrades performance of current deep learning models, limiting the development of brain-computer interface (BCI). This paper proposes ISAM-MTL, which is a multi-task learning (MTL) EEG classification model based on identifiable spiking (IS) representations and associative memory (AM) networks. The proposed model treats EEG classification of each subject as an independent task and leverages cross-subject data training to facilitate feature sharing across subjects. ISAM-MTL consists of a spiking feature extractor that captures shared features across subjects and a subject-specific bidirectional associative memory network that is trained by Hebbian learning for efficient and fast within-subject EEG classification. ISAM-MTL integrates learned spiking neural representations with bidirectional associative memory for cross-subject EEG classification. The model employs label-guided variational inference to construct identifiable spike representations, enhancing classification accuracy. Experimental results on two BCI Competition datasets demonstrate that ISAM-MTL improves the average accuracy of cross-subject EEG classification while reducing performance variability among subjects. The model further exhibits the characteristics of few-shot learning and identifiable neural activity beneath EEG, enabling rapid and interpretable calibration for BCI systems.
LSceneLLM: Enhancing Large 3D Scene Understanding Using Adaptive Visual Preferences
Dec 02, 2024



Research on 3D Vision-Language Models (3D-VLMs) is gaining increasing attention, which is crucial for developing embodied AI within 3D scenes, such as visual navigation and embodied question answering. Due to the high density of visual features, especially in large 3D scenes, accurately locating task-relevant visual information is challenging. Existing works attempt to segment all objects and consider their features as scene representations. However, these task-agnostic object features include much redundant information and missing details for the task-relevant area. To tackle these problems, we propose LSceneLLM, an adaptive framework that automatically identifies task-relevant areas by leveraging LLM's visual preference for different tasks, followed by a plug-and-play scene magnifier module to capture fine-grained details in focused areas. Specifically, a dense token selector examines the attention map of LLM to identify visual preferences for the instruction input. It then magnifies fine-grained details of the focusing area. An adaptive self-attention module is leveraged to fuse the coarse-grained and selected fine-grained visual information. To comprehensively evaluate the large scene understanding ability of 3D-VLMs, we further introduce a cross-room understanding benchmark, XR-Scene, which contains a series of large scene understanding tasks including XR-QA, XR-EmbodiedPlanning, and XR-SceneCaption. Experiments show that our method surpasses existing methods on both large scene understanding and existing scene understanding benchmarks. Plunging our scene magnifier module into the existing 3D-VLMs also brings significant improvement.
FoAM: Foresight-Augmented Multi-Task Imitation Policy for Robotic Manipulation
Sep 29, 2024



Multi-task imitation learning (MTIL) has shown significant potential in robotic manipulation by enabling agents to perform various tasks using a unified policy. This simplifies the policy deployment and enhances the agent's adaptability across different contexts. However, key challenges remain, such as maintaining action reliability (e.g., avoiding abnormal action sequences that deviate from nominal task trajectories), distinguishing between similar tasks, and generalizing to unseen scenarios. To address these challenges, we introduce the Foresight-Augmented Manipulation Policy (FoAM), an innovative MTIL framework. FoAM not only learns to mimic expert actions but also predicts the visual outcomes of those actions to enhance decision-making. Additionally, it integrates multi-modal goal inputs, such as visual and language prompts, overcoming the limitations of single-conditioned policies. We evaluated FoAM across over 100 tasks in both simulation and real-world settings, demonstrating that it significantly improves IL policy performance, outperforming current state-of-the-art IL baselines by up to 41% in success rate. Furthermore, we released a simulation benchmark for robotic manipulation, featuring 10 task suites and over 80 challenging tasks designed for multi-task policy training and evaluation. See project homepage https://projFoAM.github.io/ for project details.