 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging NeRF-Rendered Images for 3D Gaussian Splatting
Jun 08, 2026Neural radiance field (NeRF) and 3D Gaussian splatting (3DGS) are two mainstream approaches for novel view synthesis. They often show complementary performance, i.e., 3DGS demonstrating faster rendering speed and NeRF demonstrating higher rendering quality. Motivated by this, we propose leveraging NeRF-rendered images for 3DGS. Specifically, we target street scenes and utilize a pre-trained street-specific NeRF method to produce training images for a target 3DGS method. In our 3DGS training, NeRF-rendered images are used to remove transient objects in street-level input views and to generate bird's-eye views as additional views, inheriting the higher-quality rendering of NeRF into 3DGS. We further incorporate a diffusion-based image enhancement to improve the image quality of the additional views. Experimental results on one synthetic and two real datasets demonstrate that our proposed method improves street-scene rendering while preserving the speed of 3DGS and the quality of NeRF.
Joint 2D-3D Segmentation and Association in Street-level Imaging
May 26, 2026Accurate interpretation of street-level imagery is essential for large-scale urban mapping and the creation of Spatial Digital Twin (SDT) environments. This work presents a unified framework for joint 2D-3D segmentation and association that integrates visual semantics with multi-view geometric reasoning. Unlike conventional approaches that rely heavily on sequential frames for temporal tracking, our method leverages zero-shot detection and segmentation together with structure-from-motion reconstruction to establish stable cross-view correspondences. A 3D-driven association mechanism replaces traditional 2D multi-object tracking, using geometric consistency to guide identity preservation across wide-baseline viewpoints and varying imaging conditions. By combining 2D texture cues with global 3D context, the proposed pipeline is well-suited for scalable street-level processing and can be used for a variety of object types. Experiments demonstrate substantially improved coverage of ground-truth sequences and more robust identity retention compared to state-of-the-art 2D-only tracking methods, achieving a 22% performance gain in challenging urban scenarios.
RAM-H1200: A Unified Evaluation and Dataset on Hand Radiographs for Rheumatoid Arthritis
May 07, 2026Rheumatoid arthritis (RA) assessment from hand radiographs requires multi-level analysis and modeling of anatomical structures and fine-grained local pathological changes. However, existing public resources do not support such unified multi-level analysis, often lacking full-hand coverage, fine-grained annotations, and consistent integration with clinical scoring systems. In particular, annotations that enable quantitative analysis of bone erosion (BE) remain scarce. RAM-H1200 contains 1,200 hand radiographs collected from six medical centers, with multi-level annotations including (i) whole-hand bone structure instance segmentation, (ii) pixel-level BE masks, (iii) SvdH-defined joint regions of interest, and (iv) joint-level SvdH scores for both BE and joint space narrowing (JSN). It is designed to evaluate whether models can jointly capture anatomical structure, localized erosive pathology, and clinically standardized RA severity from hand radiographs. The proposed BE masks enable, for the first time, quantitative BE analysis beyond coarse categorical grading by providing explicit spatial supervision for lesion extent and morphology. To our knowledge, RAM-H1200 is the first public large-scale benchmark that jointly supports whole-hand bone structure instance segmentation, pixel-level BE delineation, and clinically grounded joint-level SvdH scoring for both BE and JSN. Results across benchmark tasks show that anatomical modeling is substantially more mature than quantitative BE analysis: whole-hand bone segmentation achieves strong performance, whereas BE segmentation remains a major open challenge. By unifying anatomical structure modeling, quantitative lesion analysis, and clinically grounded SvdH scoring, RAM-H1200 provides a single benchmark for comprehensive RA analysis on hand radiographs.
Segmentation-Guided Neural Radiance Fields for Novel Street View Synthesis
Mar 18, 2025Recent advances in Neural Radiance Fields (NeRF) have shown great potential in 3D reconstruction and novel view synthesis, particularly for indoor and small-scale scenes. However, extending NeRF to large-scale outdoor environments presents challenges such as transient objects, sparse cameras and textures, and varying lighting conditions. In this paper, we propose a segmentation-guided enhancement to NeRF for outdoor street scenes, focusing on complex urban environments. Our approach extends ZipNeRF and utilizes Grounded SAM for segmentation mask generation, enabling effective handling of transient objects, modeling of the sky, and regularization of the ground. We also introduce appearance embeddings to adapt to inconsistent lighting across view sequences. Experimental results demonstrate that our method outperforms the baseline ZipNeRF, improving novel view synthesis quality with fewer artifacts and sharper details.
TDM: Temporally-Consistent Diffusion Model for All-in-One Real-World Video Restoration
Jan 04, 2025



In this paper, we propose the first diffusion-based all-in-one video restoration method that utilizes the power of a pre-trained Stable Diffusion and a fine-tuned ControlNet. Our method can restore various types of video degradation with a single unified model, overcoming the limitation of standard methods that require specific models for each restoration task. Our contributions include an efficient training strategy with Task Prompt Guidance (TPG) for diverse restoration tasks, an inference strategy that combines Denoising Diffusion Implicit Models~(DDIM) inversion with a novel Sliding Window Cross-Frame Attention (SW-CFA) mechanism for enhanced content preservation and temporal consistency, and a scalable pipeline that makes our method all-in-one to adapt to different video restoration tasks. Through extensive experiments on five video restoration tasks, we demonstrate the superiority of our method in generalization capability to real-world videos and temporal consistency preservation over existing state-of-the-art methods. Our method advances the video restoration task by providing a unified solution that enhances video quality across multiple applications.
Disparity Estimation Using a Quad-Pixel Sensor
Sep 01, 2024



A quad-pixel (QP) sensor is increasingly integrated into commercial mobile cameras. The QP sensor has a unit of 2$\times$2 four photodiodes under a single microlens, generating multi-directional phase shifting when out-focus blurs occur. Similar to a dual-pixel (DP) sensor, the phase shifting can be regarded as stereo disparity and utilized for depth estimation. Based on this, we propose a QP disparity estimation network (QPDNet), which exploits abundant QP information by fusing vertical and horizontal stereo-matching correlations for effective disparity estimation. We also present a synthetic pipeline to generate a training dataset from an existing RGB-Depth dataset. Experimental results demonstrate that our QPDNet outperforms state-of-the-art stereo and DP methods. Our code and synthetic dataset are available at https://github.com/Zhuofeng-Wu/QPDNet.
Neural Radiance Fields for Novel View Synthesis in Monocular Gastroscopy
May 29, 2024



Enabling the synthesis of arbitrarily novel viewpoint images within a patient's stomach from pre-captured monocular gastroscopic images is a promising topic in stomach diagnosis. Typical methods to achieve this objective integrate traditional 3D reconstruction techniques, including structure-from-motion (SfM) and Poisson surface reconstruction. These methods produce explicit 3D representations, such as point clouds and meshes, thereby enabling the rendering of the images from novel viewpoints. However, the existence of low-texture and non-Lambertian regions within the stomach often results in noisy and incomplete reconstructions of point clouds and meshes, hindering the attainment of high-quality image rendering. In this paper, we apply the emerging technique of neural radiance fields (NeRF) to monocular gastroscopic data for synthesizing photo-realistic images for novel viewpoints. To address the performance degradation due to view sparsity in local regions of monocular gastroscopy, we incorporate geometry priors from a pre-reconstructed point cloud into the training of NeRF, which introduces a novel geometry-based loss to both pre-captured observed views and generated unobserved views. Compared to other recent NeRF methods, our approach showcases high-fidelity image renderings from novel viewpoints within the stomach both qualitatively and quantitatively.
VSRD: Instance-Aware Volumetric Silhouette Rendering for Weakly Supervised 3D Object Detection
Mar 29, 2024Monocular 3D object detection poses a significant challenge in 3D scene understanding due to its inherently ill-posed nature in monocular depth estimation. Existing methods heavily rely on supervised learning using abundant 3D labels, typically obtained through expensive and labor-intensive annotation on LiDAR point clouds. To tackle this problem, we propose a novel weakly supervised 3D object detection framework named VSRD (Volumetric Silhouette Rendering for Detection) to train 3D object detectors without any 3D supervision but only weak 2D supervision. VSRD consists of multi-view 3D auto-labeling and subsequent training of monocular 3D object detectors using the pseudo labels generated in the auto-labeling stage. In the auto-labeling stage, we represent the surface of each instance as a signed distance field (SDF) and render its silhouette as an instance mask through our proposed instance-aware volumetric silhouette rendering. To directly optimize the 3D bounding boxes through rendering, we decompose the SDF of each instance into the SDF of a cuboid and the residual distance field (RDF) that represents the residual from the cuboid. This mechanism enables us to optimize the 3D bounding boxes in an end-to-end manner by comparing the rendered instance masks with the ground truth instance masks. The optimized 3D bounding boxes serve as effective training data for 3D object detection. We conduct extensive experiments on the KITTI-360 dataset, demonstrating that our method outperforms the existing weakly supervised 3D object detection methods. The code is available at https://github.com/skmhrk1209/VSRD.
CFDNet: A Generalizable Foggy Stereo Matching Network with Contrastive Feature Distillation
Feb 29, 2024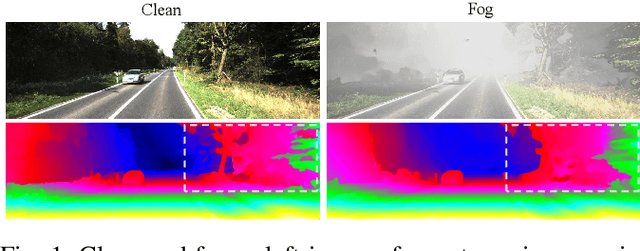
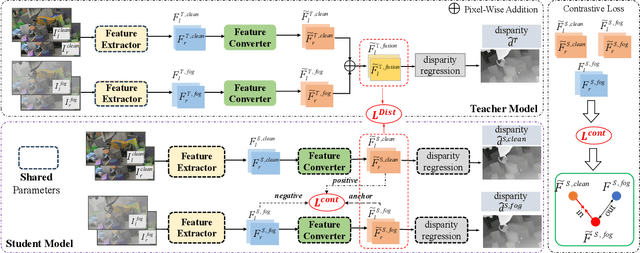
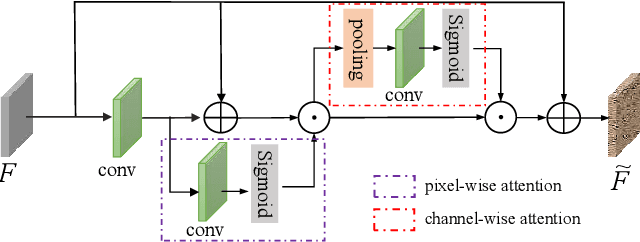
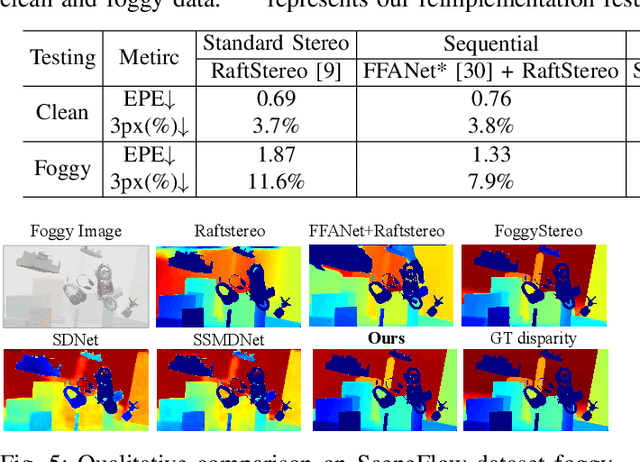
Stereo matching under foggy scenes remains a challenging task since the scattering effect degrades the visibility and results in less distinctive features for dense correspondence matching. While some previous learning-based methods integrated a physical scattering function for simultaneous stereo-matching and dehazing, simply removing fog might not aid depth estimation because the fog itself can provide crucial depth cues. In this work, we introduce a framework based on contrastive feature distillation (CFD). This strategy combines feature distillation from merged clean-fog features with contrastive learning, ensuring balanced dependence on fog depth hints and clean matching features. This framework helps to enhance model generalization across both clean and foggy environments. Comprehensive experiments on synthetic and real-world datasets affirm the superior strength and adaptability of our method.
Reflection Removal Using Recurrent Polarization-to-Polarization Network
Feb 28, 2024This paper addresses reflection removal, which is the task of separating reflection components from a captured image and deriving the image with only transmission components. Considering that the existence of the reflection changes the polarization state of a scene, some existing methods have exploited polarized images for reflection removal. While these methods apply polarized images as the inputs, they predict the reflection and the transmission directly as non-polarized intensity images. In contrast, we propose a polarization-to-polarization approach that applies polarized images as the inputs and predicts "polarized" reflection and transmission images using two sequential networks to facilitate the separation task by utilizing the interrelated polarization information between the reflection and the transmission. We further adopt a recurrent framework, where the predicted reflection and transmission images are used to iteratively refine each other. Experimental results on a public dataset demonstrate that our method outperforms other state-of-the-art methods.