 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Semantic-Constrained Heterogeneous Graph for Audio-Visual Event Localization
Jun 05, 2026Open-vocabulary audio-visual event localization (OV-AVEL) jointly models audio-visual cues to recognize and temporally localize events, including categories unseen during training. Existing methods primarily learn joint audio-visual representations in Euclidean space, but still face two significant challenges. First, the lack of supervision signals for unseen categories makes it difficult to maintain audio-visual consistency across multiple temporal scales. Second, the lack of hierarchical constraints between segment- and video-level semantics prevents the model from establishing semantic consistency across different levels. To address these challenges, we propose a hierarchical semantic constrained heterogeneous graph (HSCHG) for audio-visual event localization framework. We first construct a heterogeneous hierarchical graph in Euclidean space, which includes audio and visual segment nodes and their corresponding video-level nodes. We use multi-directional temporal edges to capture complete temporal information within each modality. Simultaneously, we employ a dual-threshold filtering gated fusion strategy, introducing cross-modal information only when the alignment confidence is high. Furthermore, we introduce bidirectional semantic constraints between segment- and video-level representations to achieve semantic consistency across different levels. Based on this, we map the multi-level audio-visual representations and text prototypes uniformly into hyperbolic space. We use a hierarchical entailment regularization loss to characterize the hierarchical relationships between videos and segments. Extensive experimental results show that our method outperforms existing methods on the OV-AVEL benchmark. Ablation studies further validate the effectiveness of our method.
ScrollScape: Unlocking 32K Image Generation With Video Diffusion Priors
Mar 25, 2026While diffusion models excel at generating images with conventional dimensions, pushing them to synthesize ultra-high-resolution imagery at extreme aspect ratios (EAR) often triggers catastrophic structural failures, such as object repetition and spatial fragmentation.This limitation fundamentally stems from a lack of robust spatial priors, as static text-to-image models are primarily trained on image distributions with conventional dimensions.To overcome this bottleneck, we present ScrollScape, a novel framework that reformulates EAR image synthesis into a continuous video generation process through two core innovations.By mapping the spatial expansion of a massive canvas to the temporal evolution of video frames, ScrollScape leverages the inherent temporal consistency of video models as a powerful global constraint to ensure long-range structural integrity.Specifically, Scanning Positional Encoding (ScanPE) distributes global coordinates across frames to act as a flexible moving camera, while Scrolling Super-Resolution (ScrollSR) leverages video super-resolution priors to circumvent memory bottlenecks, efficiently scaling outputs to an unprecedented 32K resolution. Fine-tuned on a curated 3K multi-ratio image dataset, ScrollScape effectively aligns pre-trained video priors with the EAR generation task. Extensive evaluations demonstrate that it significantly outperforms existing image-diffusion baselines by eliminating severe localized artifacts. Consequently, our method overcomes inherent structural bottlenecks to ensure exceptional global coherence and visual fidelity across diverse domains at extreme scales.
BadLLM-TG: A Backdoor Defender powered by LLM Trigger Generator
Mar 16, 2026Backdoor attacks compromise model reliability by using triggers to manipulate outputs. Trigger inversion can accurately locate these triggers via a generator and is therefore critical for backdoor defense. However, the discrete nature of text prevents existing noise-based trigger generator from being applied to nature language processing (NLP). To overcome the limitations, we employ the rich knowledge embedded in large language models (LLMs) and propose a Backdoor defender powered by LLM Trigger Generator, termed BadLLM-TG. It is optimized through prompt-driven reinforcement learning, using the victim model's feedback loss as the reward signal. The generated triggers are then employed to mitigate the backdoor via adversarial training. Experiments show that our method reduces the attack success rate by 76.2\% on average, outperforming the second-best defender by 13.7.
FUSAR-GPT : A Spatiotemporal Feature-Embedded and Two-Stage Decoupled Visual Language Model for SAR Imagery
Feb 26, 2026Research on the intelligent interpretation of all-weather, all-time Synthetic Aperture Radar (SAR) is crucial for advancing remote sensing applications. In recent years, although Visual Language Models (VLMs) have demonstrated strong open-world understanding capabilities on RGB images, their performance is severely limited when directly applied to the SAR field due to the complexity of the imaging mechanism, sensitivity to scattering features, and the scarcity of high-quality text corpora. To systematically address this issue, we constructed the inaugural SAR Image-Text-AlphaEarth feature triplet dataset and developed FUSAR-GPT, a VLM specifically for SAR. FUSAR-GPT innovatively introduces a geospatial baseline model as a 'world knowledge' prior and embeds multi-source remote-sensing temporal features into the model's visual backbone via 'spatiotemporal anchors', enabling dynamic compensation for the sparse representation of targets in SAR images. Furthermore, we designed a two-stage SFT strategy to decouple the knowledge injection and task execution of large models. The spatiotemporal feature embedding and the two-stage decoupling paradigm enable FUSAR-GPT to achieve state-of-the-art performance across several typical remote sensing visual-language benchmark tests, significantly outperforming mainstream baseline models by over 12%.
Attonsecond Streaking Phase Retrieval Via Deep Learning Methods
May 06, 2025Attosecond streaking phase retrieval is essential for resolving electron dynamics on sub-femtosecond time scales yet traditional algorithms rely on iterative minimization and central momentum approximations that degrade accuracy for broadband pulses. In this work phase retrieval is reformulated as a supervised computer-vision problem and four neural architectures are systematically compared. A convolutional network demonstrates strong sensitivity to local streak edges but lacks global context; a vision transformer captures long-range delay-energy correlations at the expense of local inductive bias; a hybrid CNN-ViT model unites local feature extraction and full-graph attention; and a capsule network further enforces spatial pose agreement through dynamic routing. A theoretical analysis introduces local, global and positional sensitivity measures and derives surrogate error bounds that predict the strict ordering $CNN<ViT<Hybrid<Capsule$. Controlled experiments on synthetic streaking spectrograms confirm this hierarchy, with the capsule network achieving the highest retrieval fidelity. Looking forward, embedding the strong-field integral into physics-informed neural networks and exploring photonic hardware implementations promise pathways toward real-time attosecond pulse characterization under demanding experimental conditions.
Reciprocal Point Learning Network with Large Electromagnetic Kernel for SAR Open-Set Recognition
Nov 07, 2024



The limitations of existing Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) methods lie in their confinement by the closed-environment assumption, hindering their effective and robust handling of unknown target categories in open environments. Open Set Recognition (OSR), a pivotal facet for algorithmic practicality, intends to categorize known classes while denoting unknown ones as "unknown." The chief challenge in OSR involves concurrently mitigating risks associated with generalizing features from a restricted set of known classes to numerous unknown samples and the open space exposure to potential unknown data. To enhance open-set SAR classification, a method called scattering kernel with reciprocal learning network is proposed. Initially, a feature learning framework is constructed based on reciprocal point learning (RPL), establishing a bounded space for potential unknown classes. This approach indirectly introduces unknown information into a learner confined to known classes, thereby acquiring more concise and discriminative representations. Subsequently, considering the variability in the imaging of targets at different angles and the discreteness of components in SAR images, a proposal is made to design convolutional kernels based on large-sized attribute scattering center models. This enhances the ability to extract intrinsic non-linear features and specific scattering characteristics in SAR images, thereby improving the discriminative features of the model and mitigating the impact of imaging variations on classification performance. Experiments on the MSTAR datasets substantiate the superior performance of the proposed approach called ASC-RPL over mainstream methods.
Angel or Devil: Discriminating Hard Samples and Anomaly Contaminations for Unsupervised Time Series Anomaly Detection
Oct 26, 2024



Training in unsupervised time series anomaly detection is constantly plagued by the discrimination between harmful `anomaly contaminations' and beneficial `hard normal samples'. These two samples exhibit analogous loss behavior that conventional loss-based methodologies struggle to differentiate. To tackle this problem, we propose a novel approach that supplements traditional loss behavior with `parameter behavior', enabling a more granular characterization of anomalous patterns. Parameter behavior is formalized by measuring the parametric response to minute perturbations in input samples. Leveraging the complementary nature of parameter and loss behaviors, we further propose a dual Parameter-Loss Data Augmentation method (termed PLDA), implemented within the reinforcement learning paradigm. During the training phase of anomaly detection, PLDA dynamically augments the training data through an iterative process that simultaneously mitigates anomaly contaminations while amplifying informative hard normal samples. PLDA demonstrates remarkable versatility, which can serve as an additional component that seamlessly integrated with existing anomaly detectors to enhance their detection performance. Extensive experiments on ten datasets show that PLDA significantly improves the performance of four distinct detectors by up to 8\%, outperforming three state-of-the-art data augmentation methods.
Improving Ranking Correlation of Supernet with Candidates Enhancement and Progressive Training
Aug 12, 2021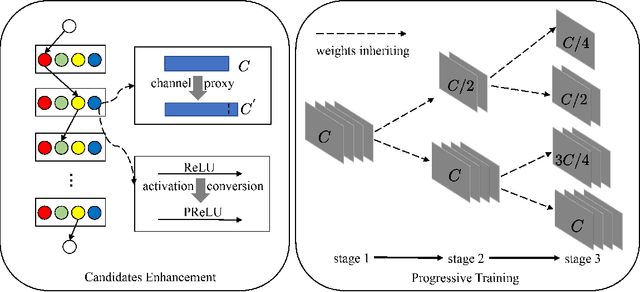
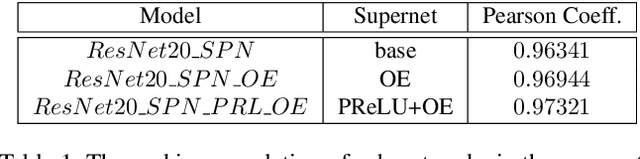
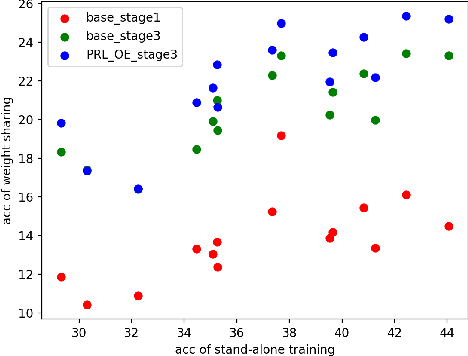
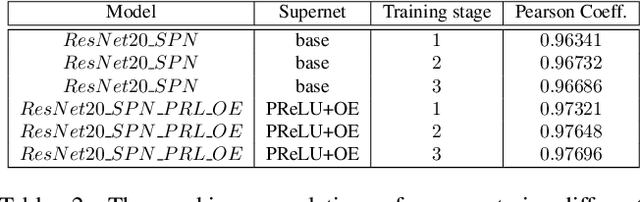
One-shot neural architecture search (NAS) applies weight-sharing supernet to reduce the unaffordable computation overhead of automated architecture designing. However, the weight-sharing technique worsens the ranking consistency of performance due to the interferences between different candidate networks. To address this issue, we propose a candidates enhancement method and progressive training pipeline to improve the ranking correlation of supernet. Specifically, we carefully redesign the sub-networks in the supernet and map the original supernet to a new one of high capacity. In addition, we gradually add narrow branches of supernet to reduce the degree of weight sharing which effectively alleviates the mutual interference between sub-networks. Finally, our method ranks the 1st place in the Supernet Track of CVPR2021 1st Lightweight NAS Challenge.
Cascade Bagging for Accuracy Prediction with Few Training Samples
Aug 12, 2021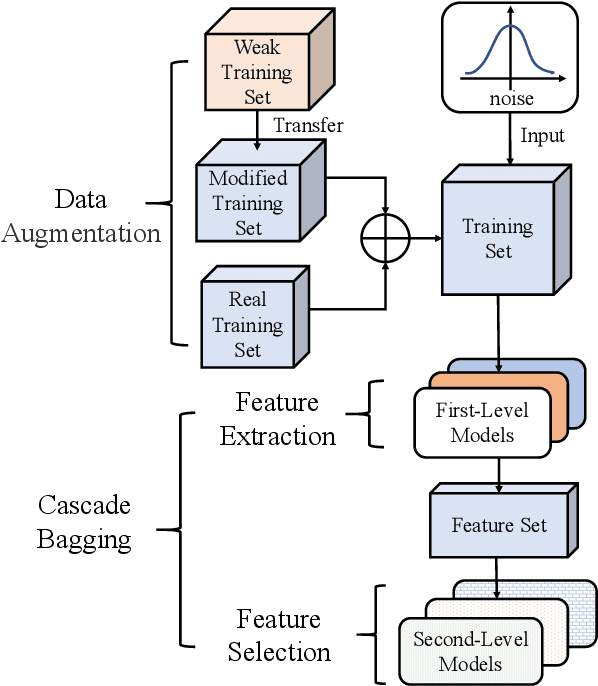
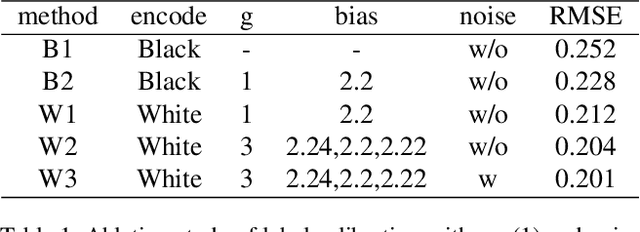
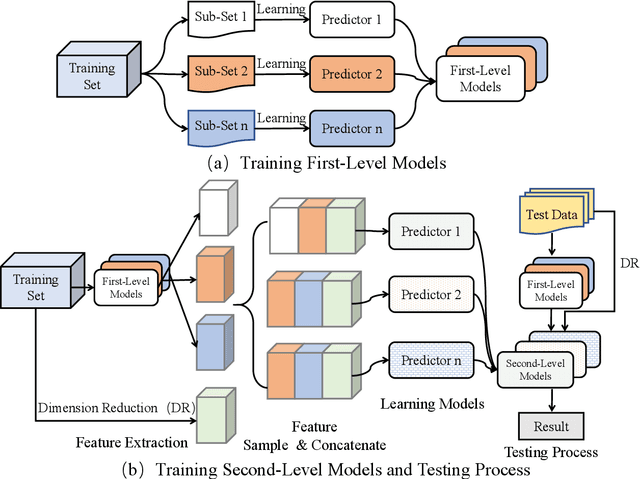

Accuracy predictor is trained to predict the validation accuracy of an network from its architecture encoding. It can effectively assist in designing networks and improving Neural Architecture Search(NAS) efficiency. However, a high-performance predictor depends on adequate trainning samples, which requires unaffordable computation overhead. To alleviate this problem, we propose a novel framework to train an accuracy predictor under few training samples. The framework consists ofdata augmentation methods and an ensemble learning algorithm. The data augmentation methods calibrate weak labels and inject noise to feature space. The ensemble learning algorithm, termed cascade bagging, trains two-level models by sampling data and features. In the end, the advantages of above methods are proved in the Performance Prediciton Track of CVPR2021 1st Lightweight NAS Challenge. Our code is made public at: https://github.com/dlongry/Solutionto-CVPR2021-NAS-Track2.