 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneRetrieval: Unifying Multi-Branch E-commerce Retrieval with an Editable Generative Model
Jun 11, 2026Industrial e-commerce search serves hundreds of millions of items through a multi-branch retrieval stage fused by hand-tuned merging without joint optimization. Generative retrieval (GR) raises the prospect of collapsing this stage into a single model, yet unification is gated by more than retrieval quality: the inverted-index branch converts below the platform average yet persists because it is almost the only branch where operations can inject a new term within hours without any model update; a one-model substitute must preserve this real-time editability. Existing GR methods structurally lack it: closed-codebook methods fix each slot to a quantized embedding at training, while open-vocabulary methods leave new-term routing to model generalization. We present OneRetrieval, a one-model GR framework built on Keyword-Aligned Encoding (KAE), which ties each identifier position to an interpretable attribute word, pairing competitive recall quality with the editability of the inverted index -- to our knowledge the first editable generative retrieval method. An information-theoretic merging organizes 18 attribute categories into six codebook groups with non-uniform capacity; reserved slots in each codebook can be bound to new words after deployment without retraining; and a four-stage fine-tuning pipeline secures quality and editability jointly. On five million real-traffic requests, OneRetrieval matches the deep recall of the strongest generative baseline, with an intervention hit rate over an order of magnitude above closed-codebook encodings. Online, replacing the inverted-index branch significantly lifts order volume; extending to nearly the entire stage holds conversion while improving CTR. The system is deployed at Kuaishou, serving hundreds of millions of PVs daily.
TIGER-FG: Text-Guided Implicit Fine-Grained Grounding for E-commerce Retrieval
May 18, 2026E-commerce image search often takes a cropped image as the query, while each candidate is represented by full item images and structured text. This image-to-multimodal retrieval setting presents two asymmetries: a modality disparity -- a visual query must match image--text items, and a granularity disparity -- a cropped query must be compared with full images containing background context and possible distractors. Detection-based pipelines handle the granularity disparity through explicit localization but incur extra cost and error propagation, whereas CLIP-style encoders avoid detection, but are vulnerable to backgrounds or irrelevant items. To address these limitations, we propose TIGER-FG, a text-guided implicit fine-grained grounding framework for image-to-multimodal e-commerce retrieval. TIGER-FG uses item text as semantic guidance to produce target-focused item representations without object detection for retrieval. We further introduce dual distillation objectives that preserve target-region spatial consistency and query--item similarity structure, yielding more stable and discriminative multimodal representations. In addition, we construct ECom-RF-IMMR, a realistic benchmark suite with a 10M-pair training set and two evaluation benchmarks covering standard and cluttered item layouts. TIGER-FG improves Recall@1 over the strongest baseline by 6.1 and 34.4 percentage points on the two evaluation benchmarks, respectively, with only 85.7M query-side parameters and 256-dim embeddings. Results on public e-commerce benchmarks further demonstrate its generalization to noisy and one-to-many retrieval scenarios. Code and data will be released.
Shapley-Guided Neural Repair Approach via Derivative-Free Optimization
Apr 01, 2026DNNs are susceptible to defects like backdoors, adversarial attacks, and unfairness, undermining their reliability. Existing approaches mainly involve retraining, optimization, constraint-solving, or search algorithms. However, most methods rely on gradient calculations, restricting applicability to specific activation functions (e.g., ReLU), or use search algorithms with uninterpretable localization and repair. Furthermore, they often lack generalizability across multiple properties. We propose SHARPEN, integrating interpretable fault localization with a derivative-free optimization strategy. First, SHARPEN introduces a Deep SHAP-based localization strategy quantifying each layer's and neuron's marginal contribution to erroneous outputs. Specifically, a hierarchical coarse-to-fine approach reranks layers by aggregated impact, then locates faulty neurons/filters by analyzing activation divergences between property-violating and benign states. Subsequently, SHARPEN incorporates CMA-ES to repair identified neurons. CMA-ES leverages a covariance matrix to capture variable dependencies, enabling gradient-free search and coordinated adjustments across coupled neurons. By combining interpretable localization with evolutionary optimization, SHARPEN enables derivative-free repair across architectures, being less sensitive to gradient anomalies and hyperparameters. We demonstrate SHARPEN's effectiveness on three repair tasks. Balancing property repair and accuracy preservation, it outperforms baselines in backdoor removal (+10.56%), adversarial mitigation (+5.78%), and unfairness repair (+11.82%). Notably, SHARPEN handles diverse tasks, and its modular design is plug-and-play with different derivative-free optimizers, highlighting its flexibility.
OneSearch-V2: The Latent Reasoning Enhanced Self-distillation Generative Search Framework
Mar 25, 2026Generative Retrieval (GR) has emerged as a promising paradigm for modern search systems. Compared to multi-stage cascaded architecture, it offers advantages such as end-to-end joint optimization and high computational efficiency. OneSearch, as a representative industrial-scale deployed generative search framework, has brought significant commercial and operational benefits. However, its inadequate understanding of complex queries, inefficient exploitation of latent user intents, and overfitting to narrow historical preferences have limited its further performance improvement. To address these challenges, we propose \textbf{OneSearch-V2}, a latent reasoning enhanced self-distillation generative search framework. It contains three key innovations: (1) a thought-augmented complex query understanding module, which enables deep query understanding and overcomes the shallow semantic matching limitations of direct inference; (2) a reasoning-internalized self-distillation training pipeline, which uncovers users' potential yet precise e-commerce intentions beyond log-fitting through implicit in-context learning; (3) a behavior preference alignment optimization system, which mitigates reward hacking arising from the single conversion metric, and addresses personal preference via direct user feedback. Extensive offline evaluations demonstrate OneSearch-V2's strong query recognition and user profiling capabilities. Online A/B tests further validate its business effectiveness, yielding +3.98\% item CTR, +3.05\% buyer conversion rate, and +2.11\% order volume. Manual evaluation further confirms gains in search experience quality, with +1.65\% in page good rate and +1.37\% in query-item relevance. More importantly, OneSearch-V2 effectively mitigates common search system issues such as information bubbles and long-tail sparsity, without incurring additional inference costs or serving latency.
Virtual Community: An Open World for Humans, Robots, and Society
Aug 20, 2025

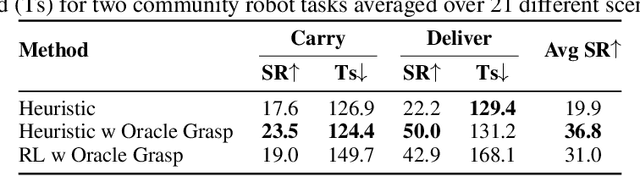

The rapid progress in AI and Robotics may lead to a profound societal transformation, as humans and robots begin to coexist within shared communities, introducing both opportunities and challenges. To explore this future, we present Virtual Community-an open-world platform for humans, robots, and society-built on a universal physics engine and grounded in real-world 3D scenes. With Virtual Community, we aim to study embodied social intelligence at scale: 1) How robots can intelligently cooperate or compete; 2) How humans develop social relations and build community; 3) More importantly, how intelligent robots and humans can co-exist in an open world. To support these, Virtual Community features: 1) An open-source multi-agent physics simulator that supports robots, humans, and their interactions within a society; 2) A large-scale, real-world aligned community generation pipeline, including vast outdoor space, diverse indoor scenes, and a community of grounded agents with rich characters and appearances. Leveraging Virtual Community, we propose two novel challenges. The Community Planning Challenge evaluates multi-agent reasoning and planning ability in open-world settings, such as cooperating to help agents with daily activities and efficiently connecting other agents. The Community Robot Challenge requires multiple heterogeneous robots to collaborate in solving complex open-world tasks. We evaluate various baselines on these tasks and demonstrate the challenges in both high-level open-world task planning and low-level cooperation controls. We hope that Virtual Community will unlock further study of human-robot coexistence within open-world environments.
LSceneLLM: Enhancing Large 3D Scene Understanding Using Adaptive Visual Preferences
Dec 02, 2024



Research on 3D Vision-Language Models (3D-VLMs) is gaining increasing attention, which is crucial for developing embodied AI within 3D scenes, such as visual navigation and embodied question answering. Due to the high density of visual features, especially in large 3D scenes, accurately locating task-relevant visual information is challenging. Existing works attempt to segment all objects and consider their features as scene representations. However, these task-agnostic object features include much redundant information and missing details for the task-relevant area. To tackle these problems, we propose LSceneLLM, an adaptive framework that automatically identifies task-relevant areas by leveraging LLM's visual preference for different tasks, followed by a plug-and-play scene magnifier module to capture fine-grained details in focused areas. Specifically, a dense token selector examines the attention map of LLM to identify visual preferences for the instruction input. It then magnifies fine-grained details of the focusing area. An adaptive self-attention module is leveraged to fuse the coarse-grained and selected fine-grained visual information. To comprehensively evaluate the large scene understanding ability of 3D-VLMs, we further introduce a cross-room understanding benchmark, XR-Scene, which contains a series of large scene understanding tasks including XR-QA, XR-EmbodiedPlanning, and XR-SceneCaption. Experiments show that our method surpasses existing methods on both large scene understanding and existing scene understanding benchmarks. Plunging our scene magnifier module into the existing 3D-VLMs also brings significant improvement.
CoNav: A Benchmark for Human-Centered Collaborative Navigation
Jun 04, 2024Human-robot collaboration, in which the robot intelligently assists the human with the upcoming task, is an appealing objective. To achieve this goal, the agent needs to be equipped with a fundamental collaborative navigation ability, where the agent should reason human intention by observing human activities and then navigate to the human's intended destination in advance of the human. However, this vital ability has not been well studied in previous literature. To fill this gap, we propose a collaborative navigation (CoNav) benchmark. Our CoNav tackles the critical challenge of constructing a 3D navigation environment with realistic and diverse human activities. To achieve this, we design a novel LLM-based humanoid animation generation framework, which is conditioned on both text descriptions and environmental context. The generated humanoid trajectory obeys the environmental context and can be easily integrated into popular simulators. We empirically find that the existing navigation methods struggle in CoNav task since they neglect the perception of human intention. To solve this problem, we propose an intention-aware agent for reasoning both long-term and short-term human intention. The agent predicts navigation action based on the predicted intention and panoramic observation. The emergent agent behavior including observing humans, avoiding human collision, and navigation reveals the efficiency of the proposed datasets and agents.
A Simple Knowledge Distillation Framework for Open-world Object Detection
Dec 14, 2023Open World Object Detection (OWOD) is a novel computer vision task with a considerable challenge, bridging the gap between classic object detection (OD) benchmarks and real-world object detection. In addition to detecting and classifying seen/known objects, OWOD algorithms are expected to localize all potential unseen/unknown objects and incrementally learn them. The large pre-trained vision-language grounding models (VLM,eg, GLIP) have rich knowledge about the open world, but are limited by text prompts and cannot localize indescribable objects. However, there are many detection scenarios which pre-defined language descriptions are unavailable during inference. In this paper, we attempt to specialize the VLM model for OWOD task by distilling its open-world knowledge into a language-agnostic detector. Surprisingly, we observe that the combination of a simple knowledge distillation approach and the automatic pseudo-labeling mechanism in OWOD can achieve better performance for unknown object detection, even with a small amount of data. Unfortunately, knowledge distillation for unknown objects severely affects the learning of detectors with conventional structures for known objects, leading to catastrophic forgetting. To alleviate these problems, we propose the down-weight loss function for knowledge distillation from vision-language to single vision modality. Meanwhile, we decouple the learning of localization and recognition to reduce the impact of category interactions of known and unknown objects on the localization learning process. Comprehensive experiments performed on MS-COCO and PASCAL VOC demonstrate the effectiveness of our methods.
Contrastive Vision-Language Alignment Makes Efficient Instruction Learner
Nov 29, 2023We study the task of extending the large language model (LLM) into a vision-language instruction-following model. This task is crucial but challenging since the LLM is trained on text modality only, making it hard to effectively digest the visual modality. To address this, existing methods typically train a visual adapter to align the representation between a pre-trained vision transformer (ViT) and the LLM by a generative image captioning loss. However, we find that the generative objective can only produce weak alignment for vision and language, making the aligned vision-language model very hungry for the instruction fine-tuning data. In this paper, we propose CG-VLM that applies both Contrastive and Generative alignment objectives to effectively align the representation of ViT and LLM. Different from image level and sentence level alignment in common contrastive learning settings, CG-VLM aligns the image-patch level features and text-token level embeddings, which, however, is very hard to achieve as no explicit grounding patch-token relation provided in standard image captioning datasets. To address this issue, we propose to maximize the averaged similarity between pooled image-patch features and text-token embeddings. Extensive experiments demonstrate that the proposed CG-VLM produces strong vision-language alignment and is an efficient instruction learner. For example, using only 10% instruction tuning data, we reach 95% performance of state-of-the-art method LLaVA [29] on the zero-shot ScienceQA-Image benchmark.
RGM: A Robust Generalist Matching Model
Oct 19, 2023

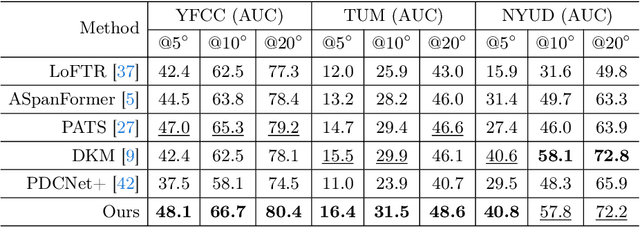

Finding corresponding pixels within a pair of images is a fundamental computer vision task with various applications. Due to the specific requirements of different tasks like optical flow estimation and local feature matching, previous works are primarily categorized into dense matching and sparse feature matching focusing on specialized architectures along with task-specific datasets, which may somewhat hinder the generalization performance of specialized models. In this paper, we propose a deep model for sparse and dense matching, termed RGM (Robust Generalist Matching). In particular, we elaborately design a cascaded GRU module for refinement by exploring the geometric similarity iteratively at multiple scales following an additional uncertainty estimation module for sparsification. To narrow the gap between synthetic training samples and real-world scenarios, we build a new, large-scale dataset with sparse correspondence ground truth by generating optical flow supervision with greater intervals. As such, we are able to mix up various dense and sparse matching datasets, significantly improving the training diversity. The generalization capacity of our proposed RGM is greatly improved by learning the matching and uncertainty estimation in a two-stage manner on the large, mixed data. Superior performance is achieved for zero-shot matching and downstream geometry estimation across multiple datasets, outperforming the previous methods by a large margin.