 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-VLM: Hierarchical Vision Language Modeling for Report Generation
Feb 28, 2026Automated radiology report generation is key for reducing radiologist workload and improving diagnostic consistency, yet generating accurate reports for 3D medical imaging remains challenging. Existing vision-language models face two limitations: they do not leverage segmentation-pretrained encoders, and they inject visual features only at the input layer of language models, losing multi-scale information. We propose U-VLM, which enables hierarchical vision-language modeling in both training and architecture: (1) progressive training from segmentation to classification to report generation, and (2) multi-layer visual injection that routes U-Net encoder features to corresponding language model layers. Each training stage can leverage different datasets without unified annotations. U-VLM achieves state-of-the-art performance on CT-RATE (F1: 0.414 vs 0.258, BLEU-mean: 0.349 vs 0.305) and AbdomenAtlas 3.0 (F1: 0.624 vs 0.518 for segmentation-based detection) using only a 0.1B decoder trained from scratch, demonstrating that well-designed vision encoder pretraining outweighs the benefits of 7B+ pre-trained language models. Ablation studies show that progressive pretraining significantly improves F1, while multi-layer injection improves BLEU-mean. Code is available at https://github.com/yinghemedical/U-VLM.
Medal S: Spatio-Textual Prompt Model for Medical Segmentation
Nov 17, 2025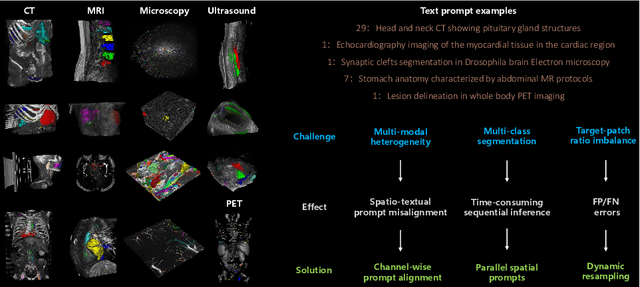
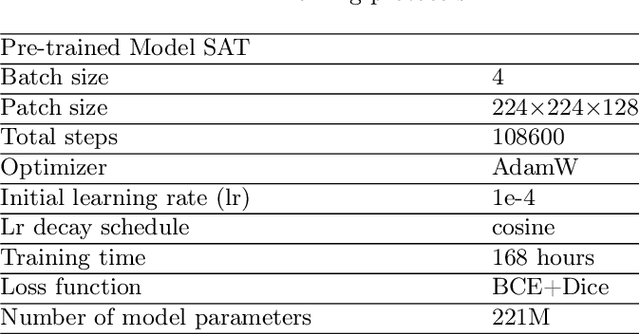
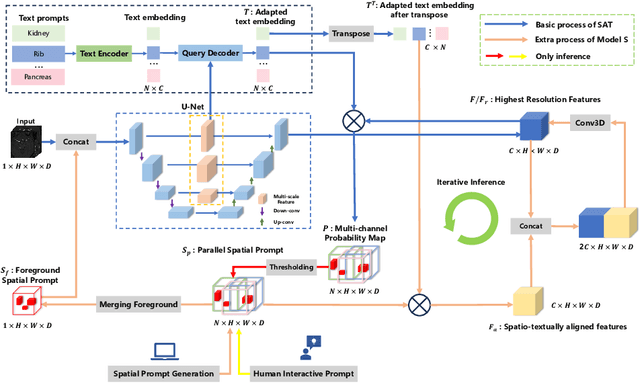
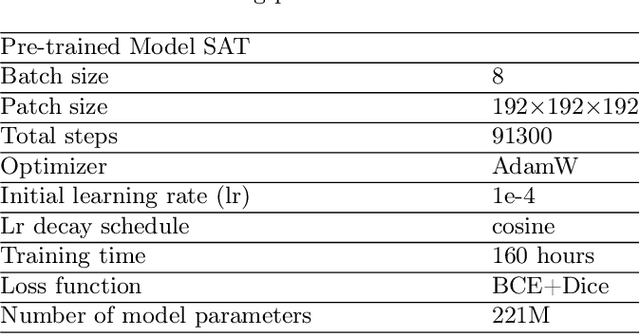
We introduce Medal S, a medical segmentation foundation model that supports native-resolution spatial and textual prompts within an end-to-end trainable framework. Unlike text-only methods lacking spatial awareness, Medal S achieves channel-wise alignment between volumetric prompts and text embeddings, mitigating inaccuracies from resolution mismatches. By preserving full 3D context, it efficiently processes multiple native-resolution masks in parallel, enhancing multi-class segmentation performance. A lightweight 3D convolutional module enables precise voxel-space refinement guided by both prompt types, supporting up to 243 classes across CT, MRI, PET, ultrasound, and microscopy modalities in the BiomedSegFM dataset. Medal S offers two prompting modes: a text-only mode, where model predictions serve as spatial prompts for self-refinement without human input, and a hybrid mode, incorporating manual annotations for enhanced flexibility. For 24-class segmentation, parallel spatial prompting reduces inference time by more than 90% compared to sequential prompting. We propose dynamic resampling to address target-patch ratio imbalance, extending SAT and nnU-Net for data augmentation. Furthermore, we develop optimized text preprocessing, a two-stage inference strategy, and post-processing techniques to improve memory efficiency, precision, and inference speed. On the five-modality average on the validation set, Medal S outperforms SAT with a DSC of 75.44 (vs. 69.83), NSD of 77.34 (vs. 71.06), F1 of 38.24 (vs. 24.88), and DSC TP of 65.46 (vs. 46.97). Medal S achieves excellent performance by harmonizing spatial precision with semantic textual guidance, demonstrating superior efficiency and accuracy in multi-class medical segmentation tasks compared to sequential prompt-based approaches. Medal S will be publicly available at https://github.com/yinghemedical/Medal-S.
DesignX: Human-Competitive Algorithm Designer for Black-Box Optimization
May 23, 2025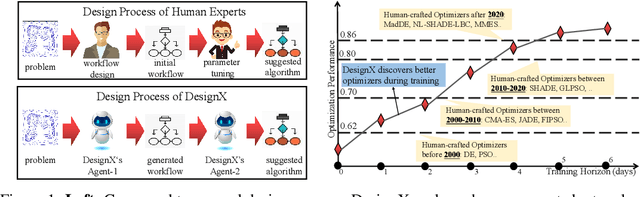
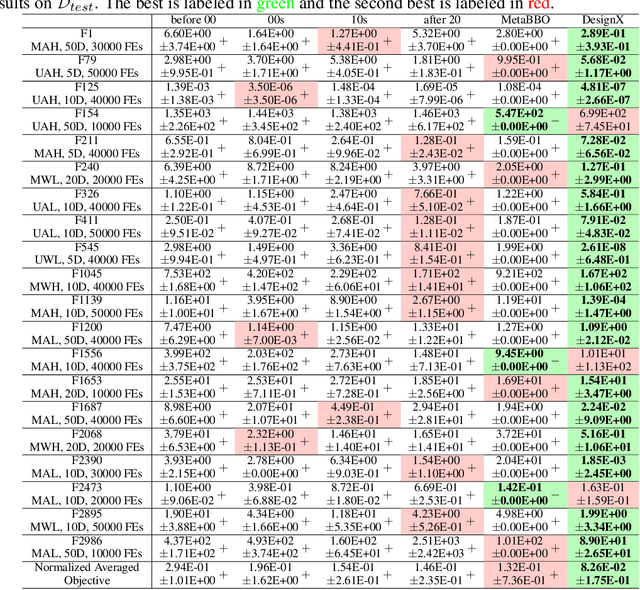
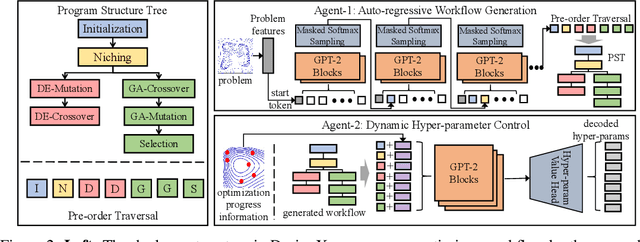
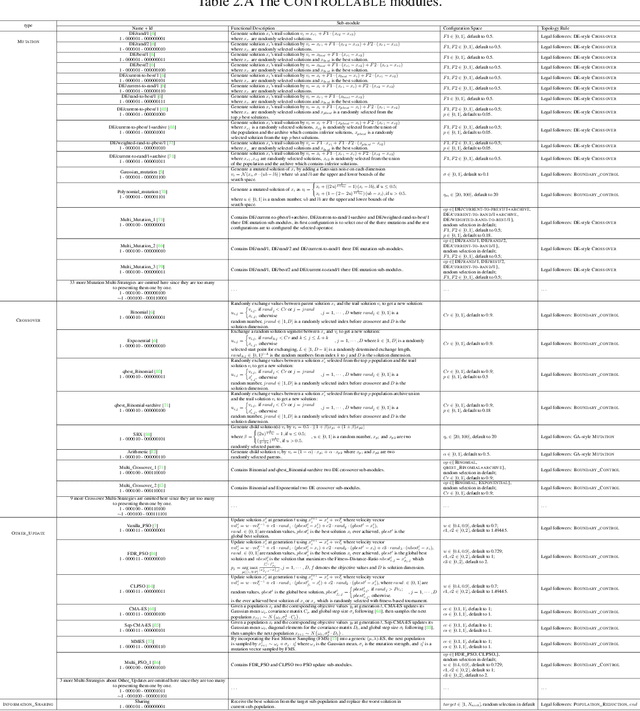
Designing effective black-box optimizers is hampered by limited problem-specific knowledge and manual control that spans months for almost every detail. In this paper, we present DesignX, the first automated algorithm design framework that generates an effective optimizer specific to a given black-box optimization problem within seconds. Rooted in the first principles, we identify two key sub-tasks: 1) algorithm structure generation and 2) hyperparameter control. To enable systematic construction, a comprehensive modular algorithmic space is first built, embracing hundreds of algorithm components collected from decades of research. We then introduce a dual-agent reinforcement learning system that collaborates on structural and parametric design through a novel cooperative training objective, enabling large-scale meta-training across 10k diverse instances. Remarkably, through days of autonomous learning, the DesignX-generated optimizers continuously surpass human-crafted optimizers by orders of magnitude, either on synthetic testbed or on realistic optimization scenarios such as Protein-docking, AutoML and UAV path planning. Further in-depth analysis reveals DesignX's capability to discover non-trivial algorithm patterns beyond expert intuition, which, conversely, provides valuable design insights for the optimization community. We provide DesignX's inference code at https://github.com/MetaEvo/DesignX.
Advancing CMA-ES with Learning-Based Cooperative Coevolution for Scalable Optimization
Apr 24, 2025Recent research in Cooperative Coevolution~(CC) have achieved promising progress in solving large-scale global optimization problems. However, existing CC paradigms have a primary limitation in that they require deep expertise for selecting or designing effective variable decomposition strategies. Inspired by advancements in Meta-Black-Box Optimization, this paper introduces LCC, a pioneering learning-based cooperative coevolution framework that dynamically schedules decomposition strategies during optimization processes. The decomposition strategy selector is parameterized through a neural network, which processes a meticulously crafted set of optimization status features to determine the optimal strategy for each optimization step. The network is trained via the Proximal Policy Optimization method in a reinforcement learning manner across a collection of representative problems, aiming to maximize the expected optimization performance. Extensive experimental results demonstrate that LCC not only offers certain advantages over state-of-the-art baselines in terms of optimization effectiveness and resource consumption, but it also exhibits promising transferability towards unseen problems.
Addressing Domain Shift via Imbalance-Aware Domain Adaptation in Embryo Development Assessment
Jan 09, 2025Deep learning models in medical imaging face dual challenges: domain shift, where models perform poorly when deployed in settings different from their training environment, and class imbalance, where certain disease conditions are naturally underrepresented. We present Imbalance-Aware Domain Adaptation (IADA), a novel framework that simultaneously tackles both challenges through three key components: (1) adaptive feature learning with class-specific attention mechanisms, (2) balanced domain alignment with dynamic weighting, and (3) adaptive threshold optimization. Our theoretical analysis establishes convergence guarantees and complexity bounds. Through extensive experiments on embryo development assessment across four imaging modalities, IADA demonstrates significant improvements over existing methods, achieving up to 25.19\% higher accuracy while maintaining balanced performance across classes. In challenging scenarios with low-quality imaging systems, IADA shows robust generalization with AUC improvements of up to 12.56\%. These results demonstrate IADA's potential for developing reliable and equitable medical imaging systems for diverse clinical settings. The code is made public available at \url{https://github.com/yinghemedical/imbalance-aware_domain_adaptation}
ConfigX: Modular Configuration for Evolutionary Algorithms via Multitask Reinforcement Learning
Dec 10, 2024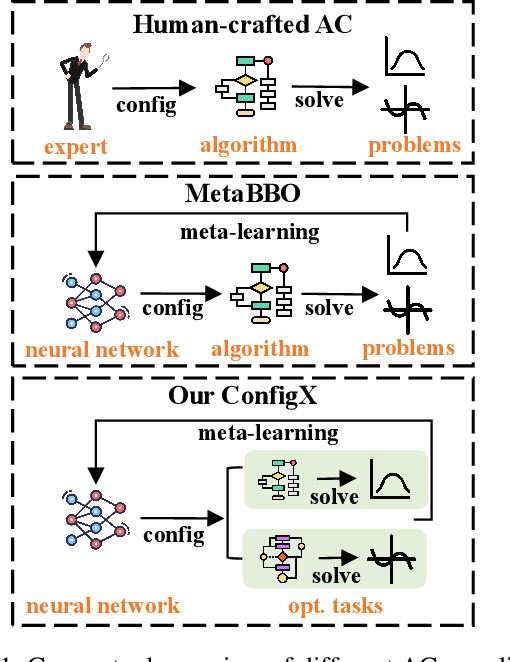
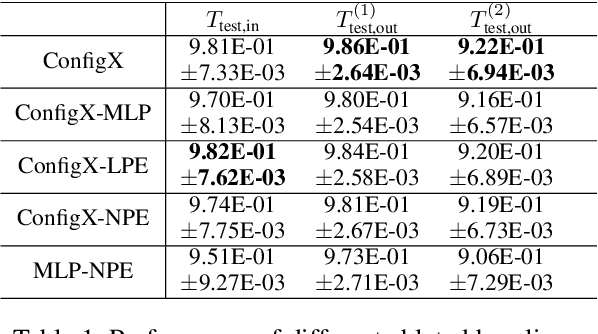
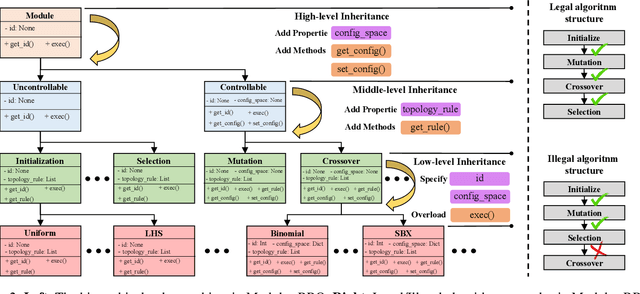
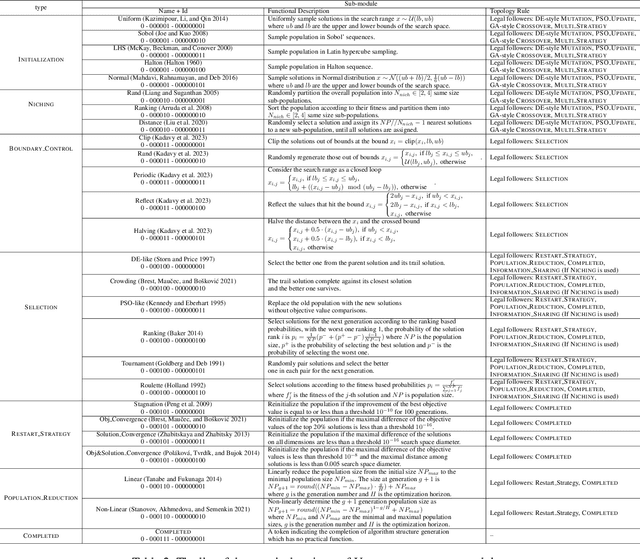
Recent advances in Meta-learning for Black-Box Optimization (MetaBBO) have shown the potential of using neural networks to dynamically configure evolutionary algorithms (EAs), enhancing their performance and adaptability across various BBO instances. However, they are often tailored to a specific EA, which limits their generalizability and necessitates retraining or redesigns for different EAs and optimization problems. To address this limitation, we introduce ConfigX, a new paradigm of the MetaBBO framework that is capable of learning a universal configuration agent (model) for boosting diverse EAs. To achieve so, our ConfigX first leverages a novel modularization system that enables the flexible combination of various optimization sub-modules to generate diverse EAs during training. Additionally, we propose a Transformer-based neural network to meta-learn a universal configuration policy through multitask reinforcement learning across a designed joint optimization task space. Extensive experiments verify that, our ConfigX, after large-scale pre-training, achieves robust zero-shot generalization to unseen tasks and outperforms state-of-the-art baselines. Moreover, ConfigX exhibits strong lifelong learning capabilities, allowing efficient adaptation to new tasks through fine-tuning. Our proposed ConfigX represents a significant step toward an automatic, all-purpose configuration agent for EAs.
LArctan-SKAN: Simple and Efficient Single-Parameterized Kolmogorov-Arnold Networks using Learnable Trigonometric Function
Oct 25, 2024



This paper proposes a novel approach for designing Single-Parameterized Kolmogorov-Arnold Networks (SKAN) by utilizing a Single-Parameterized Function (SFunc) constructed from trigonometric functions. Three new SKAN variants are developed: LSin-SKAN, LCos-SKAN, and LArctan-SKAN. Experimental validation on the MNIST dataset demonstrates that LArctan-SKAN excels in both accuracy and computational efficiency. Specifically, LArctan-SKAN significantly improves test set accuracy over existing models, outperforming all pure KAN variants compared, including FourierKAN, LSS-SKAN, and Spl-KAN. It also surpasses mixed MLP-based models such as MLP+rKAN and MLP+fKAN in accuracy. Furthermore, LArctan-SKAN exhibits remarkable computational efficiency, with a training speed increase of 535.01% and 49.55% compared to MLP+rKAN and MLP+fKAN, respectively. These results confirm the effectiveness and potential of SKANs constructed with trigonometric functions. The experiment code is available at https://github.com/chikkkit/LArctan-SKAN .
LSS-SKAN: Efficient Kolmogorov-Arnold Networks based on Single-Parameterized Function
Oct 19, 2024



The recently proposed Kolmogorov-Arnold Networks (KAN) networks have attracted increasing attention due to their advantage of high visualizability compared to MLP. In this paper, based on a series of small-scale experiments, we proposed the Efficient KAN Expansion Principle (EKE Principle): allocating parameters to expand network scale, rather than employing more complex basis functions, leads to more efficient performance improvements in KANs. Based on this principle, we proposed a superior KAN termed SKAN, where the basis function utilizes only a single learnable parameter. We then evaluated various single-parameterized functions for constructing SKANs, with LShifted Softplus-based SKANs (LSS-SKANs) demonstrating superior accuracy. Subsequently, extensive experiments were performed, comparing LSS-SKAN with other KAN variants on the MNIST dataset. In the final accuracy tests, LSS-SKAN exhibited superior performance on the MNIST dataset compared to all tested pure KAN variants. Regarding execution speed, LSS-SKAN outperformed all compared popular KAN variants. Our experimental codes are available at https://github.com/chikkkit/LSS-SKAN and SKAN's Python library (for quick construction of SKAN in python) codes are available at https://github.com/chikkkit/SKAN .
Deep Reinforcement Learning for Dynamic Algorithm Selection: A Proof-of-Principle Study on Differential Evolution
Mar 07, 2024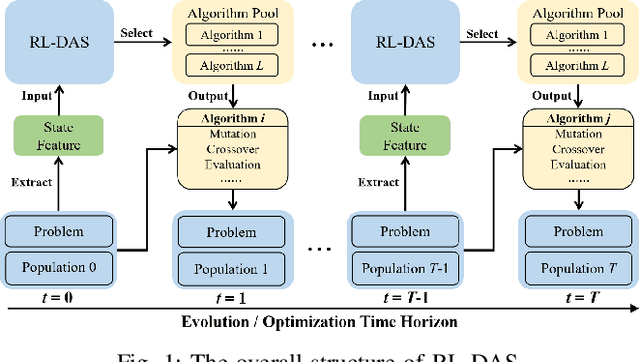
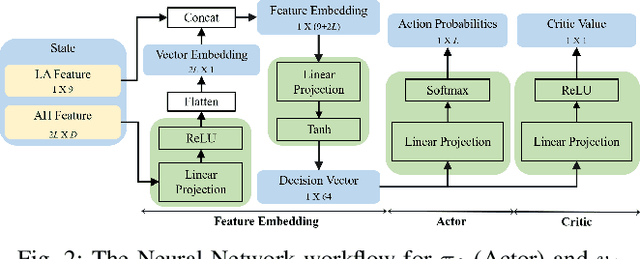
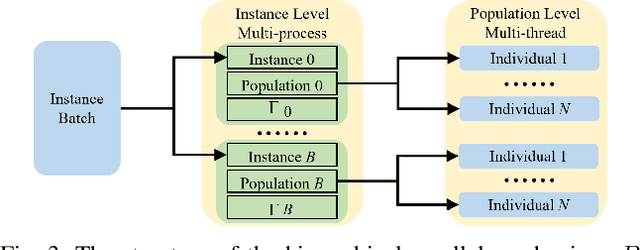
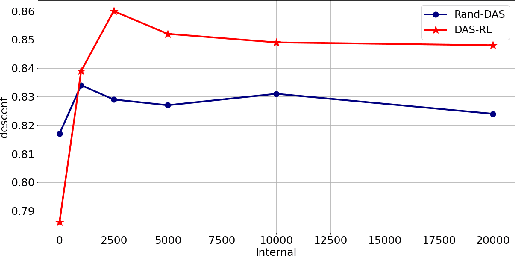
Evolutionary algorithms, such as Differential Evolution, excel in solving real-parameter optimization challenges. However, the effectiveness of a single algorithm varies across different problem instances, necessitating considerable efforts in algorithm selection or configuration. This paper aims to address the limitation by leveraging the complementary strengths of a group of algorithms and dynamically scheduling them throughout the optimization progress for specific problems. We propose a deep reinforcement learning-based dynamic algorithm selection framework to accomplish this task. Our approach models the dynamic algorithm selection a Markov Decision Process, training an agent in a policy gradient manner to select the most suitable algorithm according to the features observed during the optimization process. To empower the agent with the necessary information, our framework incorporates a thoughtful design of landscape and algorithmic features. Meanwhile, we employ a sophisticated deep neural network model to infer the optimal action, ensuring informed algorithm selections. Additionally, an algorithm context restoration mechanism is embedded to facilitate smooth switching among different algorithms. These mechanisms together enable our framework to seamlessly select and switch algorithms in a dynamic online fashion. Notably, the proposed framework is simple and generic, offering potential improvements across a broad spectrum of evolutionary algorithms. As a proof-of-principle study, we apply this framework to a group of Differential Evolution algorithms. The experimental results showcase the remarkable effectiveness of the proposed framework, not only enhancing the overall optimization performance but also demonstrating favorable generalization ability across different problem classes.
MedFLIP: Medical Vision-and-Language Self-supervised Fast Pre-Training with Masked Autoencoder
Mar 07, 2024Within the domain of medical analysis, extensive research has explored the potential of mutual learning between Masked Autoencoders(MAEs) and multimodal data. However, the impact of MAEs on intermodality remains a key challenge. We introduce MedFLIP, a Fast Language-Image Pre-training method for Medical analysis. We explore MAEs for zero-shot learning with crossed domains, which enhances the model ability to learn from limited data, a common scenario in medical diagnostics. We verify that masking an image does not affect intermodal learning. Furthermore, we propose the SVD loss to enhance the representation learning for characteristics of medical images, aiming to improve classification accuracy by leveraging the structural intricacies of such data. Lastly, we validate using language will improve the zero-shot performance for the medical image analysis. MedFLIP scaling of the masking process marks an advancement in the field, offering a pathway to rapid and precise medical image analysis without the traditional computational bottlenecks. Through experiments and validation, MedFLIP demonstrates efficient performance improvements, setting an explored standard for future research and application in medical diagnostics.