 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPACT: Influence Modeling for Open-Set Time Series Anomaly Detection
Mar 31, 2026Open-set anomaly detection (OSAD) is an emerging paradigm designed to utilize limited labeled data from anomaly classes seen in training to identify both seen and unseen anomalies during testing. Current approaches rely on simple augmentation methods to generate pseudo anomalies that replicate unseen anomalies. Despite being promising in image data, these methods are found to be ineffective in time series data due to the failure to preserve its sequential nature, resulting in trivial or unrealistic anomaly patterns. They are further plagued when the training data is contaminated with unlabeled anomalies. This work introduces $\textbf{IMPACT}$, a novel framework that leverages $\underline{\textbf{i}}$nfluence $\underline{\textbf{m}}$odeling for o$\underline{\textbf{p}}$en-set time series $\underline{\textbf{a}}$nomaly dete$\underline{\textbf{ct}}$ion, to tackle these challenges. The key insight is to $\textbf{i)}$ learn an influence function that can accurately estimate the impact of individual training samples on the modeling, and then $\textbf{ii)}$ leverage these influence scores to generate semantically divergent yet realistic unseen anomalies for time series while repurposing high-influential samples as supervised anomalies for anomaly decontamination. Extensive experiments show that IMPACT significantly outperforms existing state-of-the-art methods, showing superior accuracy under varying OSAD settings and contamination rates.
Angel or Devil: Discriminating Hard Samples and Anomaly Contaminations for Unsupervised Time Series Anomaly Detection
Oct 26, 2024



Training in unsupervised time series anomaly detection is constantly plagued by the discrimination between harmful `anomaly contaminations' and beneficial `hard normal samples'. These two samples exhibit analogous loss behavior that conventional loss-based methodologies struggle to differentiate. To tackle this problem, we propose a novel approach that supplements traditional loss behavior with `parameter behavior', enabling a more granular characterization of anomalous patterns. Parameter behavior is formalized by measuring the parametric response to minute perturbations in input samples. Leveraging the complementary nature of parameter and loss behaviors, we further propose a dual Parameter-Loss Data Augmentation method (termed PLDA), implemented within the reinforcement learning paradigm. During the training phase of anomaly detection, PLDA dynamically augments the training data through an iterative process that simultaneously mitigates anomaly contaminations while amplifying informative hard normal samples. PLDA demonstrates remarkable versatility, which can serve as an additional component that seamlessly integrated with existing anomaly detectors to enhance their detection performance. Extensive experiments on ten datasets show that PLDA significantly improves the performance of four distinct detectors by up to 8\%, outperforming three state-of-the-art data augmentation methods.
Abnormality Forecasting: Time Series Anomaly Prediction via Future Context Modeling
Oct 16, 2024Identifying anomalies from time series data plays an important role in various fields such as infrastructure security, intelligent operation and maintenance, and space exploration. Current research focuses on detecting the anomalies after they occur, which can lead to significant financial/reputation loss or infrastructure damage. In this work we instead study a more practical yet very challenging problem, time series anomaly prediction, aiming at providing early warnings for abnormal events before their occurrence. To tackle this problem, we introduce a novel principled approach, namely future context modeling (FCM). Its key insight is that the future abnormal events in a target window can be accurately predicted if their preceding observation window exhibits any subtle difference to normal data. To effectively capture such differences, FCM first leverages long-term forecasting models to generate a discriminative future context based on the observation data, aiming to amplify those subtle but unusual difference. It then models a normality correlation of the observation data with the forecasting future context to complement the normality modeling of the observation data in foreseeing possible abnormality in the target window. A joint variate-time attention learning is also introduced in FCM to leverage both temporal signals and features of the time series data for more discriminative normality modeling in the aforementioned two views. Comprehensive experiments on five datasets demonstrate that FCM gains good recall rate (70\%+) on multiple datasets and significantly outperforms all baselines in F1 score. Code is available at https://github.com/mala-lab/FCM.
Self-Supervised Spatial-Temporal Normality Learning for Time Series Anomaly Detection
Jun 28, 2024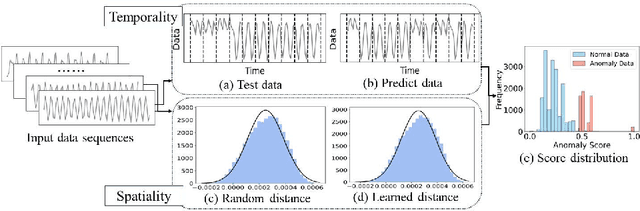
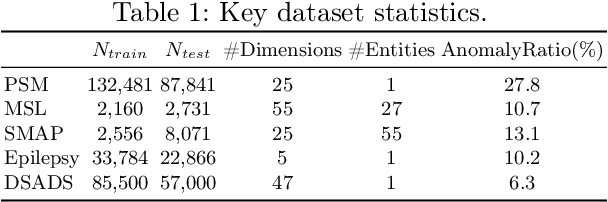
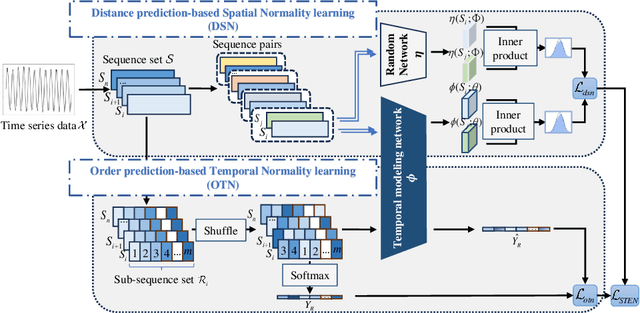
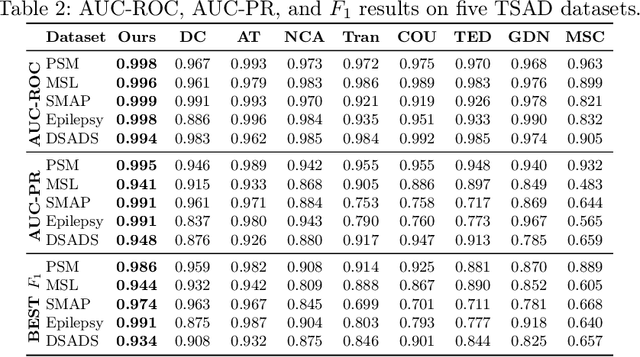
Time Series Anomaly Detection (TSAD) finds widespread applications across various domains such as financial markets, industrial production, and healthcare. Its primary objective is to learn the normal patterns of time series data, thereby identifying deviations in test samples. Most existing TSAD methods focus on modeling data from the temporal dimension, while ignoring the semantic information in the spatial dimension. To address this issue, we introduce a novel approach, called Spatial-Temporal Normality learning (STEN). STEN is composed of a sequence Order prediction-based Temporal Normality learning (OTN) module that captures the temporal correlations within sequences, and a Distance prediction-based Spatial Normality learning (DSN) module that learns the relative spatial relations between sequences in a feature space. By synthesizing these two modules, STEN learns expressive spatial-temporal representations for the normal patterns hidden in the time series data. Extensive experiments on five popular TSAD benchmarks show that STEN substantially outperforms state-of-the-art competing methods. Our code is available at https://github.com/mala-lab/STEN.
RoSAS: Deep Semi-Supervised Anomaly Detection with Contamination-Resilient Continuous Supervision
Jul 25, 2023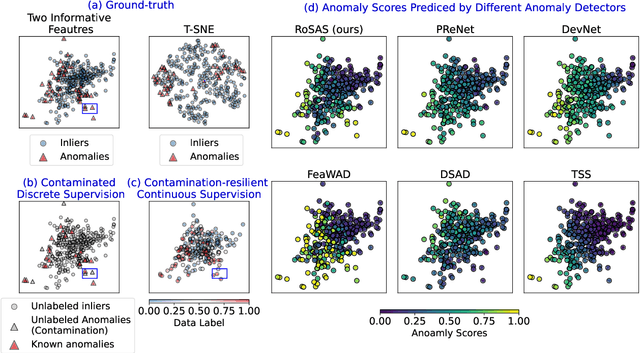

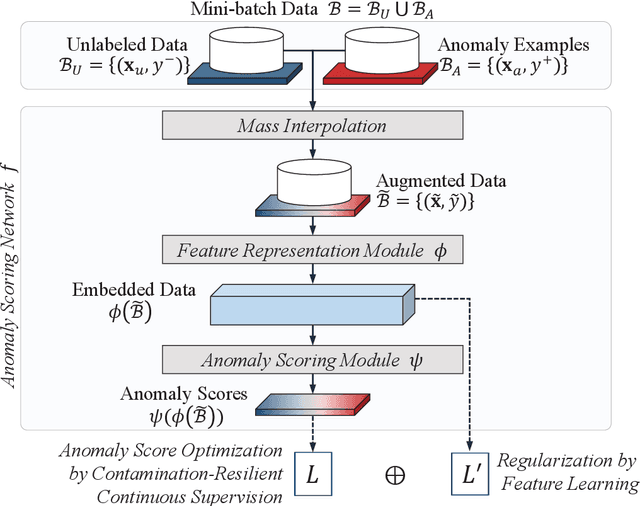
Semi-supervised anomaly detection methods leverage a few anomaly examples to yield drastically improved performance compared to unsupervised models. However, they still suffer from two limitations: 1) unlabeled anomalies (i.e., anomaly contamination) may mislead the learning process when all the unlabeled data are employed as inliers for model training; 2) only discrete supervision information (such as binary or ordinal data labels) is exploited, which leads to suboptimal learning of anomaly scores that essentially take on a continuous distribution. Therefore, this paper proposes a novel semi-supervised anomaly detection method, which devises \textit{contamination-resilient continuous supervisory signals}. Specifically, we propose a mass interpolation method to diffuse the abnormality of labeled anomalies, thereby creating new data samples labeled with continuous abnormal degrees. Meanwhile, the contaminated area can be covered by new data samples generated via combinations of data with correct labels. A feature learning-based objective is added to serve as an optimization constraint to regularize the network and further enhance the robustness w.r.t. anomaly contamination. Extensive experiments on 11 real-world datasets show that our approach significantly outperforms state-of-the-art competitors by 20%-30% in AUC-PR and obtains more robust and superior performance in settings with different anomaly contamination levels and varying numbers of labeled anomalies. The source code is available at https://github.com/xuhongzuo/rosas/.
Fascinating Supervisory Signals and Where to Find Them: Deep Anomaly Detection with Scale Learning
May 25, 2023



Due to the unsupervised nature of anomaly detection, the key to fueling deep models is finding supervisory signals. Different from current reconstruction-guided generative models and transformation-based contrastive models, we devise novel data-driven supervision for tabular data by introducing a characteristic -- scale -- as data labels. By representing varied sub-vectors of data instances, we define scale as the relationship between the dimensionality of original sub-vectors and that of representations. Scales serve as labels attached to transformed representations, thus offering ample labeled data for neural network training. This paper further proposes a scale learning-based anomaly detection method. Supervised by the learning objective of scale distribution alignment, our approach learns the ranking of representations converted from varied subspaces of each data instance. Through this proxy task, our approach models inherent regularities and patterns within data, which well describes data "normality". Abnormal degrees of testing instances are obtained by measuring whether they fit these learned patterns. Extensive experiments show that our approach leads to significant improvement over state-of-the-art generative/contrastive anomaly detection methods.
Calibrated One-class Classification for Unsupervised Time Series Anomaly Detection
Jul 25, 2022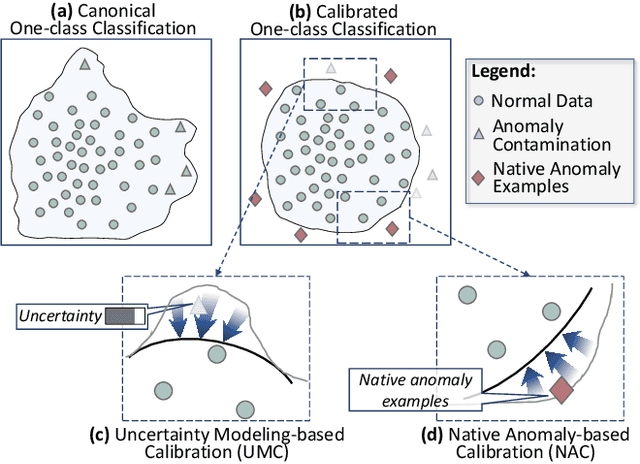
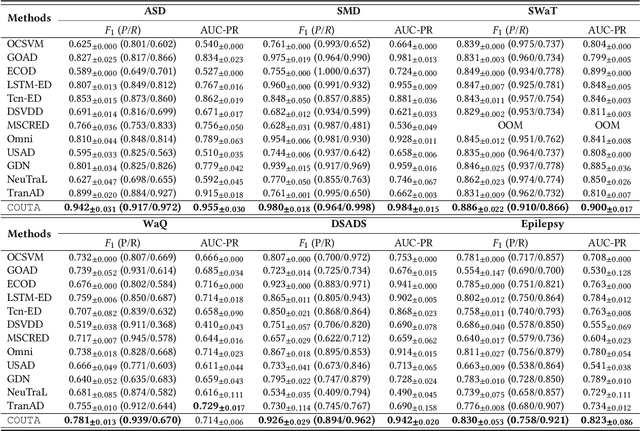
Unsupervised time series anomaly detection is instrumental in monitoring and alarming potential faults of target systems in various domains. Current state-of-the-art time series anomaly detectors mainly focus on devising advanced neural network structures and new reconstruction/prediction learning objectives to learn data normality (normal patterns and behaviors) as accurately as possible. However, these one-class learning methods can be deceived by unknown anomalies in the training data (i.e., anomaly contamination). Further, their normality learning also lacks knowledge about the anomalies of interest. Consequently, they often learn a biased, inaccurate normality boundary. This paper proposes a novel one-class learning approach, named calibrated one-class classification, to tackle this problem. Our one-class classifier is calibrated in two ways: (1) by adaptively penalizing uncertain predictions, which helps eliminate the impact of anomaly contamination while accentuating the predictions that the one-class model is confident in, and (2) by discriminating the normal samples from native anomaly examples that are generated to simulate genuine time series abnormal behaviors on the basis of original data. These two calibrations result in contamination-tolerant, anomaly-informed one-class learning, yielding a significantly improved normality modeling. Extensive experiments on six real-world datasets show that our model substantially outperforms twelve state-of-the-art competitors and obtains 6% - 31% F1 score improvement. The source code is available at \url{https://github.com/xuhongzuo/couta}.
Deep Isolation Forest for Anomaly Detection
Jun 14, 2022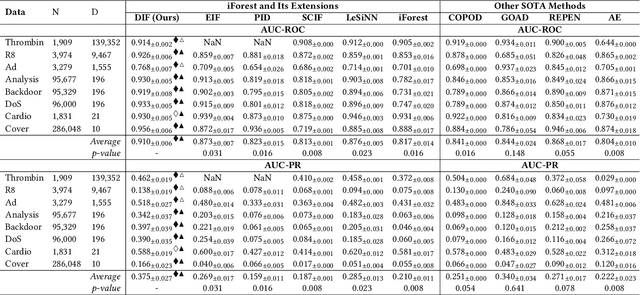
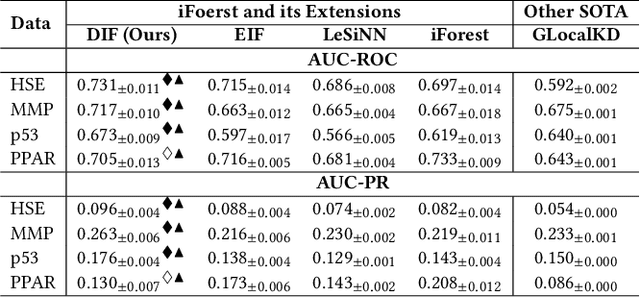
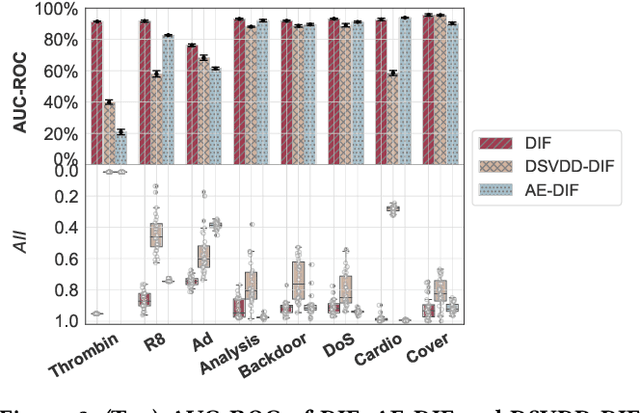
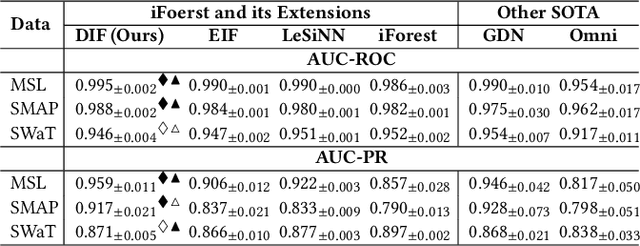
Isolation forest (iForest) has been emerging as arguably the most popular anomaly detector in recent years. It iteratively performs axis-parallel data space partition in a tree structure to isolate deviated data objects from the other data, with the isolation difficulty of the objects defined as anomaly scores. iForest shows effective performance across popular dataset benchmarks, but its axis-parallel-based linear data partition is ineffective in handling hard anomalies in high-dimensional/non-linear-separable data space, and even worse, it leads to a notorious algorithmic bias that assigns unexpectedly large anomaly scores to artefact regions. There have been several extensions of iForest, but they still focus on linear data partition, failing to effectively isolate those hard anomalies. This paper introduces a novel extension of iForest, deep isolation forest. Our method offers a comprehensive isolation method that can arbitrarily partition the data at any random direction and angle on subspaces of any size, effectively avoiding the algorithmic bias in the linear partition. Further, it requires only randomly initialised neural networks (i.e., no optimisation is required in our method) to ensure the freedom of the partition. In doing so, desired randomness and diversity in both random network-based representations and random partition-based isolation can be fully leveraged to significantly enhance the isolation ensemble-based anomaly detection. Also, our approach offers a data-type-agnostic anomaly detection solution. It is versatile to detect anomalies in different types of data by simply plugging in corresponding randomly initialised neural networks in the feature mapping. Extensive empirical results on a large collection of real-world datasets show that our model achieves substantial improvement over state-of-the-art isolation-based and non-isolation-based anomaly detection models.
DRAM Failure Prediction in AIOps: Empirical Evaluation, Challenges and Opportunities
May 04, 2021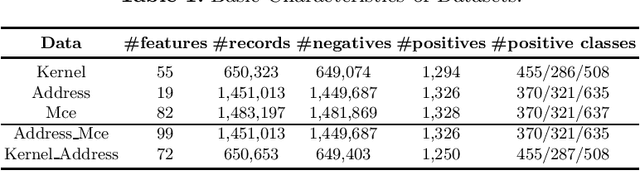
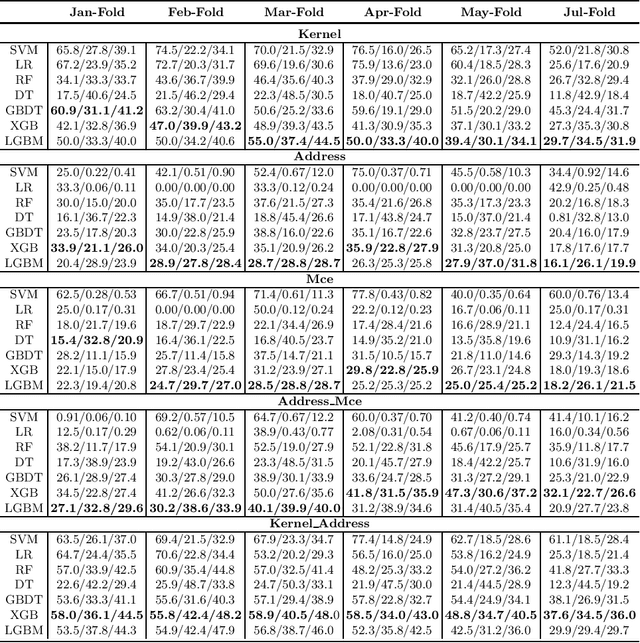
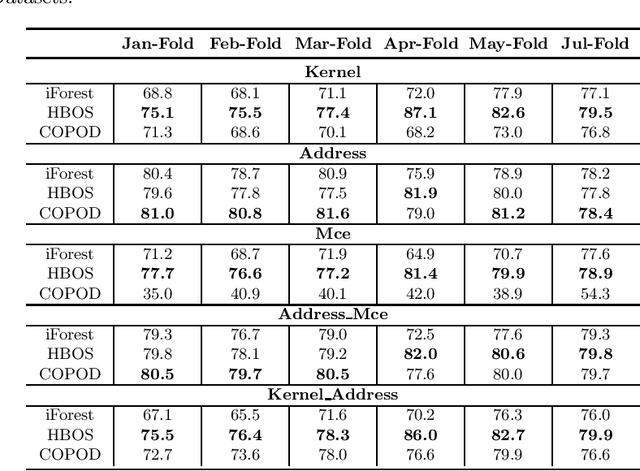
DRAM failure prediction is a vital task in AIOps, which is crucial to maintain the reliability and sustainable service of large-scale data centers. However, limited work has been done on DRAM failure prediction mainly due to the lack of public available datasets. This paper presents a comprehensive empirical evaluation of diverse machine learning techniques for DRAM failure prediction using a large-scale multi-source dataset, including more than three millions of records of kernel, address, and mcelog data, provided by Alibaba Cloud through PAKDD 2021 competition. Particularly, we first formulate the problem as a multi-class classification task and exhaustively evaluate seven popular/state-of-the-art classifiers on both the individual and multiple data sources. We then formulate the problem as an unsupervised anomaly detection task and evaluate three state-of-the-art anomaly detectors. Further, based on the empirical results and our experience of attending this competition, we discuss major challenges and present future research opportunities in this task.
Hierarchical Adaptive Pooling by Capturing High-order Dependency for Graph Representation Learning
Apr 13, 2021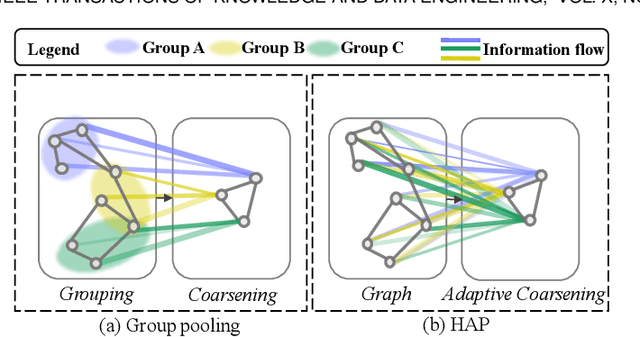
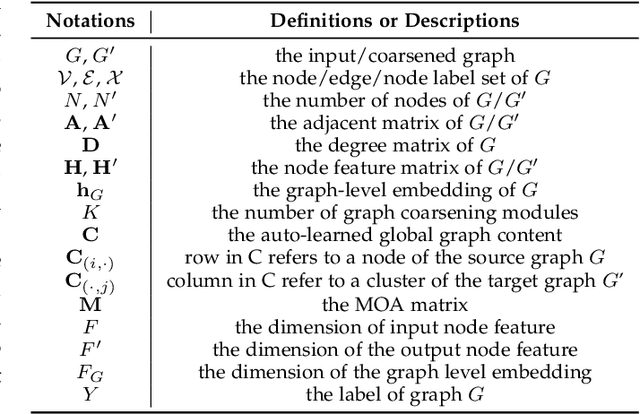
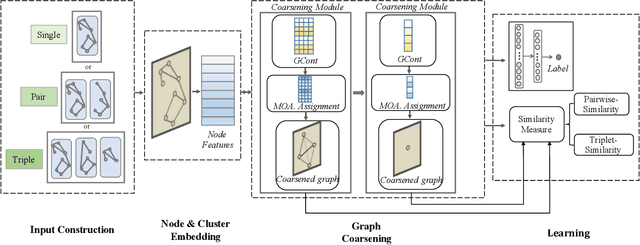
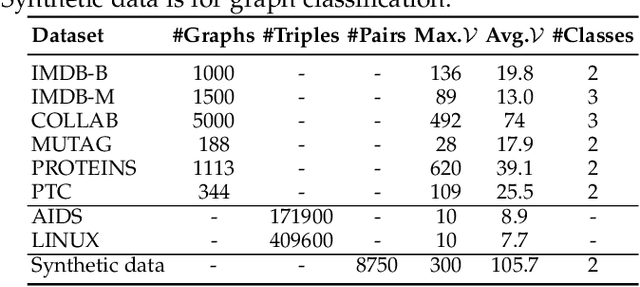
Graph neural networks (GNN) have been proven to be mature enough for handling graph-structured data on node-level graph representation learning tasks. However, the graph pooling technique for learning expressive graph-level representation is critical yet still challenging. Existing pooling methods either struggle to capture the local substructure or fail to effectively utilize high-order dependency, thus diminishing the expression capability. In this paper we propose HAP, a hierarchical graph-level representation learning framework, which is adaptively sensitive to graph structures, i.e., HAP clusters local substructures incorporating with high-order dependencies. HAP utilizes a novel cross-level attention mechanism MOA to naturally focus more on close neighborhood while effectively capture higher-order dependency that may contain crucial information. It also learns a global graph content GCont that extracts the graph pattern properties to make the pre- and post-coarsening graph content maintain stable, thus providing global guidance in graph coarsening. This novel innovation also facilitates generalization across graphs with the same form of features. Extensive experiments on fourteen datasets show that HAP significantly outperforms twelve popular graph pooling methods on graph classification task with an maximum accuracy improvement of 22.79%, and exceeds the performance of state-of-the-art graph matching and graph similarity learning algorithms by over 3.5% and 16.7%.