 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOMATO: Marrying Pointmap Matching with Temporal Motion for Dynamic 3D Reconstruction
Apr 08, 20253D reconstruction in dynamic scenes primarily relies on the combination of geometry estimation and matching modules where the latter task is pivotal for distinguishing dynamic regions which can help to mitigate the interference introduced by camera and object motion. Furthermore, the matching module explicitly models object motion, enabling the tracking of specific targets and advancing motion understanding in complex scenarios. Recently, the proposed representation of pointmap in DUSt3R suggests a potential solution to unify both geometry estimation and matching in 3D space, but it still struggles with ambiguous matching in dynamic regions, which may hamper further improvement. In this work, we present POMATO, a unified framework for dynamic 3D reconstruction by marrying pointmap matching with temporal motion. Specifically, our method first learns an explicit matching relationship by mapping RGB pixels from both dynamic and static regions across different views to 3D pointmaps within a unified coordinate system. Furthermore, we introduce a temporal motion module for dynamic motions that ensures scale consistency across different frames and enhances performance in tasks requiring both precise geometry and reliable matching, most notably 3D point tracking. We show the effectiveness of the proposed pointmap matching and temporal fusion paradigm by demonstrating the remarkable performance across multiple downstream tasks, including video depth estimation, 3D point tracking, and pose estimation. Code and models are publicly available at https://github.com/wyddmw/POMATO.
WiseAD: Knowledge Augmented End-to-End Autonomous Driving with Vision-Language Model
Dec 13, 2024The emergence of general human knowledge and impressive logical reasoning capacity in rapidly progressed vision-language models (VLMs) have driven increasing interest in applying VLMs to high-level autonomous driving tasks, such as scene understanding and decision-making. However, an in-depth study on the relationship between knowledge proficiency, especially essential driving expertise, and closed-loop autonomous driving performance requires further exploration. In this paper, we investigate the effects of the depth and breadth of fundamental driving knowledge on closed-loop trajectory planning and introduce WiseAD, a specialized VLM tailored for end-to-end autonomous driving capable of driving reasoning, action justification, object recognition, risk analysis, driving suggestions, and trajectory planning across diverse scenarios. We employ joint training on driving knowledge and planning datasets, enabling the model to perform knowledge-aligned trajectory planning accordingly. Extensive experiments indicate that as the diversity of driving knowledge extends, critical accidents are notably reduced, contributing 11.9% and 12.4% improvements in the driving score and route completion on the Carla closed-loop evaluations, achieving state-of-the-art performance. Moreover, WiseAD also demonstrates remarkable performance in knowledge evaluations on both in-domain and out-of-domain datasets.
Digging Into Normal Incorporated Stereo Matching
Feb 28, 2024Despite the remarkable progress facilitated by learning-based stereo-matching algorithms, disparity estimation in low-texture, occluded, and bordered regions still remains a bottleneck that limits the performance. To tackle these challenges, geometric guidance like plane information is necessary as it provides intuitive guidance about disparity consistency and affinity similarity. In this paper, we propose a normal incorporated joint learning framework consisting of two specific modules named non-local disparity propagation(NDP) and affinity-aware residual learning(ARL). The estimated normal map is first utilized for calculating a non-local affinity matrix and a non-local offset to perform spatial propagation at the disparity level. To enhance geometric consistency, especially in low-texture regions, the estimated normal map is then leveraged to calculate a local affinity matrix, providing the residual learning with information about where the correction should refer and thus improving the residual learning efficiency. Extensive experiments on several public datasets including Scene Flow, KITTI 2015, and Middlebury 2014 validate the effectiveness of our proposed method. By the time we finished this work, our approach ranked 1st for stereo matching across foreground pixels on the KITTI 2015 dataset and 3rd on the Scene Flow dataset among all the published works.
RGM: A Robust Generalist Matching Model
Oct 19, 2023Finding corresponding pixels within a pair of images is a fundamental computer vision task with various applications. Due to the specific requirements of different tasks like optical flow estimation and local feature matching, previous works are primarily categorized into dense matching and sparse feature matching focusing on specialized architectures along with task-specific datasets, which may somewhat hinder the generalization performance of specialized models. In this paper, we propose a deep model for sparse and dense matching, termed RGM (Robust Generalist Matching). In particular, we elaborately design a cascaded GRU module for refinement by exploring the geometric similarity iteratively at multiple scales following an additional uncertainty estimation module for sparsification. To narrow the gap between synthetic training samples and real-world scenarios, we build a new, large-scale dataset with sparse correspondence ground truth by generating optical flow supervision with greater intervals. As such, we are able to mix up various dense and sparse matching datasets, significantly improving the training diversity. The generalization capacity of our proposed RGM is greatly improved by learning the matching and uncertainty estimation in a two-stage manner on the large, mixed data. Superior performance is achieved for zero-shot matching and downstream geometry estimation across multiple datasets, outperforming the previous methods by a large margin.
DAVOS: Semi-Supervised Video Object Segmentation via Adversarial Domain Adaptation
May 24, 2021

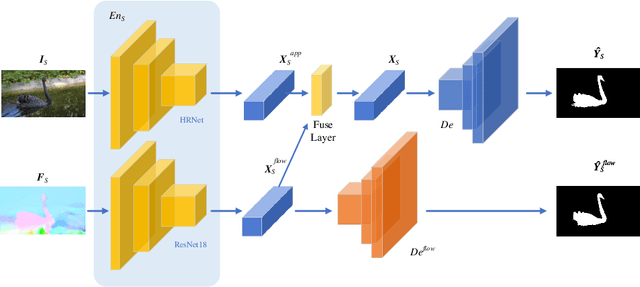
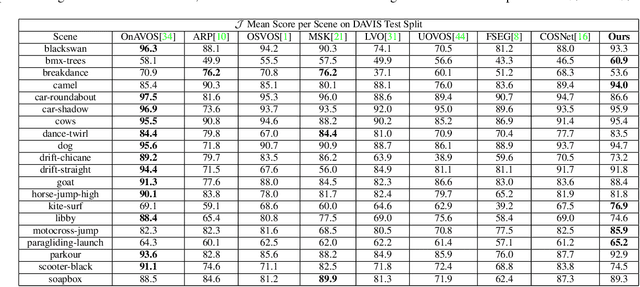
Domain shift has always been one of the primary issues in video object segmentation (VOS), for which models suffer from degeneration when tested on unfamiliar datasets. Recently, many online methods have emerged to narrow the performance gap between training data (source domain) and test data (target domain) by fine-tuning on annotations of test data which are usually in shortage. In this paper, we propose a novel method to tackle domain shift by first introducing adversarial domain adaptation to the VOS task, with supervised training on the source domain and unsupervised training on the target domain. By fusing appearance and motion features with a convolution layer, and by adding supervision onto the motion branch, our model achieves state-of-the-art performance on DAVIS2016 with 82.6% mean IoU score after supervised training. Meanwhile, our adversarial domain adaptation strategy significantly raises the performance of the trained model when applied on FBMS59 and Youtube-Object, without exploiting extra annotations.
EDNet: Efficient Disparity Estimation with Combination Volume and Spatial Attention based Residual Learning
Nov 08, 2020



Existing state-of-the-art disparity estimation works mostly leverage the 4D concatenation volume and construct a very deep 3D convolution neural network for disparity regression, which is inefficient considering the high memory consumption and slow inference speed. In this paper, we propose a network named EDNet for efficient disparity estimation. To be specific, we construct a combination volume which incorporates contextual information from the concatenation volume and feature similarity measurement from the correlation volume. The combination volume can be aggregated by 2D convolutions which require less running memory. We further propose a spatial attention based residual learning module to generate attention-aware residual features. Accurate disparity correction can be provided even in low-texture regions as the residual learning process can specifically concentrate on inaccurate regions. Extensive experiments on Scene Flow and KITTI datasets show that our network outperforms previous 3D convolution based works and achieves state-of-the-art performance with significantly faster speed and less memory consumption, demonstrating the effectiveness of our proposed method.