 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation-Guided Neural Radiance Fields for Novel Street View Synthesis
Mar 18, 2025Recent advances in Neural Radiance Fields (NeRF) have shown great potential in 3D reconstruction and novel view synthesis, particularly for indoor and small-scale scenes. However, extending NeRF to large-scale outdoor environments presents challenges such as transient objects, sparse cameras and textures, and varying lighting conditions. In this paper, we propose a segmentation-guided enhancement to NeRF for outdoor street scenes, focusing on complex urban environments. Our approach extends ZipNeRF and utilizes Grounded SAM for segmentation mask generation, enabling effective handling of transient objects, modeling of the sky, and regularization of the ground. We also introduce appearance embeddings to adapt to inconsistent lighting across view sequences. Experimental results demonstrate that our method outperforms the baseline ZipNeRF, improving novel view synthesis quality with fewer artifacts and sharper details.
TDM: Temporally-Consistent Diffusion Model for All-in-One Real-World Video Restoration
Jan 04, 2025



In this paper, we propose the first diffusion-based all-in-one video restoration method that utilizes the power of a pre-trained Stable Diffusion and a fine-tuned ControlNet. Our method can restore various types of video degradation with a single unified model, overcoming the limitation of standard methods that require specific models for each restoration task. Our contributions include an efficient training strategy with Task Prompt Guidance (TPG) for diverse restoration tasks, an inference strategy that combines Denoising Diffusion Implicit Models~(DDIM) inversion with a novel Sliding Window Cross-Frame Attention (SW-CFA) mechanism for enhanced content preservation and temporal consistency, and a scalable pipeline that makes our method all-in-one to adapt to different video restoration tasks. Through extensive experiments on five video restoration tasks, we demonstrate the superiority of our method in generalization capability to real-world videos and temporal consistency preservation over existing state-of-the-art methods. Our method advances the video restoration task by providing a unified solution that enhances video quality across multiple applications.
Research on Dangerous Flight Weather Prediction based on Machine Learning
Jun 18, 2024
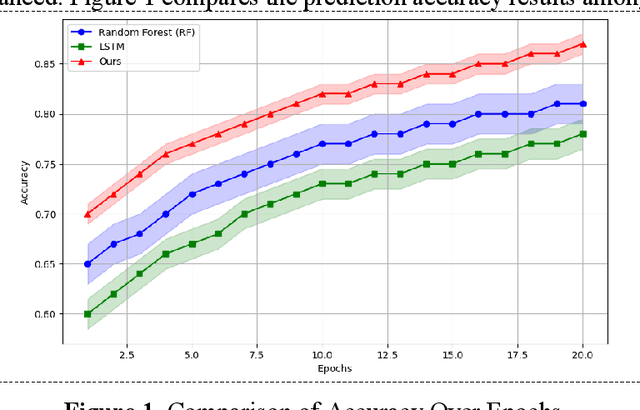
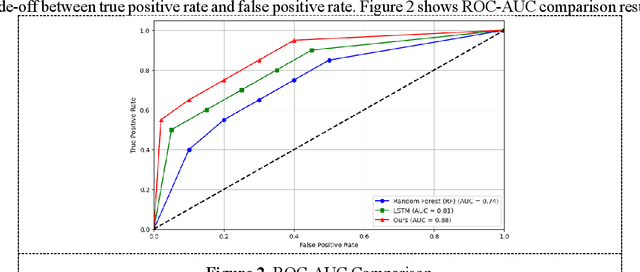
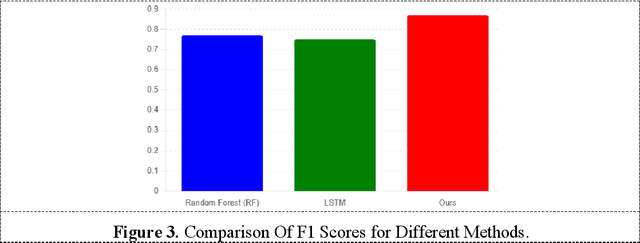
With the continuous expansion of the scale of air transport, the demand for aviation meteorological support also continues to grow. The impact of hazardous weather on flight safety is critical. How to effectively use meteorological data to improve the early warning capability of flight dangerous weather and ensure the safe flight of aircraft is the primary task of aviation meteorological services. In this work, support vector machine (SVM) models are used to predict hazardous flight weather, especially for meteorological conditions with high uncertainty such as storms and turbulence. SVM is a supervised learning method that distinguishes between different classes of data by finding optimal decision boundaries in a high-dimensional space. In order to meet the needs of this study, we chose the radial basis function (RBF) as the kernel function, which helps to deal with nonlinear problems and enables the model to better capture complex meteorological data structures. During the model training phase, we used historical meteorological observations from multiple weather stations, including temperature, humidity, wind speed, wind direction, and other meteorological indicators closely related to flight safety. From this data, the SVM model learns how to distinguish between normal and dangerous flight weather conditions.
Research on Tumors Segmentation based on Image Enhancement Method
Jun 07, 2024One of the most effective ways to treat liver cancer is to perform precise liver resection surgery, the key step of which includes precise digital image segmentation of the liver and its tumor. However, traditional liver parenchymal segmentation techniques often face several challenges in performing liver segmentation: lack of precision, slow processing speed, and computational burden. These shortcomings limit the efficiency of surgical planning and execution. In this work, the model initially describes in detail a new image enhancement algorithm that enhances the key features of an image by adaptively adjusting the contrast and brightness of the image. Then, a deep learning-based segmentation network was introduced, which was specially trained on the enhanced images to optimize the detection accuracy of tumor regions. In addition, multi-scale analysis techniques have been incorporated into the study, allowing the model to analyze images at different resolutions to capture more nuanced tumor features. In the presentation of the experimental results, the study used the 3Dircadb dataset to test the effectiveness of the proposed method. The experimental results show that compared with the traditional image segmentation method, the new method using image enhancement technology has significantly improved the accuracy and recall rate of tumor identification.
CFDNet: A Generalizable Foggy Stereo Matching Network with Contrastive Feature Distillation
Feb 29, 2024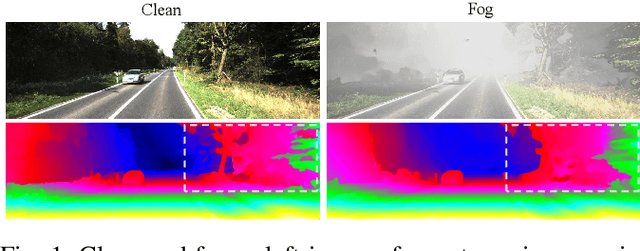
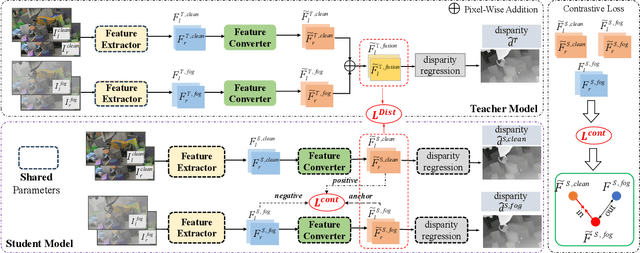
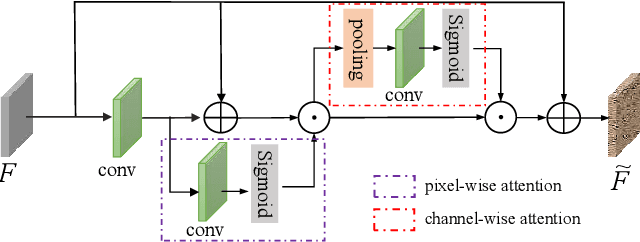
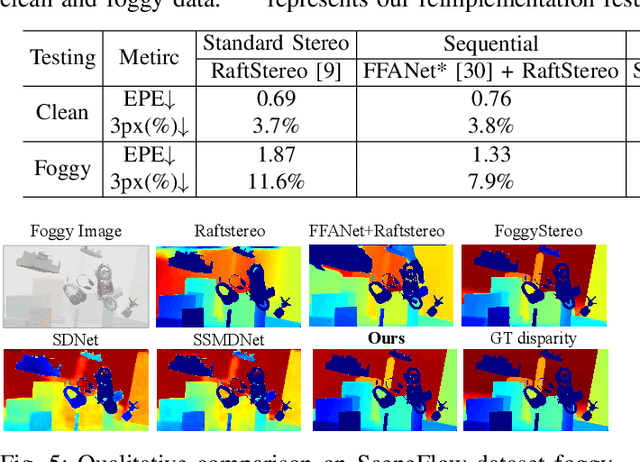
Stereo matching under foggy scenes remains a challenging task since the scattering effect degrades the visibility and results in less distinctive features for dense correspondence matching. While some previous learning-based methods integrated a physical scattering function for simultaneous stereo-matching and dehazing, simply removing fog might not aid depth estimation because the fog itself can provide crucial depth cues. In this work, we introduce a framework based on contrastive feature distillation (CFD). This strategy combines feature distillation from merged clean-fog features with contrastive learning, ensuring balanced dependence on fog depth hints and clean matching features. This framework helps to enhance model generalization across both clean and foggy environments. Comprehensive experiments on synthetic and real-world datasets affirm the superior strength and adaptability of our method.
Global Occlusion-Aware Transformer for Robust Stereo Matching
Dec 22, 2023Despite the remarkable progress facilitated by learning-based stereo-matching algorithms, the performance in the ill-conditioned regions, such as the occluded regions, remains a bottleneck. Due to the limited receptive field, existing CNN-based methods struggle to handle these ill-conditioned regions effectively. To address this issue, this paper introduces a novel attention-based stereo-matching network called Global Occlusion-Aware Transformer (GOAT) to exploit long-range dependency and occlusion-awareness global context for disparity estimation. In the GOAT architecture, a parallel disparity and occlusion estimation module PDO is proposed to estimate the initial disparity map and the occlusion mask using a parallel attention mechanism. To further enhance the disparity estimates in the occluded regions, an occlusion-aware global aggregation module (OGA) is proposed. This module aims to refine the disparity in the occluded regions by leveraging restricted global correlation within the focus scope of the occluded areas. Extensive experiments were conducted on several public benchmark datasets including SceneFlow, KITTI 2015, and Middlebury. The results show that the proposed GOAT demonstrates outstanding performance among all benchmarks, particularly in the occluded regions.
Fascinating Supervisory Signals and Where to Find Them: Deep Anomaly Detection with Scale Learning
May 25, 2023Due to the unsupervised nature of anomaly detection, the key to fueling deep models is finding supervisory signals. Different from current reconstruction-guided generative models and transformation-based contrastive models, we devise novel data-driven supervision for tabular data by introducing a characteristic -- scale -- as data labels. By representing varied sub-vectors of data instances, we define scale as the relationship between the dimensionality of original sub-vectors and that of representations. Scales serve as labels attached to transformed representations, thus offering ample labeled data for neural network training. This paper further proposes a scale learning-based anomaly detection method. Supervised by the learning objective of scale distribution alignment, our approach learns the ranking of representations converted from varied subspaces of each data instance. Through this proxy task, our approach models inherent regularities and patterns within data, which well describes data "normality". Abnormal degrees of testing instances are obtained by measuring whether they fit these learned patterns. Extensive experiments show that our approach leads to significant improvement over state-of-the-art generative/contrastive anomaly detection methods.
Dual-Pixel Raindrop Removal
Oct 24, 2022Removing raindrops in images has been addressed as a significant task for various computer vision applications. In this paper, we propose the first method using a Dual-Pixel (DP) sensor to better address the raindrop removal. Our key observation is that raindrops attached to a glass window yield noticeable disparities in DP's left-half and right-half images, while almost no disparity exists for in-focus backgrounds. Therefore, DP disparities can be utilized for robust raindrop detection. The DP disparities also brings the advantage that the occluded background regions by raindrops are shifted between the left-half and the right-half images. Therefore, fusing the information from the left-half and the right-half images can lead to more accurate background texture recovery. Based on the above motivation, we propose a DP Raindrop Removal Network (DPRRN) consisting of DP raindrop detection and DP fused raindrop removal. To efficiently generate a large amount of training data, we also propose a novel pipeline to add synthetic raindrops to real-world background DP images. Experimental results on synthetic and real-world datasets demonstrate that our DPRRN outperforms existing state-of-the-art methods, especially showing better robustness to real-world situations. Our source code and datasets are available at http://www.ok.sc.e.titech.ac.jp/res/SIR/.
Single Image Deraining Network with Rain Embedding Consistency and Layered LSTM
Nov 05, 2021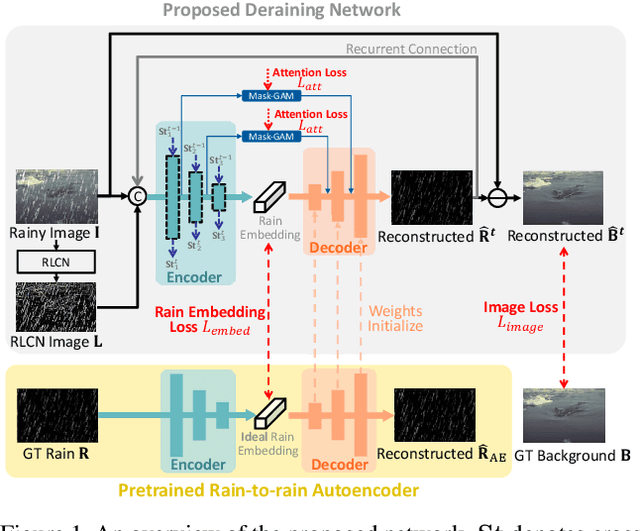

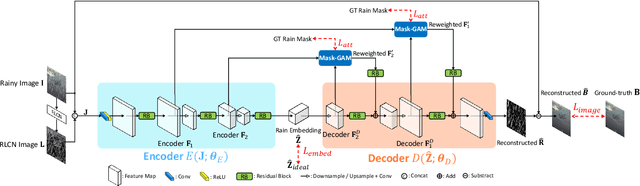

Single image deraining is typically addressed as residual learning to predict the rain layer from an input rainy image. For this purpose, an encoder-decoder network draws wide attention, where the encoder is required to encode a high-quality rain embedding which determines the performance of the subsequent decoding stage to reconstruct the rain layer. However, most of existing studies ignore the significance of rain embedding quality, thus leading to limited performance with over/under-deraining. In this paper, with our observation of the high rain layer reconstruction performance by an rain-to-rain autoencoder, we introduce the idea of "Rain Embedding Consistency" by regarding the encoded embedding by the autoencoder as an ideal rain embedding and aim at enhancing the deraining performance by improving the consistency between the ideal rain embedding and the rain embedding derived by the encoder of the deraining network. To achieve this, a Rain Embedding Loss is applied to directly supervise the encoding process, with a Rectified Local Contrast Normalization (RLCN) as the guide that effectively extracts the candidate rain pixels. We also propose Layered LSTM for recurrent deraining and fine-grained encoder feature refinement considering different scales. Qualitative and quantitative experiments demonstrate that our proposed method outperforms previous state-of-the-art methods particularly on a real-world dataset. Our source code is available at http://www.ok.sc.e.titech.ac.jp/res/SIR/.
Pyramid Scale Network for Crowd Counting
Jul 11, 2020



Crowd counting is a challenging task in computer vision due to serious occlusions, complex background and large scale variations, etc. Multi-column architecture is widely adopted to overcome these challenges, yielding state-of-the-art performance in many public benchmarks. However, there still are two issues in such design: scale limitation and feature similarity. Further performance improvements are thus restricted. In this paper, we propose a novel crowd counting framework called Pyramid Scale Network (PSNet) to explicitly address these issues. Specifically, for scale limitation, we adopt three Pyramid Scale Module (PSM) to efficiently capture multi-scale features, which integrate a message passing mechanism and an attention mechanism into multi-column architecture. Moreover, for feature similarity, a Differential loss is introduced to make the features learned by each column in PSM appropriately different from each other. To the best of our knowledge, PSNet is the first work to explicitly address scale limitation and feature similarity in multi-column design. Extensive experiments on five benchmark datasets demonstrate the effectiveness of the proposed innovations as well as the superior performance over the state-of-the-art. Our code is publicly available at: https://github.com/JunhaoCheng/Pyramid_Scale_Network