 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
AutoScape: Geometry-Consistent Long-Horizon Scene Generation
Oct 23, 2025This paper proposes AutoScape, a long-horizon driving scene generation framework. At its core is a novel RGB-D diffusion model that iteratively generates sparse, geometrically consistent keyframes, serving as reliable anchors for the scene's appearance and geometry. To maintain long-range geometric consistency, the model 1) jointly handles image and depth in a shared latent space, 2) explicitly conditions on the existing scene geometry (i.e., rendered point clouds) from previously generated keyframes, and 3) steers the sampling process with a warp-consistent guidance. Given high-quality RGB-D keyframes, a video diffusion model then interpolates between them to produce dense and coherent video frames. AutoScape generates realistic and geometrically consistent driving videos of over 20 seconds, improving the long-horizon FID and FVD scores over the prior state-of-the-art by 48.6\% and 43.0\%, respectively.
HiPhO: How Far Are (M)LLMs from Humans in the Latest High School Physics Olympiad Benchmark?
Sep 10, 2025

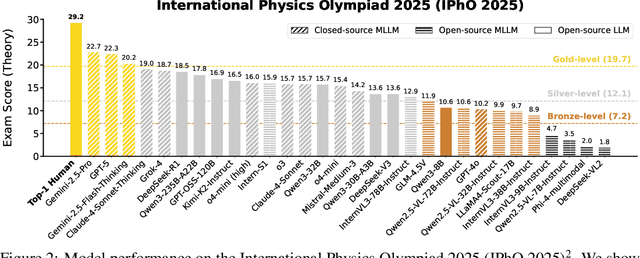

Recently, the physical capabilities of (M)LLMs have garnered increasing attention. However, existing benchmarks for physics suffer from two major gaps: they neither provide systematic and up-to-date coverage of real-world physics competitions such as physics Olympiads, nor enable direct performance comparison with humans. To bridge these gaps, we present HiPhO, the first benchmark dedicated to high school physics Olympiads with human-aligned evaluation. Specifically, HiPhO highlights three key innovations. (1) Comprehensive Data: It compiles 13 latest Olympiad exams from 2024-2025, spanning both international and regional competitions, and covering mixed modalities that encompass problems spanning text-only to diagram-based. (2) Professional Evaluation: We adopt official marking schemes to perform fine-grained grading at both the answer and step level, fully aligned with human examiners to ensure high-quality and domain-specific evaluation. (3) Comparison with Human Contestants: We assign gold, silver, and bronze medals to models based on official medal thresholds, thereby enabling direct comparison between (M)LLMs and human contestants. Our large-scale evaluation of 30 state-of-the-art (M)LLMs shows that: across 13 exams, open-source MLLMs mostly remain at or below the bronze level; open-source LLMs show promising progress with occasional golds; closed-source reasoning MLLMs can achieve 6 to 12 gold medals; and most models still have a significant gap from full marks. These results highlight a substantial performance gap between open-source models and top students, the strong physical reasoning capabilities of closed-source reasoning models, and the fact that there is still significant room for improvement. HiPhO, as a rigorous, human-aligned, and Olympiad-focused benchmark for advancing multimodal physical reasoning, is open-source and available at https://github.com/SciYu/HiPhO.
InternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling
Aug 12, 2025



Large language models (LLMs) have revolutionized artificial intelligence by enabling complex reasoning capabilities. While recent advancements in reinforcement learning (RL) have primarily focused on domain-specific reasoning tasks (e.g., mathematics or code generation), real-world reasoning scenarios often require models to handle diverse and complex environments that narrow-domain benchmarks cannot fully capture. To address this gap, we present InternBootcamp, an open-source framework comprising 1000+ domain-diverse task environments specifically designed for LLM reasoning research. Our codebase offers two key functionalities: (1) automated generation of unlimited training/testing cases with configurable difficulty levels, and (2) integrated verification modules for objective response evaluation. These features make InternBootcamp fundamental infrastructure for RL-based model optimization, synthetic data generation, and model evaluation. Although manually developing such a framework with enormous task coverage is extremely cumbersome, we accelerate the development procedure through an automated agent workflow supplemented by manual validation protocols, which enables the task scope to expand rapidly. % With these bootcamps, we further establish Bootcamp-EVAL, an automatically generated benchmark for comprehensive performance assessment. Evaluation reveals that frontier models still underperform in many reasoning tasks, while training with InternBootcamp provides an effective way to significantly improve performance, leading to our 32B model that achieves state-of-the-art results on Bootcamp-EVAL and excels on other established benchmarks. In particular, we validate that consistent performance gains come from including more training tasks, namely \textbf{task scaling}, over two orders of magnitude, offering a promising route towards capable reasoning generalist.
PairEdit: Learning Semantic Variations for Exemplar-based Image Editing
Jun 09, 2025Recent advancements in text-guided image editing have achieved notable success by leveraging natural language prompts for fine-grained semantic control. However, certain editing semantics are challenging to specify precisely using textual descriptions alone. A practical alternative involves learning editing semantics from paired source-target examples. Existing exemplar-based editing methods still rely on text prompts describing the change within paired examples or learning implicit text-based editing instructions. In this paper, we introduce PairEdit, a novel visual editing method designed to effectively learn complex editing semantics from a limited number of image pairs or even a single image pair, without using any textual guidance. We propose a target noise prediction that explicitly models semantic variations within paired images through a guidance direction term. Moreover, we introduce a content-preserving noise schedule to facilitate more effective semantic learning. We also propose optimizing distinct LoRAs to disentangle the learning of semantic variations from content. Extensive qualitative and quantitative evaluations demonstrate that PairEdit successfully learns intricate semantics while significantly improving content consistency compared to baseline methods. Code will be available at https://github.com/xudonmao/PairEdit.
Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning
Jun 04, 2025



Inspired by the remarkable reasoning capabilities of Deepseek-R1 in complex textual tasks, many works attempt to incentivize similar capabilities in Multimodal Large Language Models (MLLMs) by directly applying reinforcement learning (RL). However, they still struggle to activate complex reasoning. In this paper, rather than examining multimodal RL in isolation, we delve into current training pipelines and identify three crucial phenomena: 1) Effective cold start initialization is critical for enhancing MLLM reasoning. Intriguingly, we find that initializing with carefully selected text data alone can lead to performance surpassing many recent multimodal reasoning models, even before multimodal RL. 2) Standard GRPO applied to multimodal RL suffers from gradient stagnation, which degrades training stability and performance. 3) Subsequent text-only RL training, following the multimodal RL phase, further enhances multimodal reasoning. This staged training approach effectively balances perceptual grounding and cognitive reasoning development. By incorporating the above insights and addressing multimodal RL issues, we introduce ReVisual-R1, achieving a new state-of-the-art among open-source 7B MLLMs on challenging benchmarks including MathVerse, MathVision, WeMath, LogicVista, DynaMath, and challenging AIME2024 and AIME2025.
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
May 28, 2025



This paper aims to overcome a major obstacle in scaling RL for reasoning with LLMs, namely the collapse of policy entropy. Such phenomenon is consistently observed across vast RL runs without entropy intervention, where the policy entropy dropped sharply at the early training stage, this diminished exploratory ability is always accompanied with the saturation of policy performance. In practice, we establish a transformation equation R=-a*e^H+b between entropy H and downstream performance R. This empirical law strongly indicates that, the policy performance is traded from policy entropy, thus bottlenecked by its exhaustion, and the ceiling is fully predictable H=0, R=-a+b. Our finding necessitates entropy management for continuous exploration toward scaling compute for RL. To this end, we investigate entropy dynamics both theoretically and empirically. Our derivation highlights that, the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to its advantage when using Policy Gradient-like algorithms. Empirical study shows that, the values of covariance term and entropy differences matched exactly, supporting the theoretical conclusion. Moreover, the covariance term stays mostly positive throughout training, further explaining why policy entropy would decrease monotonically. Through understanding the mechanism behind entropy dynamics, we motivate to control entropy by restricting the update of high-covariance tokens. Specifically, we propose two simple yet effective techniques, namely Clip-Cov and KL-Cov, which clip and apply KL penalty to tokens with high covariances respectively. Experiments show that these methods encourage exploration, thus helping policy escape entropy collapse and achieve better downstream performance.
Safety2Drive: Safety-Critical Scenario Benchmark for the Evaluation of Autonomous Driving
May 20, 2025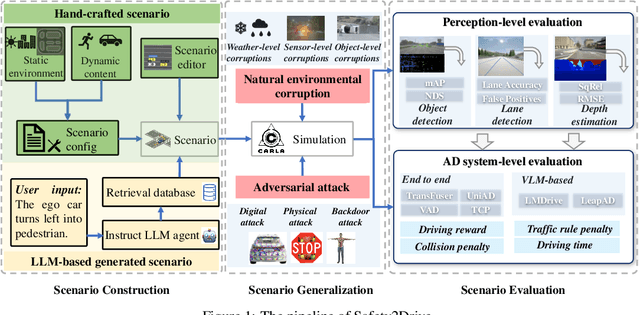

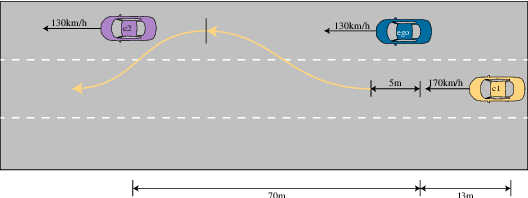
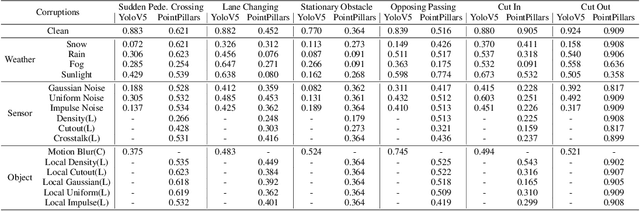
Autonomous Driving (AD) systems demand the high levels of safety assurance. Despite significant advancements in AD demonstrated on open-source benchmarks like Longest6 and Bench2Drive, existing datasets still lack regulatory-compliant scenario libraries for closed-loop testing to comprehensively evaluate the functional safety of AD. Meanwhile, real-world AD accidents are underrepresented in current driving datasets. This scarcity leads to inadequate evaluation of AD performance, posing risks to safety validation and practical deployment. To address these challenges, we propose Safety2Drive, a safety-critical scenario library designed to evaluate AD systems. Safety2Drive offers three key contributions. (1) Safety2Drive comprehensively covers the test items required by standard regulations and contains 70 AD function test items. (2) Safety2Drive supports the safety-critical scenario generalization. It has the ability to inject safety threats such as natural environment corruptions and adversarial attacks cross camera and LiDAR sensors. (3) Safety2Drive supports multi-dimensional evaluation. In addition to the evaluation of AD systems, it also supports the evaluation of various perception tasks, such as object detection and lane detection. Safety2Drive provides a paradigm from scenario construction to validation, establishing a standardized test framework for the safe deployment of AD.
Feedback-Free Resource Scheduling: Towards Flexible Multi-BS Cooperation in FD-RAN
Feb 25, 2025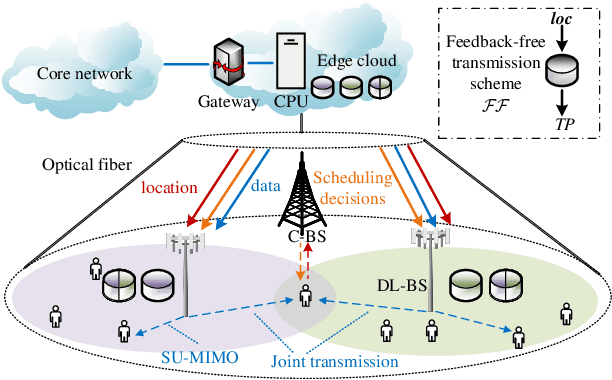
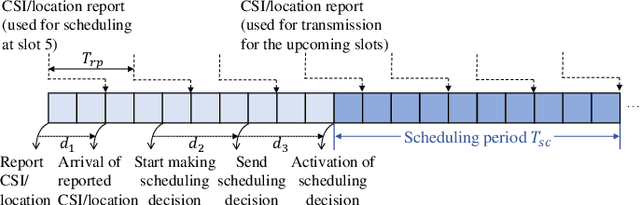
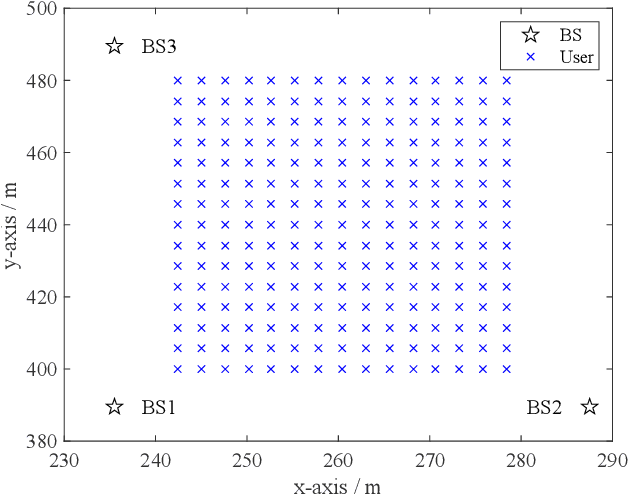
Flexible cooperation among base stations (BSs) is critical to improve resource utilization efficiency and meet personalized user demands. However, its practical implementation is hindered by the current radio access network (RAN), which relies on the coupling of uplink and downlink transmissions and channel state information feedback with inherent issues such as overheads and delays. To overcome these limitations, we consider the fully-decoupled RAN (FD-RAN), in which uplink and downlink networks are independent, and feedback-free MIMO transmission is adopted at the physical layer. To further deliver flexible cooperation in FD-RAN, we investigate the practical scheduling process and study feedback-free downlink multi-BS resource scheduling. The problem is considered based on network load conditions. In heavy-load states where it is impossible for all user demands to be met, an optimal greedy algorithm is proposed, maximizing the weighted sum of user demand satisfaction rates. In light-load states where at least one solution exists to satisfy all user demands, an optimal two-stage resource allocation algorithm is designed to further minimize network energy consumption by leveraging the flexibility of cooperation. Extensive simulations validate the superiority of proposed algorithms in performance and running time, and highlight the potential for realizing flexible cooperation in practice.
ConfigX: Modular Configuration for Evolutionary Algorithms via Multitask Reinforcement Learning
Dec 10, 2024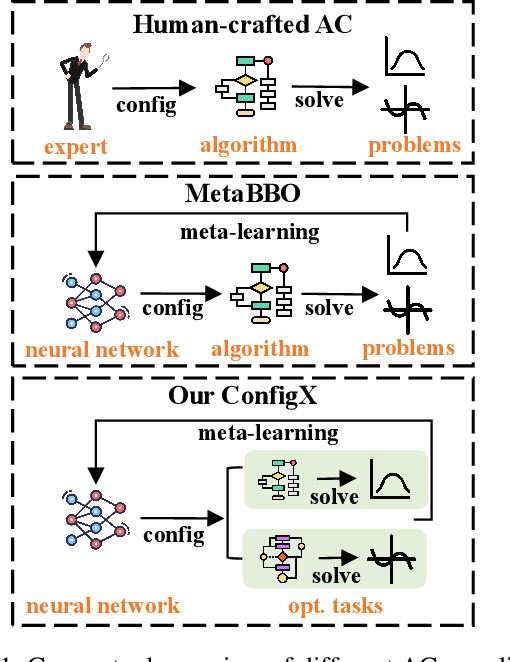
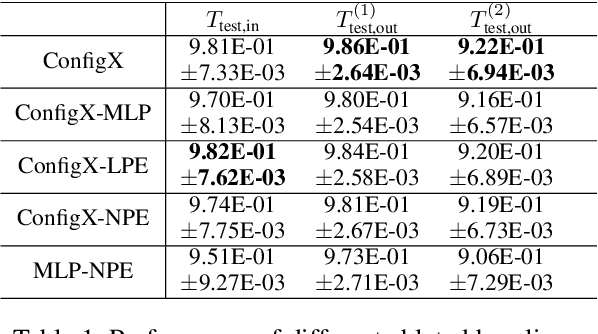
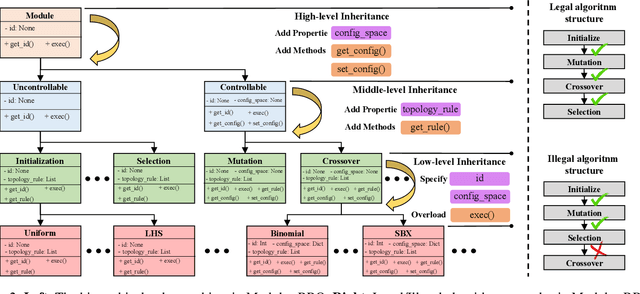
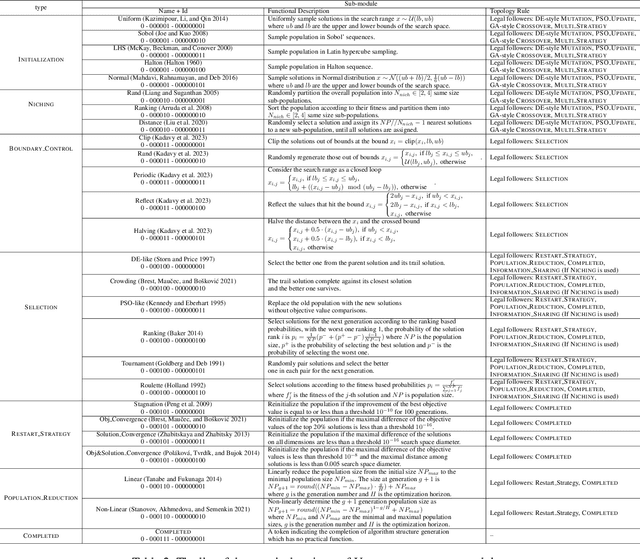
Recent advances in Meta-learning for Black-Box Optimization (MetaBBO) have shown the potential of using neural networks to dynamically configure evolutionary algorithms (EAs), enhancing their performance and adaptability across various BBO instances. However, they are often tailored to a specific EA, which limits their generalizability and necessitates retraining or redesigns for different EAs and optimization problems. To address this limitation, we introduce ConfigX, a new paradigm of the MetaBBO framework that is capable of learning a universal configuration agent (model) for boosting diverse EAs. To achieve so, our ConfigX first leverages a novel modularization system that enables the flexible combination of various optimization sub-modules to generate diverse EAs during training. Additionally, we propose a Transformer-based neural network to meta-learn a universal configuration policy through multitask reinforcement learning across a designed joint optimization task space. Extensive experiments verify that, our ConfigX, after large-scale pre-training, achieves robust zero-shot generalization to unseen tasks and outperforms state-of-the-art baselines. Moreover, ConfigX exhibits strong lifelong learning capabilities, allowing efficient adaptation to new tasks through fine-tuning. Our proposed ConfigX represents a significant step toward an automatic, all-purpose configuration agent for EAs.